什么是世界模型
从 Ha 与 Schmidhuber 的 V-M-C 架构,到 Genie、V-JEPA、PAN 和 NVIDIA 的物理 AI 视角,梳理世界模型的定义、公式、路线和边界。
世界模型的核心不是“生成一段看起来合理的视频”,而是在内部模拟世界会如何变化。更具体地说,它要回答一个行动问题:如果当前世界是这样,我做出某个动作,接下来会发生什么?
这里的 \(s_t\) 是当前状态,\(a_t\) 是动作,\(s_{t+1}\) 是动作之后的下一状态。这个公式比“预测未来”多了一个关键条件:动作。没有动作条件,模型只是预测接下来可能出现的画面;有了动作条件,模型才开始支持“如果我这样做,会怎样”的反事实推演。

定义与边界
“世界模型”这个词有两个常见用法。
在宽泛意义上,只要模型能根据已有信息预测接下来会发生什么,就可以被称为世界模型:
语言模型预测下一个 token,视频模型预测下一帧,天气模型预测明天的气温,都属于这种预测型模型。这个用法适合讨论“内部表征”,但范围很宽,容易把不同问题混在一起。
在强化学习、机器人和控制语境里,世界模型通常指更窄的一类:它必须建模动作如何改变世界。
如果状态不可直接观测,常见做法是先把观测压成 latent state:
这里的 \(E_{\phi}\) 是编码器,\(p_{\theta}\) 是潜在动力学模型,\(D_{\psi}\) 是可选的解码器。解码器可以把 latent 还原成图像,但不是世界模型的必要条件;关键在于中间的动作条件转移。
边界判断
因此,判断一个系统是不是狭义世界模型,重点不是它能不能生成内容,而是它是否显式建模“动作之后世界如何变化”。
| 模型类型 | 典型公式 | 判断 | 原因 |
|---|---|---|---|
| 图像分类器 / 目标检测器 | \(p(y \mid x)\) | 不是 | 只识别当前输入,不预测动作后的变化。 |
| 纯策略模型 | \(\pi(a_t \mid s_t)\) | 不是 | 直接选动作,但不模拟世界转移。 |
| 价值函数 / 奖励模型 | \(V(s_t)\) 或 \(Q(s_t, a_t)\) | 不是 | 评估好坏,不产生下一状态。 |
| 纯文本 LLM | \(p(w_{n+1} \mid w_{\le n})\) | 广义可以,狭义通常不是 | 预测文本序列,不一定有环境状态和动作条件。 |
| 纯提示词到视频模型 | \(p(x_{1:T} \mid prompt)\) | 广义可以,狭义通常不是 | 生成未来片段,但用户动作不一定进入转移方程。 |
| 动作条件动力学模型 | \(p(s_{t+1}, r_t \mid s_t, a_t)\) | 是 | 能回答“如果这样做,会怎样”。 |
这个边界并不是为了排除 LLM、视频模型或奖励模型的价值,而是为了避免把“预测、评价、生成、控制”都混成同一个概念。狭义世界模型的核心对象始终是动作条件动力学。
一个经典样板:V-M-C
Ha 与 Schmidhuber 的 World Models 把智能体拆成三块:
V:把高维观测压成低维 latent \(z_t\)。M:维护历史记忆 \(h_t\),并预测动作后的下一 latent。C:根据当前 latent 和历史记忆输出动作。
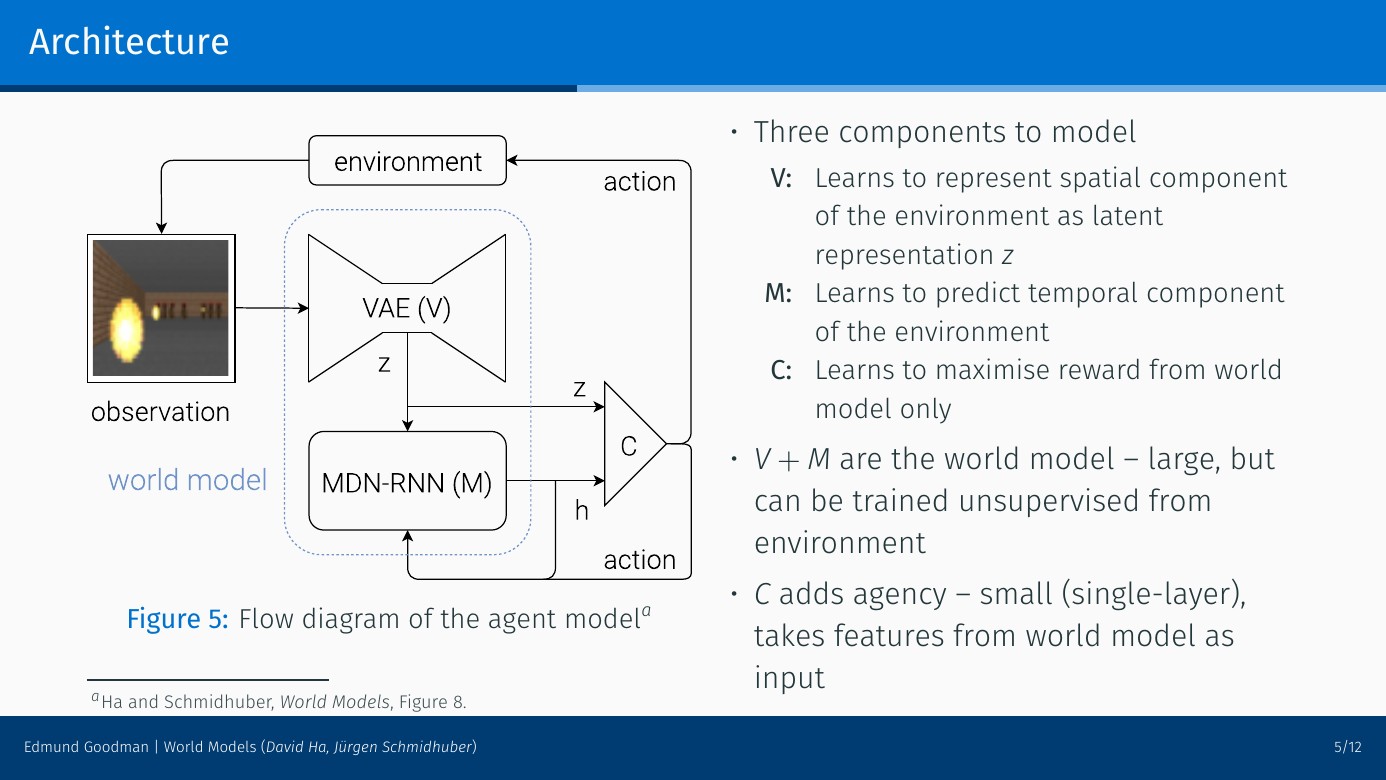
这张图容易被读成“先 M 决定动作,再 C 执行”。更准确的理解是:当前动作由 C 产生,M 提供历史记忆,并在动作发生后更新下一步记忆。展开一个时间步会清楚很多:
其中 C 决策时看的是 \([z_t, h_t]\):\(z_t\) 是当前画面,\(h_t\) 是 M 根据过去历史总结出的记忆。然后 C 输出动作 \(a_t\)。
M 不负责直接选动作。它接收当前 latent、当前动作和历史记忆,更新下一步记忆,并给出下一 latent 的预测:
因此,图里的循环应该按时间理解:
一句话概括:M 是记忆/世界预测器,C 是动作决策器。C 用 M 的记忆做动作,M 用 C 的动作更新世界状态。
在这个架构里,真正的世界模型主要是 V + M;C 是利用世界模型行动的控制器。Ha 与 Schmidhuber 最有启发性的地方,是让智能体在 V + M 生成的“梦境”中训练 C,再把学到的策略拿回真实环境测试。
与 RL、LLM、多模态模型的关系
强化学习本身不是世界模型。RL 问题通常可以写成:
如果一个 RL 方法只学习策略或价值函数:
它属于无模型强化学习(model-free RL),不需要显式模拟下一状态。世界模型对应的是另一个对象:
有了这个模型,智能体可以在内部展开多条可能轨迹,再用规划器或控制器选动作:
LLM 和视觉多模态大模型也需要分情况看。纯文本 LLM 学的是:
这可以被宽泛地理解成“文本世界”的预测模型,但它通常不是狭义世界模型,因为它没有明确的物理状态、动作和环境转移。视觉多模态模型如果只是回答图像问题:
也不算狭义世界模型。只有当它被接入动作条件,能持续预测“我做这个动作后观测如何变化”时,才进入机器人/RL 意义上的世界模型。
发展脉络
Datawhale 把世界模型的发展讲成四个时代:理论奠基、Ha & Schmidhuber 的梦中学习、Dreamer 的潜在空间、视频即世界。这个分法适合入门,因为它抓住了每一阶段要解决的瓶颈;但它不是严格分类法,因为这些阶段并不互斥。一个今天的系统可以同时使用 RSSM、Transformer、diffusion decoder 和 JEPA 式表征。
这四个阶段可以理解为一组逐步变化的问题意识:
| 阶段 | 核心问题 | 代表形式 | 本文中的位置 |
|---|---|---|---|
| 理论奠基 | 如何从历史中预测隐藏状态? | Kalman filter、HMM、RNN、状态空间模型 | 提供 \(p(s_{t+1} \mid s_t, a_t)\) 这种动力学视角。 |
| V-M-C / 梦中学习 | 能不能在学到的环境里训练策略? | \(V\) 编码,\(M\) 预测,\(C\) 控制 | 对应上面的 V-M-C 时间展开。 |
| Dreamer / 潜空间 RL | 能不能在潜空间的想象轨迹中训练行为? | \(p(z_{t+1}, r_t \mid z_t, a_t)\) | 对应狭义世界模型的主干:潜在状态转移。 |
| 视频 / 表征基础模型 | 能不能从大规模视频中学到可迁移的世界表征? | JEPA、V-JEPA、Genie、视频扩散模型 / Transformer | 对应下面的交互式视频和潜空间表征路线。 |
脱离具体年份看,世界模型通常包含三件事:把观测变成状态,学习状态如何随动作变化,再把这种预测交给生成、规划或策略学习使用。
其中 \(E_{\phi}\) 负责表示学习,\(T_{\theta}\) 负责动作条件转移。至于模型服务于重建、生成、规划、训练策略还是风险评估,是下游使用方式的差异。
当前的三条工程路线
现代世界模型大致可以分成三条路线。它们都试图学习世界变化,但内部表示不同。

第一类是先生成 3D 场景,再渲染或模拟。NeRF 和 Gaussian Splatting 属于这一脉络。它们的优势是有较明确的场景表示,可以被渲染器理解;难点是动态交互和长程物理仍然复杂。
第二类是交互式视频模型。Genie 这类模型接收一张初始图和用户动作,然后逐步生成下一帧:
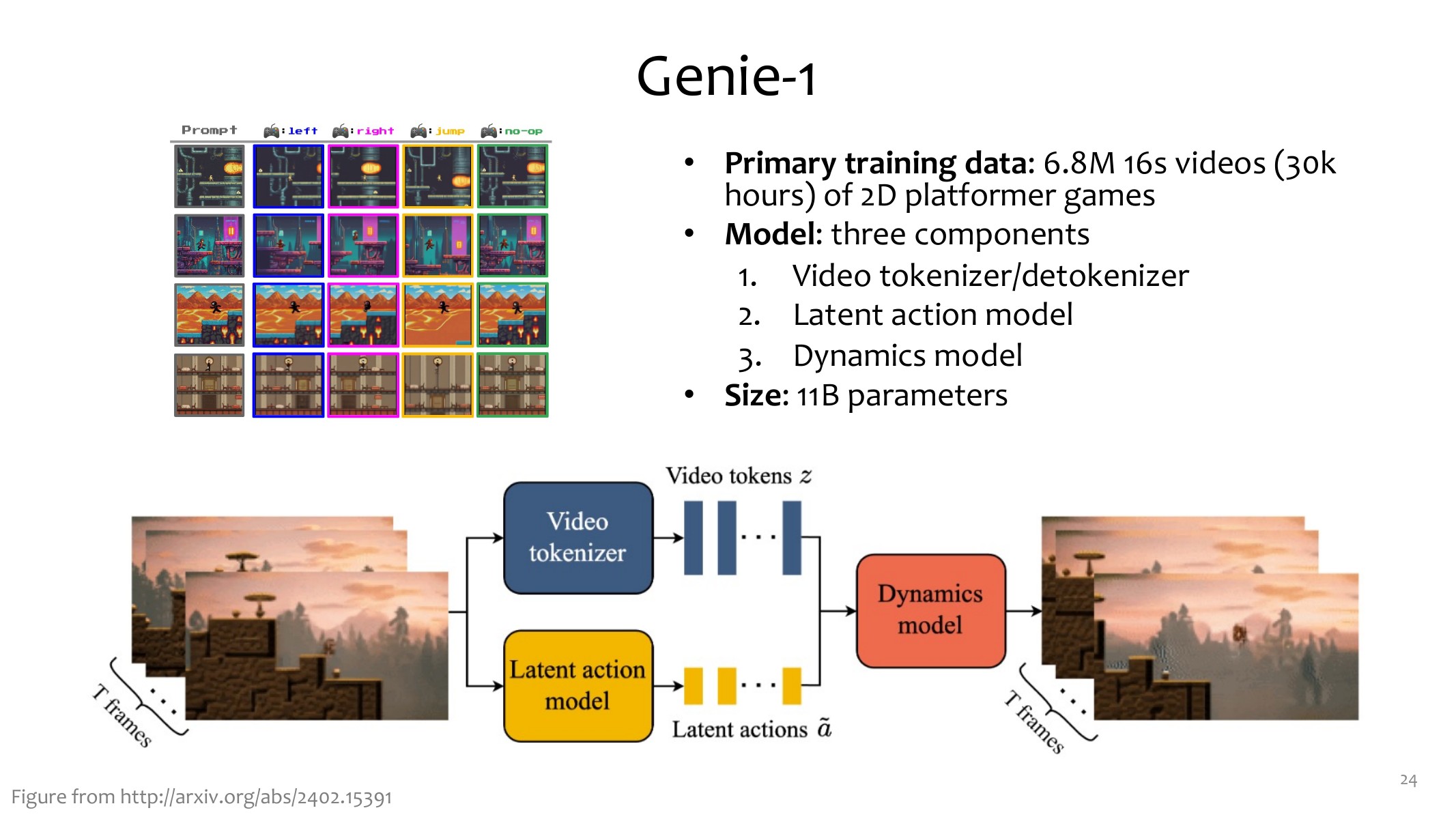
它的体验像游戏引擎,但底层仍然主要是视频模型。优点是可以利用大量无动作标签视频;缺点是动作集合通常是封闭的潜动作(latent action),模型没有显式 mesh、点云或物理状态。
第三类是潜空间世界表征,例如 V-JEPA 和 PAN。它们尽量不在像素上做长程预测,而是在 latent space 里预测,再按需要解码。
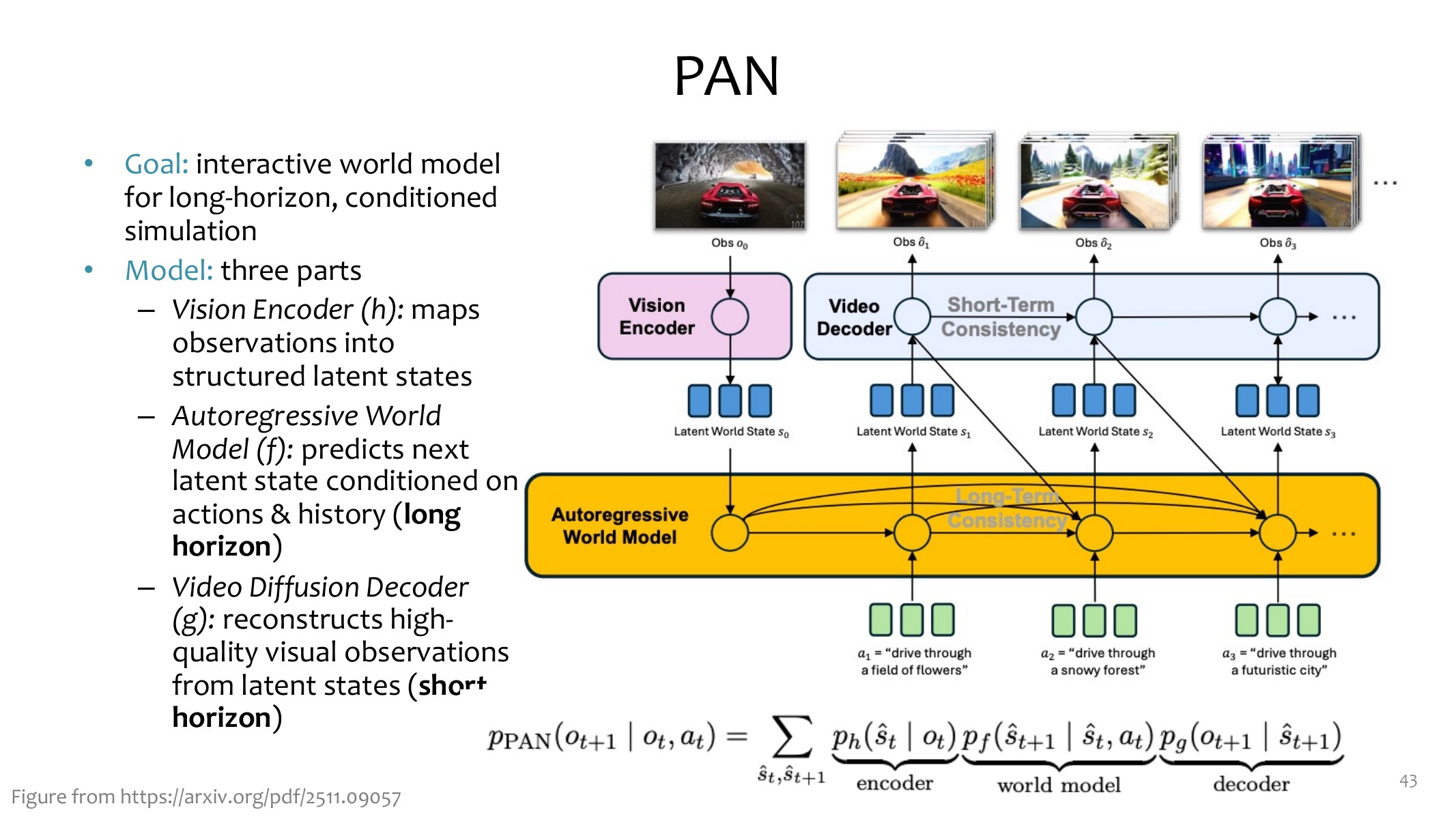
PAN 可以写成:
\(h\) 是视觉编码器,\(f_{\theta}\) 是自回归世界模型,\(g_{\psi}\) 是视频扩散解码器。关键取舍是:长程一致性交给 latent dynamics,短程视觉保真交给 decoder。
为什么现在重要
NVIDIA 的 Glossary 更偏工程和物理 AI(physical AI)语境:世界模型要理解真实世界的动态、物理和空间性质,并利用文本、图像、视频、声音、运动等数据预测接下来会发生什么。
从工程流程看,世界基础模型通常包括四步:数据整理、tokenization、预训练、后训练与强化学习。对应到应用,核心价值也很直接:
- 闭环学习:机器人可以在模拟世界里失败、修正,而不用每次损耗真实设备。
- 合成数据:长尾场景可以被可控生成,例如罕见交通冲突或危险工业动作。
- 规划:模型不只回答“我看到了什么”,还回答“如果我这样做,会发生什么”。
同时要记住三个边界:视觉真实不等于物理真实;短期预测不等于长期规划;潜动作不等于可解释控制。
判断标准
如果只保留一句话:
世界模型是一个可被智能体调用的内部模拟器:它把观测压成状态,根据动作预测状态如何变化,并把这种预测用于生成、训练、规划或控制。
判断一个系统是否进入狭义世界模型的讨论,可以看四个问题:
- 是否有状态或 latent state?
- 是否显式接受动作?
- 是否能预测动作导致的下一状态?
- 是否能支持反事实模拟、规划或策略学习?
能回答这些问题,才算真正进入了狭义世界模型的讨论。
参考
- Datawhale: 思想基石:Craik、预测编码与内模原理
- Datawhale: 四个时代的故事
- NVIDIA Glossary: What Is a World Model?
- David Ha and Jürgen Schmidhuber: World Models
- Edmund Goodman: World Models, slide deck, Nov. 20, 2024.
- Matt Gormley and Aran Nayebi: Interactive World Models, CMU Generative AI Lecture 26, Dec. 3, 2025.