AdaWorld latent actions
A short note on action-aware pretraining as a reusable control interface for adaptable world models.
AdaWorld 的关键不是再做一个更强的视频预测器,而是在预训练阶段就学习一个可迁移的 latent action interface,让新环境适配从“重新学习控制”变成“把新动作映射到已有动作表征”。
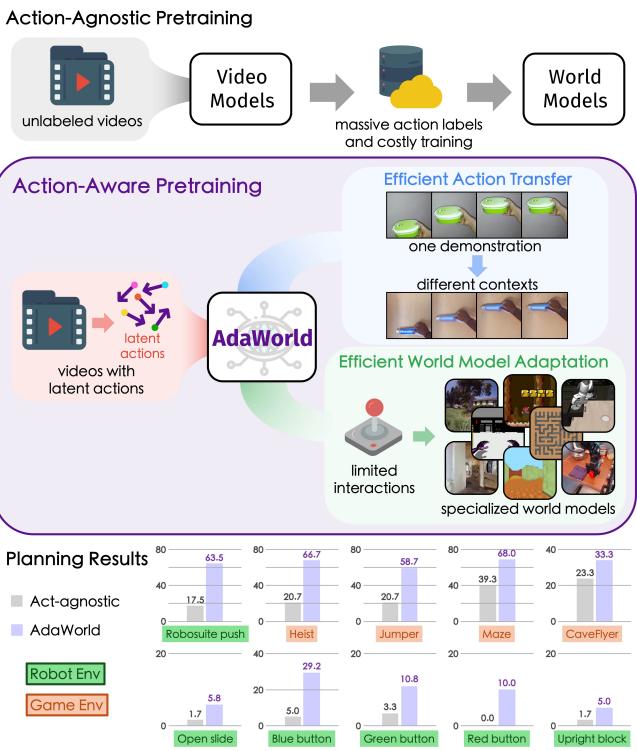
框架
传统 world model 多从 action-agnostic video pretraining 起步:模型学到视觉动态,但没有可复用的控制接口;到新环境时,需要大量 action-labeled data 去补上“动作如何改变世界”这件事。
AdaWorld 改成 action-aware pretraining:
- 从无标注视频相邻帧中抽取 latent action;
- 用 latent action 条件化 autoregressive world model;
- 到新环境时,用少量交互把 raw action 对齐到这个 latent action space。
算法核心
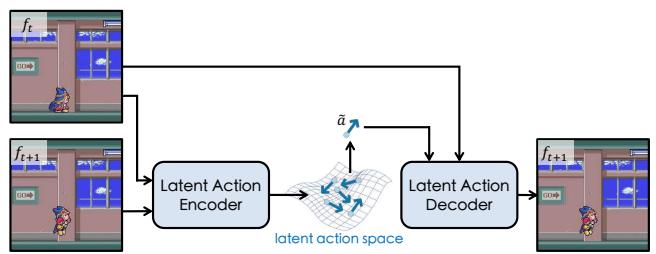
第一步是 latent action autoencoder。给定相邻帧 \(f_t, f_{t+1}\),encoder 学一个紧凑变量:
decoder 再用 \((f_t, \tilde a)\) 重建 \(f_{t+1}\)。因为 \(\tilde a\) 的容量很小,模型不能把整张下一帧塞进去,只能保留最能解释状态变化的信息,也就是近似“动作”。
训练目标可以理解为:
\(\beta\) 控制一个关键 tradeoff:太小会让 latent action 带入过多场景细节,太大会压掉动作表达能力。
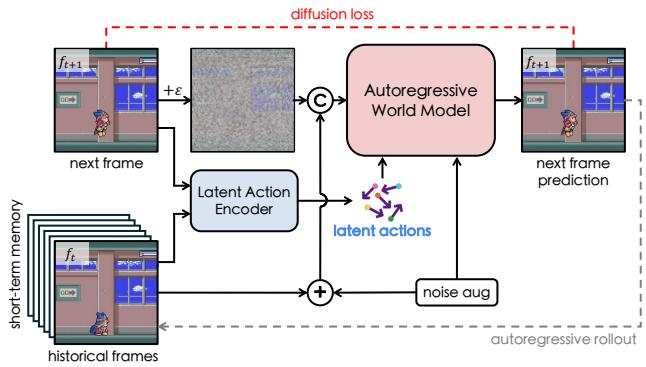
第二步是 action-aware world model pretraining。对大规模无标注视频的每个 transition 提取 \(\tilde a\),再训练 diffusion/SVD-style world model:
推理时,模型用历史帧和 latent action 逐帧 rollout。这样 action 不再是下游任务才补上的监督信号,而是预训练期间就被写入模型的控制接口。
核心意义
这篇工作的意义在于把“动作标注稀缺”问题转成“动作接口对齐”问题:预训练阶段从观察中学通用 latent actions;适配阶段只需用少量样本估计 raw action 到 latent action 的映射。离散动作可以按标签平均 latent embeddings 初始化,连续动作可以用小 MLP 映射到 latent action space。
Takeaway: action-aware pretraining 的价值不是多一个 conditioning token,而是让 world model 在大规模视频预训练时就获得可迁移、可组合、可快速校准的控制语义。