流匹配与扩散模型导论
MIT 6.S184 课程讲义的中文翻译与双语对照版本,系统介绍 flow matching、扩散模型、score matching、guidance、latent diffusion 和离散扩散语言模型。
彼得·霍尔德里斯和埃兹拉·埃里维斯
网站:https://diffusion.csail.mit.edu/
1 简介
从数据中产生噪声很容易;从噪声中创建数据就是生成式建模。
宋等人。 [43]
1.1 概述
近年来,我们都见证了人工智能(AI)的巨大革命。像 Nano Banana 或 Stable Diffusion 3 这样的图像生成器可以生成各种风格的真实感和艺术图像,像 Meta 的 VEO-3 这样的视频模型可以生成高度逼真的电影剪辑,像 ChatGPT 这样的大型语言模型可以对文本prompt生成看似人类水平的响应。这场革命的核心在于人工智能系统的一项新能力:生成对象的能力。虽然前几代人工智能系统主要用于预测,但这些新的人工智能系统具有创造性:它们根据用户指定的输入梦想或想出新的物体。这种生成式人工智能系统是最近这场人工智能革命的核心。
本课程的目标是教您两种最广泛使用的生成式 AI 算法:去噪扩散模型 $[45]$ 和流匹配 $[25, 27, 1, 26]$ 。这些模型是最佳图像、音频和视频生成式模型(例如 Nano Banana、FLUX 或 VEO-3)的支柱,并且最近已成为蛋白质结构等科学应用领域的最先进模型(例如 AlphaFold3 是一种扩散模型)。毫无疑问,理解这些模型确实是一项非常有用的技能。
所有这些生成式模型都通过迭代地将噪声转换为数据来生成对象。常微分方程或随机微分方程 (ODE/SDE) 的模拟促进了从噪声到数据的演变。流匹配和去噪扩散模型是一系列技术,使我们能够使用深度神经网络大规模构建、训练和模拟此类 ODE/SDE。虽然这些模型实现起来相当简单,但 SDE 的技术性质可能使这些模型难以理解。在本课程中,我们提供有关微分方程的必要数学工具箱的独立介绍,使您能够系统地理解这些模型。然后,我们逐步解释最先进的图像和视频生成器的现代堆栈。除了广泛适用之外,我们相信流模型与扩散模型背后的理论本身就是优雅的。因此,最重要的是,我们希望本课程能给您带来很多乐趣。
备注 1(其他资源)
虽然这些讲义是独立的,但我们鼓励您使用两个额外的资源:
- 讲座录音:以讲座形式引导您完成每个部分。
- 实验室:这些将引导您从头开始实现自己的扩散模型。我们强烈建议您“亲自动手”并编写代码。
您可以在我们的课程网站上找到这些内容:https://diffusion.csail.mit.edu/.
1.2 课程结构
我们对该文档进行简要概述。
- 第 1 节,生成式建模作为采样:我们将“生成”图像、视频、蛋白质等的含义形式化。我们将翻译“如何生成狗的图像?”等问题。进入更精确的从概率分布中采样的问题。
- 第 2 节,流模型与扩散模型:我们解释生成机制。正如您可以通过此类的名称猜到的那样,该机制由模拟常微分方程和随机微分方程组成。我们介绍微分方程并解释如何使用它们构建生成式模型。
- 第 3 节,流匹配:接下来,我们解释并推导流匹配,这是一种简单且可扩展的算法,是所有上述大规模生成式模型(例如稳定扩散、纳米香蕉或 SORA)的核心。
- 第 4 节,score matching:我们研究score 函数以及如何通过score matching来学习它们。这不仅是扩散模型的训练算法,而且还解锁了 SDE 采样和引导。
- 第 5 节,引导:我们学习如何根据prompt(例如“猫的图像”)调整样本,以及如何通过无分类器的引导来强制遵守此类prompt。
- 第 6 节,latent 空间,神经网络架构:我们讨论如何构建大规模图像和视频生成器,例如 Nano Banana。这包括常见的神经网络架构以及如何在latent 空间中构建事物。我们还调查了最先进的模型。
- 第 7 节(可选),离散扩散模型:我们学习如何将扩散模型的原理从欧几里得空间转换为离散数据(例如语言)。这使得能够使用扩散模型的原理构建大型语言模型。
所需背景。由于该学科的技术性质,我们建议您具备一定的数学成熟度,特别是对概率论有一定的了解。因此,我们在 A 部分中加入了关于概率论的简短提醒部分。如果您不熟悉其中的某些概念,请不要担心。
1.3 生成式建模作为采样
让我们首先考虑我们可能遇到的各种数据类型或数据模式,以及如何用数字表示它们:
- 图像:考虑具有 $H \times W$ 像素的图像,其中 H 描述图像的高度,W 描述图像的宽度,每个图像具有三个颜色通道 (RGB)。对于每个像素和每个颜色通道,我们都会获得 R 中的强度值。因此,图像可以由元素 $z \in R^{H \times W \times 3}$ 表示。
- 视频:视频只是时间上的一系列图像。如果我们有 T 个时间点或帧,则视频将由元素 $z \in R^{T \times H \times W \times 3}$ 表示。
- 分子结构:一种简单的方法是用矩阵来表示分子的结构
$z = (z^{1}, \ldots, z^{N}) \in \mathbb{R}^{3 \times N}$ 其中 $N$ 是分子中的原子数,每个 $z^{i} \in \mathbb{R}^{3}$ 描述该原子的位置。当然,还有其他更复杂的方式来表示这种分子。
在上述所有示例中,我们想要生成的对象可以在数学上表示为向量(可能在展平之后)。因此,在本文档中,我们将:
关键思想 1(对象作为向量)
我们将生成的对象标识为向量 $z \in \mathbb{R}^d$ 。
上述情况的一个值得注意的例外是文本数据,它通常通过语言模型(例如 ChatGPT)建模为离散对象。虽然连续数据 $z \in R^{d}$ 是我们的主要关注点,但我们还在第 7 节中研究文本生成。
生成作为采样。让我们定义“生成”某些东西的含义。例如,假设我们想要生成一张狗的图像。当然,我们可能会喜欢很多可能的狗图像。特别是,没有一张狗的“最佳”形象。相反,存在一系列适合或更适合的图像。在机器学习中,通常将可能图像的多样性实现为图像空间上的概率分布。我们将这种分布称为数据分布并将其表示为 $p_{data}$ 。从数学上讲,我们可以将 $p_{data}$ 视为一种概率密度,即函数 $p_{data}: R^{d} \to R_{\geq 0}$ 为每个可能的对象 $z \in R^{d}$ 分配可能性 $p_{\mathrm{data}}(z) \geq 0$ 。因此,在狗图像的示例中,此分布将为看起来更像狗的图像 z 提供更高的可能性 $p_{\mathrm{data}}(z)$。因此,图像/视频/分子适合的程度(一个相当主观的陈述)被它在数据分布 $p_{data}$ 下的“可能性”程度所取代。有了这个,我们可以在数学上将生成任务表示为从(未知)分布 $p_{data}$ 进行采样:
关键思想 2(生成作为采样)
生成对象 z 被建模为从数据分布 $z \sim p_{data}$ 中采样。
生成式模型是一种机器学习模型,允许我们从 $p_{data}$ 生成样本。在机器学习中,我们需要数据来训练模型。在生成式建模中,我们通常假设可以访问独立于 $p_{data}$ 采样的有限数量的示例,它们一起充当真实分布的代理。
关键想法 3(数据集)
数据集由有限数量的样本 $z_{1},\ldots,z_{N}\sim p_{data}$ 组成。
对于图像,我们可以通过编译来自互联网的公开可用图像来构建数据集。对于视频,我们可能同样会使用 YouTube。对于蛋白质结构,RCSB 蛋白质数据库 (PDB) 等来源提供了数十万个经过实验解析的结构。随着我们的数据集的大小变得非常大,它越来越能更好地表示底层分布 $p_{data}$ 。
引导/条件生成。在许多情况下,我们希望生成一个以某些数据 y 为条件的对象。例如,我们可能想要生成一个以 y =“一只狗跑下覆盖着雪的山坡,背景是山脉”为条件的图像。我们可以将其重新表述为从条件分布中采样:
关键理念 4(引导生成)
引导生成涉及从 $z \sim p_{\mathrm{data}}(\cdot|y)$ 进行采样,其中 y 是条件变量。
我们将 $p_{\text{data}}(\cdot|y)$ 称为引导数据分布。引导生成式建模任务通常涉及学习以任意而不是固定的 y 选择为条件。使用前面的示例,我们可能希望以不同的文本prompt为条件,例如 $y = “a photorealistic image of a cat blowing out birthday candles”$ 。因此,我们寻求一个可以以 y 的任何此类选择为条件的单一模型。事实证明,无条件生成技术很容易推广到条件情况。因此,对于前 3 部分,我们将几乎完全关注无条件情况(请记住,条件生成是我们正在构建的目标)。
生成式模型。抽象地说,生成式模型是一种从 $z \sim p_{data}$ (或至少近似)返回样本的算法。如果 $p_{data}$ 是狗图像的分布,则该算法将返回狗的随机图像。在本课程中,我们将重点关注使用流或扩散模型的生成式模型的具体构建,因为这些模型代表了当前的最先进技术。然而,重要的是要记住,还开发了许多其他生成式模型(甚至将来可能会发现更多)。
总结2(生成作为采样)
我们总结本节的发现:
- 在这项工作中,我们主要考虑生成表示为向量$z \in \mathbb{R}^d$的对象的任务,例如图像、视频和分子结构。
- 生成是根据概率分布 $p_{data}$ 生成样本的任务,在训练期间可以访问样本数据集 $z_{1},\ldots,z_{N}\sim p_{data}$。
- 引导生成假设我们在标签 $y$ 上调节分布,并且我们希望从 $p_{\mathrm{data}}(\cdot |y)$ 中进行采样,以便在训练期间能够访问 $(z_1,y)\ldots ,(z_N,y)$ 对的数据集。
- 我们的目标是构建一个生成式模型,即训练后从 $p_{data}$ 返回样本的模型。
2 流模型与扩散模型
在上一节中,我们将生成式模型形式化为从数据分布 $p_{data}$ 中采样。此外,我们正式确定了我们的目标:构建一个生成式模型,即返回样本 $z \sim p_{data}$ 的算法。在本节中,我们将描述如何构建生成式模型来模拟适当构造的微分方程。例如,流动匹配和扩散模型分别涉及模拟常微分方程 (ODE) 和随机微分方程 (SDE)。因此,本节的目标是定义和构建这些生成式模型,因为它们将在笔记的其余部分中使用。具体来说,我们首先定义 ODE 和 SDE,并讨论它们的模拟。其次,我们描述如何使用深度神经网络参数化 ODE/SDE。这导致了流模型与扩散模型的定义以及从此类模型中采样的基本算法。在后面的部分中,我们将探讨如何训练这些模型。
2.1 流模型
我们首先定义常微分方程 (ODE)。 ODE 的解由轨迹定义,即以下形式的函数
$$ X: [ 0, 1 ] \to \mathbb {R} ^ {d}, \quad t \mapsto X _ {t}, $$
从时间 t 映射到空间中的某个位置 $R^{d}$ 。每个 ODE 都由向量场 u 定义,即以下形式的函数
$$ u: \mathbb {R} ^ {d} \times [ 0, 1 ] \to \mathbb {R} ^ {d}, (x, t) \mapsto u _ {t} (x), $$
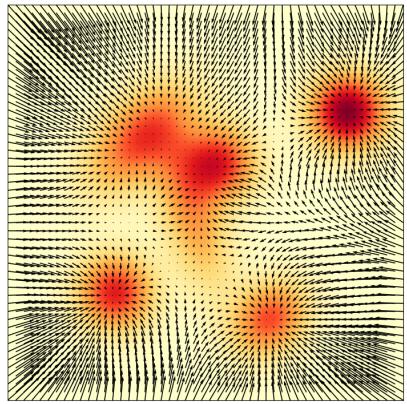
即对于每个时间 t 和位置 x 我们得到一个向量 $u_{t}(x) \in \mathbb{R}^{d}$ 指定空间速度(见图 1)。 ODE 对轨迹施加一个条件:我们想要一条“沿着向量场的线”的轨迹 X $u_{t}$ ,从点开始 $x_{0}$ 。我们可以将这样的轨迹形式化为方程的解:
$$ \begin{array}{l} \frac {\mathrm{d}}{\mathrm{d} t} X _ {t} = u _ {t} (X _ {t}) \quad \blacktriangleright \text { ODE } (1a) \\ X _ {0} = x _ {0} \quad \blacktriangleright \text { initial conditions } (1b) \\ \end{array} $$
方程 (1a) 要求 $X_{t}$ 的导数由 $u_{t}$ 给出的方向指定。方程 (1b) 要求我们在时间 t=0 时从 $x_{0}$ 开始。我们现在可能会问:如果我们从 t=0 的 $X_{0}=x_{0}$ 开始,那么我们在时间 t 的位置(什么是 $X_{t}$ )?这个问题可以通过一个称为 flow 的函数来回答,它是 ODE 的解决方案
$$ \psi : \mathbb {R} ^ {d} \times [ 0, 1 ] \rightarrow \mathbb {R} ^ {d}, (x _ {0}, t) \mapsto \psi_ {t} (x _ {0}) \tag {2a} $$
$$ \frac {\mathrm{d}}{\mathrm{d} t} \psi_ {t} (x _ {0}) = u _ {t} (\psi_ {t} (x _ {0})) \quad \blacktriangleright \text { flow ODE } \tag {2b} $$
$$ \psi_ {0} (x _ {0}) = x _ {0} \quad \blacktriangleright \text {flow initial conditions} \tag {2c} $$
对于给定的初始条件 $X_{0} = x_{0}$ ,ODE 的轨迹通过 $X_{t} = \psi_{t}(X_{0})$ 恢复。因此,直观上讲,向量场、ODE 和流是同一对象的三种描述:向量场定义解为流的 ODE。与每个方程一样,我们应该问自己关于 ODE 的问题:是否存在解,如果存在,它是否唯一?数学的一个基本结果是“是!”对于两者,只要我们对 $u_{t}$ 施加弱假设:
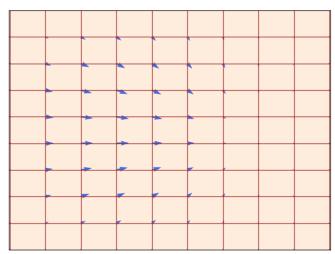
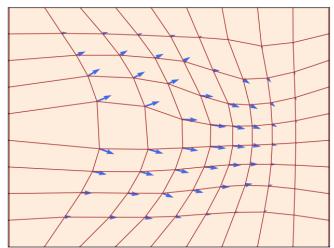
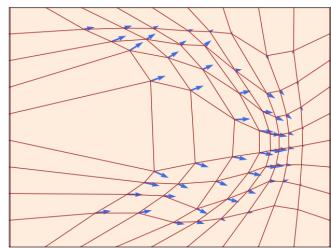
定理3(流的存在性和唯一性)
如果 $u : R^{d} \times [0,1] \to R^{d}$ 可连续微分有界导数,则 (2) 中的 ODE 具有由流 $\psi_{t}$ 给出的唯一解。在这种情况下, $\psi_{t}$ 是所有 t 的微分同胚,即 $\psi_{t}$ 与连续可微逆 $\psi_{t}^{-1}$ 连续可微。
请注意,机器学习中几乎总是满足流的存在性和唯一性所需的假设,因为我们使用神经网络来参数化 $u_{t}(x)$ 并且它们始终具有有界导数。因此,定理 3 不应该成为您关心的问题,而是一个好消息:在我们感兴趣的情况下,流是存在的,并且是 ODE 的独特解决方案。可以在 [32, 9] 中找到证明。
示例 4(线性矢量场)
让我们考虑一个向量场 $u_{t}(x)$ 的简单示例,它是 x 中的简单线性函数,即 $u_{t}(x) = -\theta x$ 代表 $\theta > 0$ 。然后函数
$$ \psi_ {t} (x _ {0}) = \exp (- \theta t) x _ {0} \tag {3} $$
定义了求解方程 (2) 中的 ODE 的流程 $\psi$。您可以通过检查 $\psi_{0}(x_{0}) = x_{0}$ 并计算来自行检查
$$ \frac {\mathrm{d}}{\mathrm{d} t} \psi_ {t} (x _ {0}) \stackrel {(3)} {=} \frac {\mathrm{d}}{\mathrm{d} t} \left(\exp (- \theta t) x _ {0}\right) \stackrel {(i)} {=} - \theta \exp (- \theta t) x _ {0} \stackrel {(3)} {=} - \theta \psi_ {t} (x _ {0}) = u _ {t} (\psi_ {t} (x _ {0})), $$
在 (i) 中我们使用了链式法则。在图 3 中,我们可视化这种形式的流以指数方式收敛到 0。
模拟 ODE。一般来说,无法计算流量 $\psi_{t}$ 明确地如果 $u_{t}$ 并不像前面的例子那么简单。在这些情况下,可以使用数值方法来模拟 ODE。幸运的是,这是数值分析中一个经典且经过深入研究的主题,并且存在无数强大的方法 [21]。最简单、最直观的方法之一是欧拉方法。在欧拉方法中,我们初始化为 $X_{0} = x_{0}$ 并通过更新
$$ X _ {t + h} = X _ {t} + h u _ {t} (X _ {t}) \quad (t = 0, h, 2 h, 3 h, \dots , 1 - h) \tag {4} $$
其中 $h = n^{-1} > 0$ 是步长,$n \in \mathbb{N}$ 是模拟步骤数。对于这个类,Euler 方法就足够了。为了让您体验更复杂的方法,让我们考虑通过更新规则定义的 Heun 方法
$$ \begin{array}{l} X _ {t + h} ^ {\prime} = X _ {t} + h u _ {t} (X _ {t}) \quad \blacktriangleright \text { initial guess of new state (same as Euler step) } \\ X _ {t + h} = X _ {t} + \frac {h}{2} (u _ {t} (X _ {t}) + u _ {t + h} (X _ {t + h} ^ {\prime})) \quad \blacktriangleright \text {update with average u at current and guessed state} \\ \end{array} $$
直观上,Heun 的方法如下:它首先猜测 $X_{t + h}'$ 下一步可能是什么,但通过更新的猜测来纠正最初采取的方向。
流动模型。我们现在可以通过 ODE 构建生成式模型,将向量场设为神经网络向量场 $u_{t}^{\theta}$ 。现在,我们的意思只是 $u_{t}^{\theta}$ 是一个参数化函数 $u_{t}^{\theta}: R^{d} \times [0,1] \to R^{d}$ 带参数 $\theta$ 。稍后,我们将讨论神经网络架构的特定选择。请记住,我们的目标是生成样本 $z \sim p_{data}$ 来自分布 $p_{data}$ 。特别是,这些样本必须是随机的。但请注意,ODE 本身不是随机的,而是完全确定性的。为了注入一些随机性,我们简单地设置初始条件 $X_{0}$ 随机的。具体来说,我们选择一个初始分布 $p_{init}$ 。大多数情况下,我们设置 $p_{\mathrm{init}} = \mathcal{N}(0, I_{d})$ 是一个简单的标准高斯分布。最重要的是,无论您选择什么分布,它都必须是我们可以在推理时轻松采样的分布。然后用 ODE 描述流模型
$$ X _ {0} \sim p _ {\mathrm{init}} $$
▶ 随机初始化
$$ \frac {\mathrm{d}}{\mathrm{d} t} X _ {t} = u _ {t} ^ {\theta} (X _ {t}) $$
▶ 常微分方程
我们的目标是使轨迹的端点 $X_{1}$ 具有分布 $p_{data}$ ,即
$$ X _ {1} \sim p _ {\mathrm{data}} \quad \Leftrightarrow \quad \psi_ {1} ^ {\theta} (X _ {0}) \sim p _ {\mathrm{data}} $$
其中 $\psi_{t}^{\theta}$ 描述了 $u_{t}^{\theta}$ 引起的流。但请注意:虽然称为流模型,但神经网络参数化的是矢量场,而不是流。为了计算流量,我们需要模拟 ODE。在算法 1 中,我们总结了如何从流模型中采样的过程。
算法 1 使用欧拉方法从流模型中采样
要求:神经网络向量场 $u_{t}^{\theta}$ ,步数 n
1:设置t=0
2: 设置步长 $h = \frac{1}{n}$ 3: 抽取样本 $X_{0} \sim p_{init}$ 4: 为 $i = 1, \ldots, n$ 做
5: $X_{t+h} = X_{t} + hu_{t}^{\theta}(X_{t})$ 6: 更新 $t \leftarrow t + h$ 7: 结束
8:返回$X_{1}$
2.2 扩散模型
随机微分方程 (SDE) 将 ODE 的确定性轨迹扩展为随机轨迹。随机轨迹通常称为随机过程 $(X_{t})_{0\leq t\leq1}$ ,由下式给出
$$ X _ {t} \text {is a random variable for every} 0 \leq t \leq 1 $$
$$ X: [ 0, 1 ] \to \mathbb {R} ^ {d}, t \mapsto X _ {t} \text {is a random trajectory for every draw of} X $$
特别是,当我们两次模拟相同的随机过程时,我们可能会得到不同的结果,因为动态被设计为随机的。
布朗运动。 SDE 是通过布朗运动构建的,布朗运动是物理扩散过程研究中产生的基本随机过程。您可以将布朗运动视为连续随机游走。
让我们定义它:布朗运动 $W = (W_{t})_{0 \leq t \leq 1}$ 是一个随机过程,使得 $W_{0} = 0$ 、轨迹 $t \mapsto W_{t}$ 是连续的,并且以下两个条件成立:
- 正常增量: $W_{t}-W_{s}\sim\mathcal{N}(0,(t-s)I_{d})$ 对于所有 $0\leq s
- 独立增量:对于任何 $0 \leq t_{0} < t_{1} < \cdots < t_{n} = 1$ ,增量 $W_{t_{1}} - W_{t_{0}}, \ldots, W_{t_{n}} - W_{t_{n-1}}$ 都是独立的随机变量。
布朗运动也称为维纳过程,这就是为什么我们用“W”表示它。 $^{1}$ 通过设置 $W_{0} = 0$ 并更新,我们可以轻松模拟步长 h > 0 的布朗运动
$$ W _ {t + h} = W _ {t} + \sqrt {h} \epsilon_ {t}, \quad \epsilon_ {t} \sim \mathcal {N} (0, I _ {d}) \quad (t = 0, h, 2 h, \ldots , 1 - h) \tag {5} $$
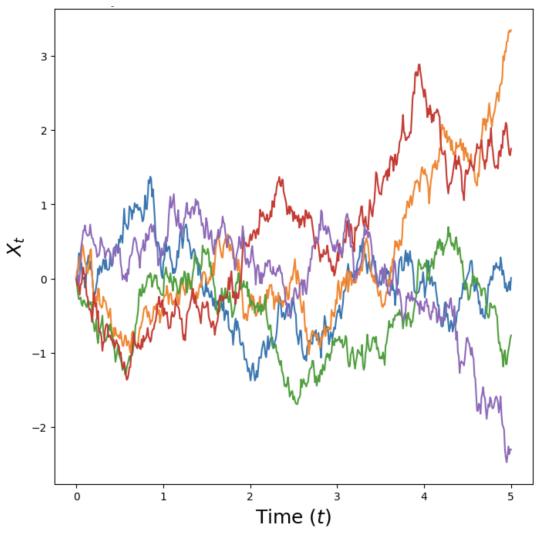
在图 2 中,我们绘制了布朗运动的一些示例轨迹
。布朗运动对于随机过程的研究来说就像高斯分布对于概率分布的研究一样重要。从金融到统计物理学再到流行病学,布朗运动的研究除了机器学习之外还有着深远的应用。例如,在金融领域,布朗运动用于对复杂金融工具的价格进行建模。同样,作为一种数学构造,布朗运动也很有趣:例如,虽然布朗运动的路径是连续的(因此您无需提笔就可以画出它),但它们却无限长(因此您永远不会停止画画)。
从 ODE 到 SDE。 SDE 的想法是通过添加由布朗运动驱动的随机动力学来扩展 ODE 的确定性动力学。因为一切都是随机的,我们可能不再像方程(1a)那样求导数。因此,我们需要找到不使用导数的 ODE 的等价公式。为此,我们将 ODE 的轨迹 $(X_{t})_{0\leq t\leq1}$ 重写如下:
$$ \frac {\mathrm{d}}{\mathrm{d} t} X _ {t} = u _ {t} (X _ {t}) $$
▶ 通过导数表达
$$ \stackrel {(i)} {\Leftrightarrow} \frac {1}{h} \left(X _ {t + h} - X _ {t}\right) = u _ {t} (X _ {t}) + R _ {t} (h) $$
$$ \Leftrightarrow X _ {t + h} = X _ {t} + h u _ {t} (X _ {t}) + h R _ {t} (h) \blacktriangleright \mathrm{expressionviainfinitesimalupdates} $$
其中 $R_{t}(h)$ 描述了小 h 的一个可忽略的函数,即 $\lim_{h\to0}R_{t}(h)=0$ ,并且在(i)中我们简单地使用导数的定义。上面的推导简单地重申了我们已经知道的内容:ODE 的轨迹 $(X_{t})_{0\leq t\leq1}$ 在每个时间步都朝 $u_{t}(X_{t})$ 方向迈出一小步。我们现在可以修改最后一个方程,使其具有随机性:SDE 的轨迹 $(X_{t})_{0\leq t\leq1}$ 在每个时间步都在 $u_{t}(X_{t})$ 方向上迈出一小步,加上布朗运动的一些贡献:
$$ X _ {t + h} = X _ {t} + \underbrace {h u _ {t} (X _ {t})} _ {\text { deterministic }} + \sigma_ {t} \underbrace {(W _ {t + h} - W _ {t})} _ {\text { stochastic }} + \underbrace {h R _ {t} (h)} _ {\text { error term }} \tag {6} $$
在哪里 $\sigma_{t}\geq0$ 描述扩散系数和 $R_{t}(h)$ 描述随机误差项,使得标准差 $\mathbb{E}[\|R_{t}(h)\|^{2}]^{1/2}\to0$ 变为零 $h\to0$ 。上面描述了随机微分方程(SDE)。通常用以下符号表示法:
$$ \mathrm{d} X _ {t} = u _ {t} (X _ {t}) \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \quad \blacktriangleright \text { SDE } \tag {7a} $$
$$ X _ {0} = x _ {0} \quad \blacktriangleright \text { initial condition } \tag {7b} $$
然而,请始终记住,上面的 $\mathrm{d}X_{t}$ 符号纯粹是方程 (6) 的非正式符号。不幸的是,SDE 不再有流程图 $\phi_{t}$。这是因为 $X_{t}$ 值不再完全由 $X_{0} \sim p_{init}$ 决定,因为进化本身是随机的。尽管如此,与 ODE 一样,我们有:
定理5(SDE解的存在性和唯一性)
如果 $u: \mathbb{R}^d \times [0,1] \to \mathbb{R}^d$ 具有有界导数连续可微,并且 $\sigma_t$ 连续,则 (7) 中的 SDE 具有由满足方程 (6) 的唯一随机过程 $(X_t)_{0 \leq t \leq 1}$ 给出的解。
如果这是一门随机微积分课,我们将花几个讲座来证明这个定理并以完全数学严谨的方式构建 SDE,即根据第一原理构建布朗运动并通过随机积分构建过程 $X_{t}$。由于我们在本课程中重点关注机器学习,因此我们参考 [29] 进行更技术性的处理。最后,请注意,每个 ODE 也是一个 SDE - 只是具有消失扩散系数 $\sigma_{t}=0$ 。因此,对于本课程的其余部分,当我们谈论 SDE 时,我们将 ODE 视为一种特殊情况。
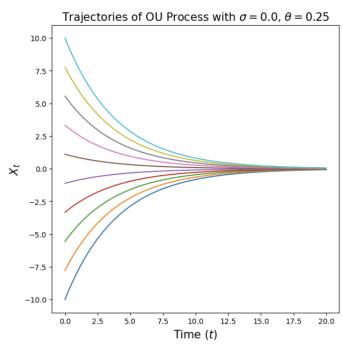
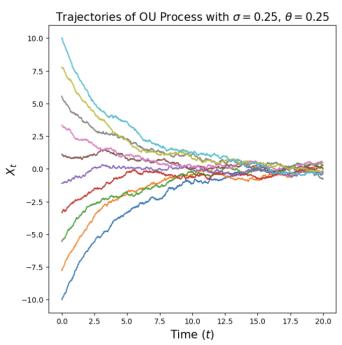
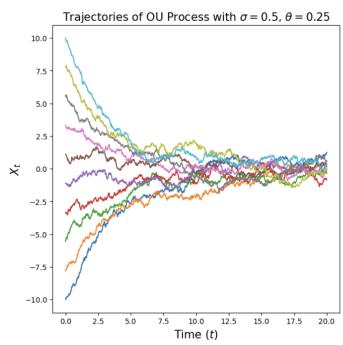
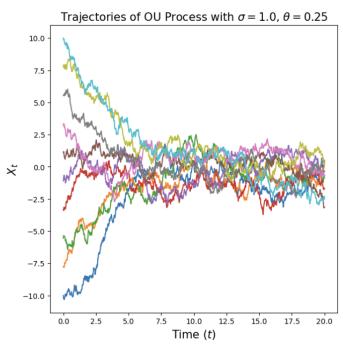
实施例6(奥恩斯坦-乌伦贝克法)
让我们考虑恒定的扩散系数 $\sigma_{t} = \sigma \geq 0$ 和恒定的线性漂移 $u_{t}(x) = -\theta x$ 为了 $\theta > 0$ ,产生 SDE
$$ \mathrm{d} X _ {t} = - \theta X _ {t} \mathrm{d} t + \sigma \mathrm{d} W _ {t}. \tag {8} $$
一个解决方案 $(X_{t})_{0\leq t\leq1}$ 上述 SDE 称为 Ornstein-Uhlenbeck (OU) 过程。我们将其可视化于图 3 中。矢量场 $-\theta x$ 将过程推回到其中心 0(因为漂移总是指向与当前位置相反的方向),而扩散系数 $\sigma$ 总是会增加更多的噪声。该过程收敛于高斯分布 $\mathcal{N}(0,\sigma^{2}/(2\theta))$ 如果我们模拟它 $t\to\infty$ 。请注意,对于 $\sigma=0$ ,我们有一个具有线性向量场的流,我们在方程(3)中研究过它。
模拟 SDE。如果到目前为止您对 SDE 的抽象定义感到困惑,那么不用担心。通过回答以下问题给出了思考 SDE 的更直观的方式:我们如何模拟 SDE?最简单的此类方案称为 Euler-Maruyama 方法,本质上对于 SDE 来说就像 Euler 方法对于 ODE 一样。使用 Euler-Maruyama 方法,我们初始化 $X_0 = x_0$ 并通过迭代更新
$$ X _ {t + h} = X _ {t} + h u _ {t} (X _ {t}) + \sqrt {h} \sigma_ {t} \epsilon_ {t}, \quad \epsilon_ {t} \sim \mathcal {N} (0, I _ {d}) \tag {9} $$
其中 $h = n^{-1} > 0$ 是 $n \in N$ 的步长超参数。换句话说,为了使用 Euler-Maruyama 方法进行模拟,我们朝 $u_{t}(X_{t})$ 方向迈出一小步,并添加一点按 $\sqrt{h}\sigma_{t}$ 缩放的高斯噪声。在本课程中(例如在随附的实验室中)模拟 SDE 时,我们通常会坚持使用 Euler-Maruyama 方法。
扩散模型。现在,我们可以通过 SDE 构建生成式模型,就像我们为 ODE 所做的那样。请记住,我们的目标是将简单分布 $p_{init}$ 转换为复杂分布 $p_{data}$ 。与 ODE 一样,使用 $X_{0} \sim p_{init}$ 随机初始化的 SDE 的模拟是此转换的自然选择。为了参数化这个 SDE,我们可以简单地通过神经网络参数化它的核心成分 - 向量场 $u_{t}$
算法 2 从扩散模型采样(Euler-Maruyama 方法)
要求:神经网络 $u_t^\theta$ ,步数 $n$ ,扩散系数 $\sigma_t$ 1: 设置 $t = 0$ 2: 设置步长 $h = \frac{1}{n}$ 3: 抽取样本 $X_0 \sim p_{\text{init}}$ 4: 对于 $i = 1, \ldots, n$ do
5: 抽取样本 $\epsilon \sim \mathcal{N}(0, I_d)$ 6: $X_{t+h} = X_t + hu_t^\theta(X_t) + \sigma_t \sqrt{h} \epsilon$ 7: 更新 $t \leftarrow t + h$ 8: 结束
9:返回$X_1$
网络 $u_{t}^{\theta}$ 。因此,扩散模型由下式给出
$$ X _ {0} \sim p _ {\mathrm{init}} $$
▶ 随机初始化
$$ \mathrm{d} X _ {t} = u _ {t} ^ {\theta} (X _ {t}) \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} $$
▶ SDE
在算法 2 中,我们描述了使用 Euler-Maruyama 方法从扩散模型中采样的过程。我们将本节的结果总结如下。
总结7(SDE生成式模型)
在本文档中,扩散模型由神经网络组成 $u_{t}^{\theta}$ 带参数 $\theta$ 参数化矢量场和固定扩散系数 $\sigma_{t}$ :
神经网络:$u^{\theta}:\mathbb{R}^{d}\times[0,1]\to\mathbb{R}^{d},(x,t)\mapsto u_{t}^{\theta}(x)$,参数为 $\theta$
已修复: $\sigma_{t}:[0,1]\to[0,\infty)$ 、 $t\mapsto\sigma_{t}$
要从我们的SDE模型中获取样本(即生成对象),过程如下:
初始化:$X_{0} \sim p_{init}$
▶ 使用简单的分布进行初始化,例如高斯
模拟:$\mathrm{d}X_{t}=u_{t}^{\theta}(X_{t})\mathrm{d}t+\sigma_{t}\mathrm{d}W_{t}$
▶ 模拟SDE从0到1
目标:$X_{1} \sim p_{data}$
▶ 目标是让$X_{1}$拥有分配$p_{data}$
具有 $\sigma_{t}=0$ 的扩散模型是流动模型。
3 流匹配
在上一节中,我们将流模型与扩散模型构建为由神经网络向量场 $u_{t}^{\theta}$ 参数化的生成式模型。然而,我们还没有讨论如何训练它们,即如何优化参数 $\theta$ 以使生成式模型返回一些合理的东西,例如漂亮的图片或令人兴奋的视频。接下来,我们讨论流匹配 [25, 1, 27],这是一种训练 $u_{t}^{\theta}$ 的算法,该算法简单、可扩展,代表了当前最先进的技术。
在本节中,我们将自己限制在流模型上,即我们有一个神经网络 $u_{t}^{\theta}$ 并通过模拟 ODE 从生成式模型中获取样本
$$ X _ {0} \sim p _ {\text { init }}, \quad \mathrm{d} X _ {t} = u _ {t} ^ {\theta} (X _ {t}) \mathrm{d} t \quad \text {(Flow model)} \tag {10} $$
并使用端点 $X_{1}$ fro t = 1 作为样本。正如我们所讨论的,我们的目标是 $X_{1}$ 根据数据分布 $p_{data}$ 进行分布,即 $X_{1} \sim p_{data}$ 。因此,“如何训练”神经网络的问题实际上是以下问题:我们如何优化 $\theta$ ,以便模拟等式(10)中的流模型得到来自数据分布 $X_{1} \sim p_{data}$ 的样本?





3.1 条件和边缘概率路径
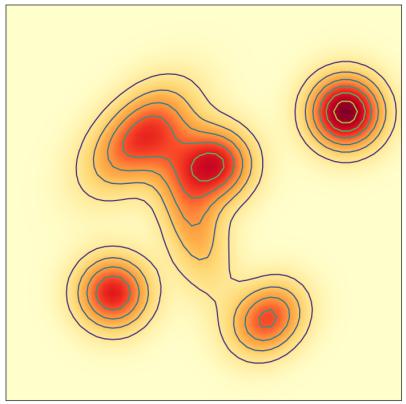
流匹配的第一步是指定概率路径。直观上,概率路径指定噪声 $p_{init}$ 和数据 $p_{data}$ 之间的逐步插值(见图 4)。但我们为什么要这样呢?请记住,我们所需的 ODE 轨迹在 t = 0 时满足 $X_{0} \sim p_{init}$,在 t = 1 时满足 $X_{1} \sim p_{data}$。但是在开始和结束之间的时间 0 < t < 1 又如何呢?事实证明,我们有一定的自由度来选择之间应该发生什么,这就是概率路径中数学形式化的结果。
下面,对于数据点 $z \in R^{d}$ ,我们用 $\delta_{z}$ 表示狄拉克 delta“分布”。这是人们可以想象的最简单的分布:从 $\delta_{z}$ 采样总是返回 z (即它是确定性的)。条件(插值)概率路径是 $p_{t}(x|z)$ 与 $R^{d}$ 上的一组分布,使得:
$$ p _ {0} (\cdot | z) = p _ {\text { init }}, \quad p _ {1} (\cdot | z) = \delta_ {z} \quad \text { for all } z \in \mathbb {R} ^ {d}. \tag {11} $$
换句话说,条件概率路径逐渐将初始分布 $p_{init}$ 转换为单个数据点(参见图 4)。您可以将概率路径视为分布空间中的轨迹。
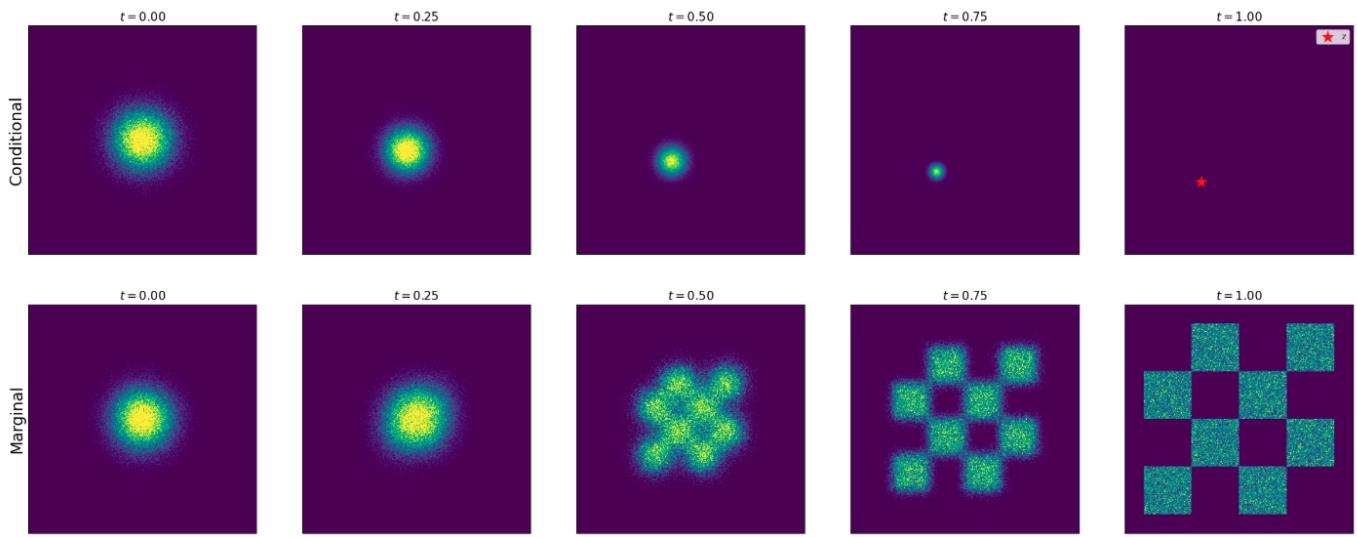
每个条件概率路径 $p_{t}(x|z)$ 都会产生一条边缘概率路径 $p_{t}(x)$ ,定义为我们通过首先从数据分布中采样数据点 $z \sim p_{data}$ ,然后从 $p_{t}(\cdot|z)$ 采样获得的分布:
$$ z \sim p _ {\text { data }}, \quad x \sim p _ {t} (\cdot | z) \quad \Rightarrow x \sim p _ {t} \quad \blacktriangleright \text { sampling from marginal path } \tag {12} $$
$$ p _ {t} (x) = \int p _ {t} (x | z) p _ {\text { data }} (z) \mathrm{d} z \quad \blacktriangleright \text { density of marginal path } \tag {13} $$
请注意,我们知道如何从 $p_t$ 中采样,但我们不知道密度值 $p_t(x)$ ,因为积分很难处理(即我们实际上可以计算方程(12),但不能计算方程(13))。自己检查一下,由于等式 (11) 中 $p_t(\cdot |z)$ 的条件,边缘概率路径 $p_t$ 在 $p_{\mathrm{init}}$ 和 $p_{\mathrm{data}}$ 之间插值:
$$ p _ {0} = p _ {\text { init }} \quad \text { and } \quad p _ {1} = p _ {\text { data }}. \quad \blacktriangleright \quad \text { noise - data interpolation } \tag {14} $$
到目前为止,概率路径最重要的示例是高斯概率路径,因此,我们强烈建议仔细阅读下一个示例。
示例 8(高斯条件概率路径)
一种特别流行的概率路径是高斯概率路径。这是大多数最先进模型使用的概率路径。令 $\alpha_{t}, \beta_{t}$ 为噪声调度程序:两个具有 $\alpha_{0} = \beta_{1} = 0$ 和 $\alpha_{1} = \beta_{0} = 1$ 的连续可微分、单调函数。然后我们定义条件概率路径
$$ p _ {t} (\cdot | z) = \mathcal {N} \left(\alpha_ {t} z, \beta_ {t} ^ {2} I _ {d}\right) \quad \triangleright \text {Gaussian conditional path} \tag {15} $$
根据我们对 $\alpha_{t}$ 和 $\beta_{t}$ 施加的条件,满足
$$ p _ {0} (\cdot | z) = \mathcal {N} (\alpha_ {0} z, \beta_ {0} ^ {2} I _ {d}) = \mathcal {N} (0, I _ {d}), \quad \mathrm{and} \quad p _ {1} (\cdot | z) = \mathcal {N} (\alpha_ {1} z, \beta_ {1} ^ {2} I _ {d}) = \delta_ {z}, $$
我们使用了这样一个事实:方差为零且均值 z 的正态分布就是 $\delta_{z}$ 。因此,$p_{t}(x|z)$ 的选择满足 $p_{\mathrm{init}} = \mathcal{N}(0, I_{d})$ 的方程 (11),因此是有效的条件插值路径。在图 4 中,我们说明了其在图像中的应用。我们可以将边际路径 $p_{t}$ 的采样表示为:
$$ z \sim p _ {\mathrm{data}}, \epsilon \sim p _ {\mathrm{init}} = \mathcal {N} (0, I _ {d}) \Rightarrow x = \alpha_ {t} z + \beta_ {t} \epsilon \sim p _ {t} \quad \triangleright \text { sampling from marginal Gaussian path } \tag {16} $$
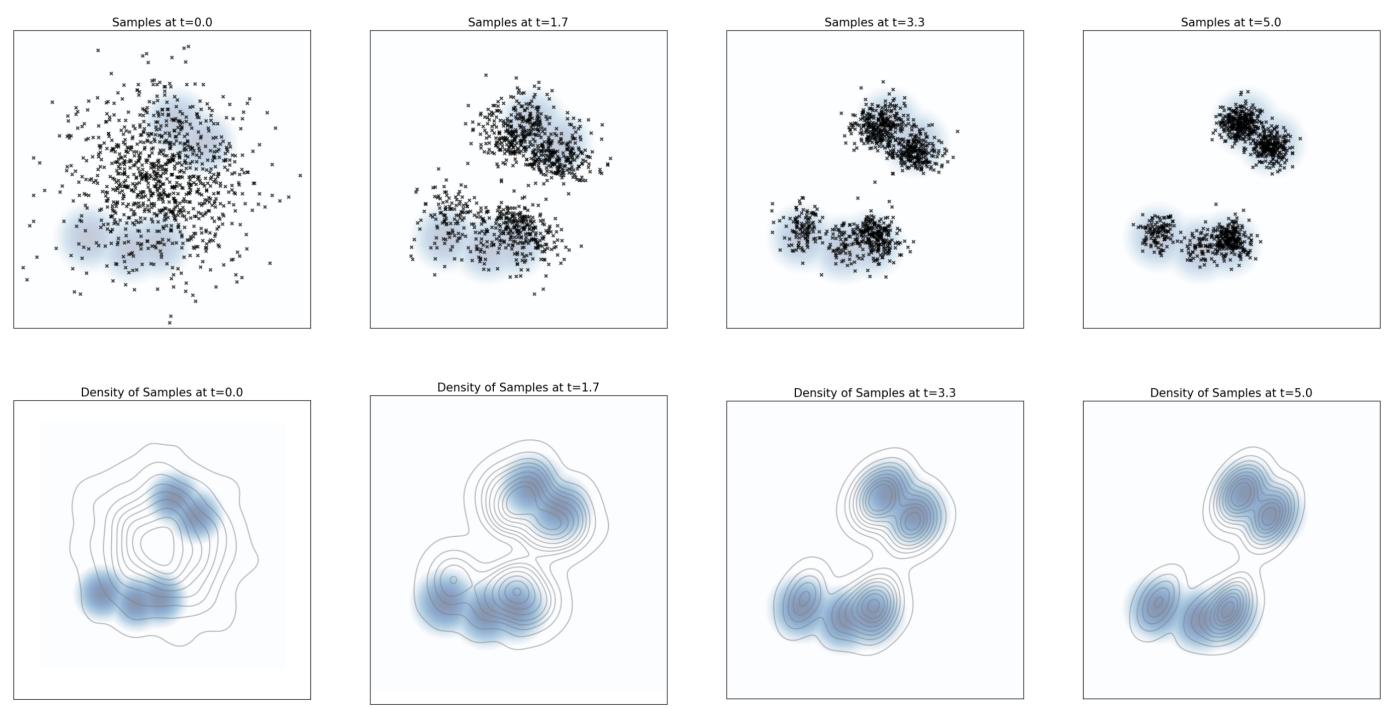
直观上,上述过程会为较低的 t 添加更多噪声,直到时间 t = 0,此时只有噪声。在图 5 中,我们绘制了此类插值路径的示例。
3.2 条件向量场和边缘向量场
概率路径 $(p_{t})_{0\leq t\leq1}$ 指定什么分布 $X_{t}\sim p_{t}$ 点 $X_{t}$ 沿着应该有的轨迹。在这一点上,这正是我们“希望”的情况。但是我们怎样才能找到一个矢量场使得轨迹 $X_{t}$ 遵循概率路径?流匹配显式地构造了这样一个向量场——“边缘向量场”——我们将在本节中对此进行解释。
对于每个数据点 $z \in R^{d}$ ,让 $u_{t}^{\mathrm{target}}(\cdot|z)$ 表示条件向量场。这可以是任何向量场,使得相应的 ODE 产生条件概率路径 $p_{t}(\cdot|z)$ ,即它保持
$$ X _ {0} \sim p _ {\text { init }}, \quad \frac {\mathrm{d}}{\mathrm{d} t} X _ {t} = u _ {t} ^ {\text { target }} (X _ {t} | z) \quad \Rightarrow \quad X _ {t} \sim p _ {t} (\cdot | z) \quad (0 \leq t \leq 1). \tag {17} $$
我们经常可以手动分析找到条件向量场 $u_{t}^{\mathrm{target}}(\cdot|z)$ (即通过我们自己做一些代数)。我们通过为示例 10 中的高斯概率路径运行示例导出条件向量场 $u_{t}(x|z)$ 来说明这一点。
乍一看,条件向量场似乎毫无用处,因为 ODE $X_{1}$ 的所有端点都会崩溃为 $X_{1} = z$ ,即我们只是重新生成已知数据点 z 。但是,条件向量场充当向量场的构建块,该向量场从 $p_{data}$ 生成实际样本:
定理9(边缘化技巧)
令 $u_{t}^{\mathrm{target}}(x|z)$ 为条件向量场(等式(17))。那么边缘向量场 $u_{t}^{\mathrm{target}}(x)$ 定义为
$$ u _ {t} ^ {\text { target }} (x) = \int u _ {t} ^ {\text { target }} (x | z) \frac {p _ {t} (x | z) p _ {\text { data }} (z)}{p _ {t} (x)} \mathrm{d} z, \tag {18} $$
遵循边缘概率路径,即
$$ X _ {0} \sim p _ {\text { init }}, \quad \frac {\mathrm{d}}{\mathrm{d} t} X _ {t} = u _ {t} ^ {\text { target }} (X _ {t}) \quad \Rightarrow \quad X _ {t} \sim p _ {t} \quad (0 \leq t \leq 1). \tag {19} $$
特别是,对于此 ODE,$X_{1} \sim p_{data}$,因此我们可以说“$u_{t}^{target}$ 将噪声 $p_{init}$ 转换为数据 $p_{data}$”。
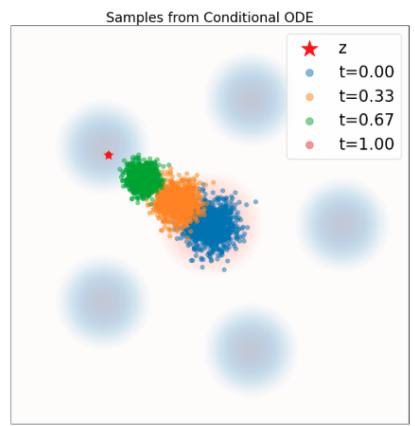
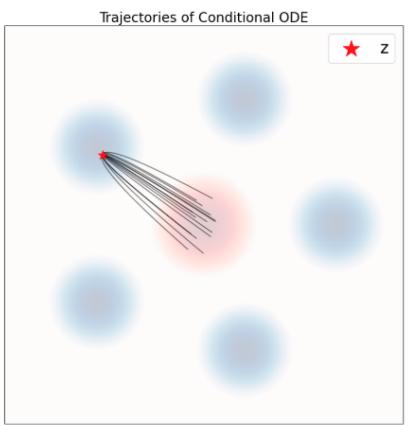
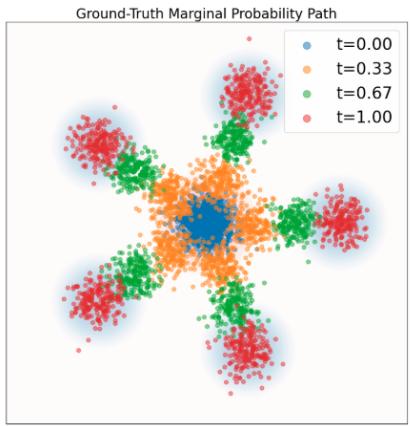
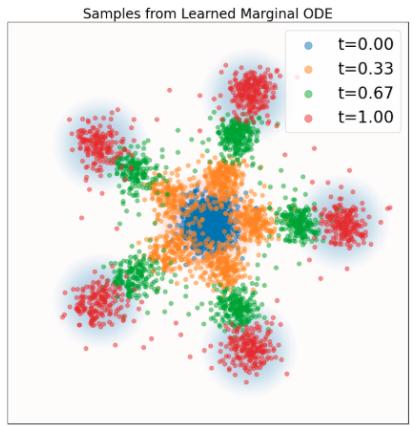
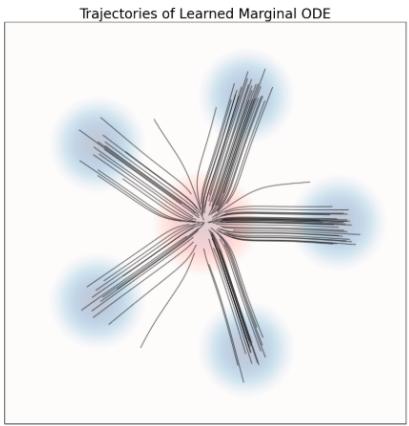
示例 10(高斯概率路径的目标 ODE)
与之前一样,让 $p_{t}(\cdot|z) = \mathcal{N}(\alpha_{t}z, \beta_{t}^{2}I_{d})$ 表示噪声调度器 $\alpha_{t}, \beta_{t}$(参见等式(15))。让 $\dot{\alpha}_{t} = \partial_{t}\alpha_{t}$ 和 $\dot{\beta}_{t} = \partial_{t}\beta_{t}$ 分别表示 $\alpha_{t}$ 和 $\beta_{t}$ 的时间导数。在这里,我们想要证明条件高斯向量场由下式给出
$$ u _ {t} ^ {\text { target }} (x | z) = \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z + \frac {\dot {\beta} _ {t}}{\beta_ {t}} x \tag {20} $$
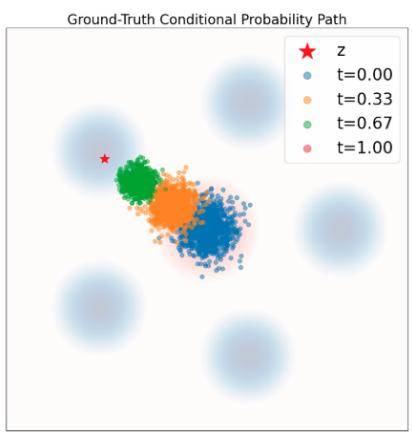
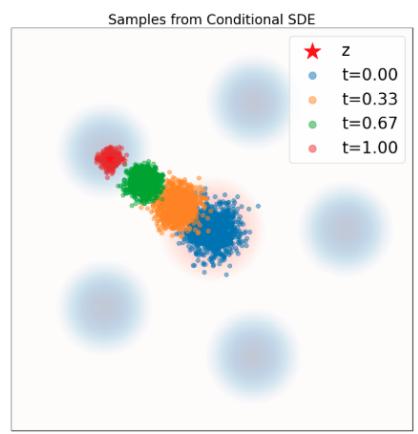
是定理 9 意义上的有效条件向量场模型:其 ODE 轨迹 $X_{t}$ 满足 $X_{t} \sim p_{t}(\cdot |z) = \mathcal{N}(\alpha_{t}z, \beta_{t}^{2}I_{d})$ 如果 $X_0 \sim \mathcal{N}(0, I_d)$ 。在图 6 中,我们通过比较条件概率路径(基本事实)中的样本与该流的模拟 ODE 轨迹中的样本来直观地确认这一点。如您所见,分布匹配。我们现在将证明这一点。
证明。让我们首先通过定义来构造一个条件流模型 $\psi_t^{\mathrm{target}}(x|z)$
$$ \psi_ {t} ^ {\text { target }} (x | z) = \alpha_ {t} z + \beta_ {t} x. \tag {21} $$
如果 $X_{t}$ 是 $\psi_t^{\mathrm{target}}(\cdot |z)$ 和 $X_0\sim p_{\mathrm{init}} = \mathcal{N}(0,I_d)$ 的 ODE 轨迹,则根据定义
$$ X _ {t} = \psi_ {t} ^ {\mathrm{target}} (X _ {0} | z) = \alpha_ {t} z + \beta_ {t} X _ {0} \sim \mathcal {N} (\alpha_ {t} z, \beta^ {2} I _ {d}) = p _ {t} (\cdot | z). $$
我们得出结论,轨迹的分布类似于条件概率路径(即满足方程(17))。剩下的就是提取向量场 $u_{t}^{\mathrm{target}}(x|z)$ 从 $\psi_{t}^{\mathrm{target}}(x|z)$ 。根据流的定义(方程(2b)),它成立
$$ \frac {\mathrm{d}}{\mathrm{d} t} \psi_ {t} ^ {\mathrm{target}} (x | z) = u _ {t} ^ {\mathrm{target}} (\psi_ {t} ^ {\mathrm{target}} (x | z) | z) \quad \mathrm{forall} x, z \in \mathbb {R} ^ {d} $$
$$ \stackrel {(i)} {\Leftrightarrow} \quad \dot {\alpha} _ {t} z + \dot {\beta} _ {t} x = u _ {t} ^ {\text { target }} (\alpha_ {t} z + \beta_ {t} x | z) \quad \text { for all } x, z \in \mathbb {R} ^ {d} $$
$$ \stackrel {(i i)} {\Leftrightarrow} \quad \dot {\alpha} _ {t} z + \dot {\beta} _ {t} \left(\frac {x - \alpha_ {t} z}{\beta_ {t}}\right) = u _ {t} ^ {\text { target }} (x | z) \quad \text { for all } x, z \in \mathbb {R} ^ {d} $$
$$ \stackrel {(i i i)} {\Leftrightarrow} \quad \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z + \frac {\dot {\beta} _ {t}}{\beta_ {t}} x = u _ {t} ^ {\text { target }} (x | z) \quad \text { for all } x, z \in \mathbb {R} ^ {d} $$
其中,在 (i) 中我们使用了 $\psi_{t}^{\mathrm{target}}(x|z)$ 的定义(方程 (21)),在 (ii) 中我们重新参数化了 $x \to (x - \alpha_{t}z)/\beta_{t}$ ,在 (iii) 中我们只是做了一些代数。请注意,最后一个方程是我们在方程(20)中定义的条件高斯向量场。这就证明了这个说法。 $^{a}$
请参见图 6 来了解定理 9 的说明。让我们对边缘向量场有一些直观的了解。统计学中的贝叶斯规则表示以下术语描述后验分布
$$ \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} = \text {"posterior over data points z given noisy data x"} $$
其中 $p_{\mathrm{data}}(z)$ 是先验分布。边缘向量场只是一个平均值:对于每个可能的数据点 z,它采用速度 $u_{t}(x|z)$ - 即将我们带到 z 的方向 - 然后根据我们相信 x 来自 z 的程度来衡量该速度。对所有数据点进行平均,我们获得边缘向量场。
本节的其余部分将使这种直觉变得严格并证明定理 9。作为主要的数学工具,我们将使用连续性方程,这是数学和物理中的基本方程。将散度算子 div 定义为
$$ \operatorname{div} (v _ {t}) (x) = \sum_ {i = 1} ^ {d} \frac {\partial}{\partial x _ {i}} v _ {t} ^ {i} (x) \tag {22} $$
其中 $v_{t}^{i}$ 是 $v_{t}$ 的第 i 个坐标。
定理11(连续性方程)
让我们考虑一个具有向量场 $u_{t}^{\mathrm{target}}$ 和 $X_0 \sim p_{\mathrm{init}} = p_0$ 的流模型。然后 $X_{t} \sim p_{t}$ 对于所有 $0 \leq t \leq 1$ 当且仅当
$$ \partial_ {t} p _ {t} (x) = - \operatorname{div} (p _ {t} u _ {t} ^ {\text { target }}) (x) \quad \text { for all } x \in \mathbb {R} ^ {d}, 0 \leq t \leq 1, \tag {23} $$
其中 $\partial_{t}p_{t}(x)=\frac{\mathrm{d}}{\mathrm{d}t}p_{t}(x)$ 表示 $p_{t}(x)$ 的时间导数。方程 23 称为连续性方程。
对于喜欢数学的读者,我们在 B 节中提出了连续性方程的独立证明。在继续之前,让我们尝试直观地理解连续性方程。左侧 $\partial_{t}p_{t}(x)$ 描述了 x 处的概率 $p_{t}(x)$ 随时间变化的程度。直观上,这种变化应该对应于概率质量的净流入。对于流模型,粒子 $X_{t}$ 沿着矢量场 $u_{t}^{target}$ 移动。正如您可能还记得物理学中的那样,散度衡量的是矢量场的一种净流出。因此,负背离衡量的是净流入。通过当前位于 x 的总概率质量来缩放,我们得到网络 $-\mathrm{div}(p_{t}u_{t})$ 测量概率质量的总流入。由于概率质量是守恒的(总是积分为 1),所以等式的左边和右边应该是相同的!现在我们继续证明定理 9 中的边缘化技巧。
定理 9 的证明。根据定理 11,我们必须证明边缘向量场 $u_{t}^{target}$ (如方程(18)中定义)满足连续性方程。我们可以通过直接计算来做到这一点:
$$ \begin{array}{l} \partial_ {t} p _ {t} (x) \stackrel {(i)} {=} \partial_ {t} \int p _ {t} (x | z) p _ {\mathrm{data}} (z) \mathrm{d} z = \int \partial_ {t} p _ {t} (x | z) p _ {\mathrm{data}} (z) \mathrm{d} z \\ \stackrel {(i i)} {=} \int - \operatorname{div} (p _ {t} (\cdot | z) u _ {t} ^ {\text { target }} (\cdot | z)) (x) p _ {\text { data }} (z) \mathrm{d} z \\ \stackrel {(i i i)} {=} - \operatorname{div} \left(\int p _ {t} (x | z) u _ {t} ^ {\text { target }} (x | z) p _ {\text { data }} (z) \mathrm{d} z\right) \\ \stackrel {(i v)} {=} - \operatorname{div} \left(p _ {t} (x) \int u _ {t} ^ {\text { target }} (x | z) \frac {p _ {t} (x | z) p _ {\text { data }} (z)}{p _ {t} (x)} \mathrm{d} z\right) (x) \\ \stackrel {(v)} {=} - \operatorname{div} \left(p _ {t} u _ {t} ^ {\text { target }}\right) (x), \\ \end{array} $$
在 (i) 中我们使用了定义 $p_{t}(x)$ 在方程(12)中,在(ii)中我们使用条件概率路径的连续性方程 $p_{t}(\cdot|z)$ ,在 (iii) 中我们使用方程 (22) 交换积分和散度运算符,在 (iv) 中我们乘以并除以 $p_{t}(x)$ ,在 (v) 中我们使用方程 (18)。上述方程链的开头和结尾表明连续性方程满足 $u_{t}^{target}$ 。根据定理 11,这足以暗示方程(19),我们就完成了。
3.3 学习边缘向量场
现在,我们准备好描述训练算法。流匹配的目标是训练神经网络 $u_{t}^{\theta}$ ,使其等于边缘向量场 $u_{t}^{\mathrm{target}}$ 。如果这个成立,我们知道端点 $X_{1} \sim p_{\mathrm{data}}$ 具有定理 9 所期望的分布。在下面,我们用 $\mathrm{Unif} = \mathrm{Unif}_{[0,1]}$ 表示区间 [0,1] 上的均匀分布,并用 $\mathbb{E}$ 表示随机变量的期望值。获得 $u_{t}^{\theta} \approx u_{t}^{\mathrm{target}}$ 的直观方法是使用均方误差,即使用定义为的流匹配损失
$$ \mathcal {L} _ {\mathrm{FM}} (\theta) = \mathbb {E} _ {t \sim \text {Unif}, x \sim p _ {t}} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\text {target}} (x) \| ^ {2} ] \tag {24} $$
$$ \stackrel {(i)} {=} \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\text {target}} (x) \| ^ {2} ], \tag {25} $$
其中 $p_{t}(x)=\int p_{t}(x|z)p_{\mathrm{data}}(z)\mathrm{d}z$ 是边缘概率路径,在 (i) 中我们使用等式 (12) 给出的采样过程。直观上,这个损失表示:首先,绘制一个随机时间 $t\in[0,1]$ 。其次,从我们的数据集中抽取一个随机点 z,从 $p_{t}(\cdot|z)$ 中采样(例如,通过添加一些噪声),并计算 $u_{t}^{\theta}(x)$ 。最后,计算神经网络的输出与边缘向量场 $u_{t}^{\mathrm{target}}(x)$ 之间的均方误差。不幸的是,我们还没有完成。虽然我们确实知道定理 9 的 $u_{t}^{target}$ 公式,但我们无法有效地计算它,因为积分很棘手。相反,我们将利用条件速度场 $u_{t}^{\mathrm{target}}(x|z)$ 易于处理的事实。为此,我们定义条件流匹配损失
$$ \mathcal {L} _ {\mathrm{CFM}} (\theta) = \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\text {target}} (x | z) \| ^ {2} ]. \tag {26} $$
请注意等式 (24) 的区别:我们使用条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ 而不是边缘向量 $u_{t}^{\mathrm{target}}(x)$ 。由于我们有 $u_{t}^{\mathrm{target}}(x|z)$ 的解析公式,我们可以轻松地最小化上述损失。但是等等,如果我们关心的是边缘向量场,那么对条件向量场进行回归有什么意义呢?事实证明,通过显式地回归易处理的条件向量场,我们隐式地回归了难处理的边缘向量场。下一个结果使这种直觉更加精确。
定理12
边际流匹配损失等于条件流匹配损失,直到一个常数。那是,
$$ \mathcal {L} _ {\mathrm{FM}} (\theta) = \mathcal {L} _ {\mathrm{CFM}} (\theta) + C, $$
其中 C 独立于 $\theta$ 。因此,它们的梯度一致:
$$ \nabla_ {\theta} \mathcal {L} _ {\mathrm{FM}} (\theta) = \nabla_ {\theta} \mathcal {L} _ {\mathrm{CFM}} (\theta). $$
因此,最小化 $\mathcal{L}_{\mathrm{CFM}}(\theta)$ 例如,随机梯度下降(SGD)相当于最小化 $\mathcal{L}_{\mathrm{FM}}(\theta)$ 以同样的方式。特别是对于最小化器 $\theta^{*}$ 的 $\mathcal{L}_{\mathrm{CFM}}(\theta)$ ,它将保持 $u_{t}^{\theta^{*}} = u_{t}^{target}$ ,即神经网络将等于边缘向量场(假设无限表达参数化)。
直接证明。该证明的工作原理是将均方误差扩展为三个分量并删除常数:
$$ \begin{array}{l} \mathcal {L} _ {\mathrm{FM}} (\theta) \stackrel {(i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, x \sim p _ {t}} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\mathrm{target}} (x) \| ^ {2} ] \\ \stackrel {(i i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, x \sim p _ {t}} [ \| u _ {t} ^ {\theta} (x) \| ^ {2} - 2 u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\mathrm{target}} (x) + \| u _ {t} ^ {\mathrm{target}} (x) \| ^ {2} ] \\ \stackrel {(i i i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, x \sim p _ {t}} \left[ \| u _ {t} ^ {\theta} (x) \| ^ {2} \right] - 2 \mathbb {E} _ {t \sim \mathrm{Unif}, x \sim p _ {t}} [ u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\mathrm{target}} (x) ] + \underbrace {\mathbb {E} _ {t \sim \mathrm{Unif} _ {[ 0 , 1 ]} , x \sim p _ {t}} [ \| u _ {t} ^ {\mathrm{target}} (x) \| ^ {2} ]} _ {=: C _ {1}} \\ \stackrel {(i v)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) \| ^ {2} ] - 2 \mathbb {E} _ {t \sim \mathrm{Unif}, x \sim p _ {t}} [ u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\mathrm{target}} (x) ] + C _ {1} \\ \end{array} $$
其中 (i) 根据定义成立,在 (ii) 中我们使用公式 $\|a-b\|^{2}=\|a\|^{2}-2a^{T}b+\|b\|^{2}$ ,在 (iii) 中我们定义常数 $C_{1}$ ,在 (iv) 中我们使用方程 (12) 给出的 $p_{t}$ 采样过程。让我们重新表达第二个被加数:
$$ \begin{array}{l} \mathbb {E} _ {t \sim \text { Unif }, x \sim p _ {t}} [ u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\text { target }} (x) ] \stackrel {(i)} {=} \int_ {0} ^ {1} \int p _ {t} (x) u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\text { target }} (x) \mathrm{d} x \mathrm{d} t \\ \stackrel {(i i)} {=} \int_ {0} ^ {1} \int p _ {t} (x) u _ {t} ^ {\theta} (x) ^ {T} \left[ \int u _ {t} ^ {\text { target }} (x | z) \frac {p _ {t} (x | z) p _ {\text { data }} (z)}{p _ {t} (x)} \mathrm{d} z \right] \mathrm{d} x \mathrm{d} t \\ \stackrel {(i i i)} {=} \int_ {0} ^ {1} \int \int u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\text { target }} (x | z) p _ {t} (x | z) p _ {\text { data }} (z) \mathrm{d} z \mathrm{d} x \mathrm{d} t \\ \stackrel {(i v)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} [ u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\mathrm{target}} (x | z) ] \\ \end{array} $$
其中,在 (i) 中,我们将期望值表示为积分,在 (ii) 中,我们使用方程 (18),在 (iii) 中,我们使用积分是线性的这一事实,在 (iv) 中,我们将积分表示为期望值。请注意,这确实是证明的关键步骤:等式的开头使用边缘向量场 $u_{t}^{\mathrm{target}}(x)$ ,而结尾使用条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ 。我们将 代入 $L_{FM}$ 的等式中,得到:
$$ \begin{array}{l} \mathcal {L} _ {\mathrm{FM}} (\theta) \stackrel {(i)} {=} \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) \| ^ {2} ] - 2 \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, x \sim p _ {t} (\cdot | z)} [ u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\text {target}} (x | z) ] + C _ {1} \\ \stackrel {(i i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) \| ^ {2} - 2 u _ {t} ^ {\theta} (x) ^ {T} u _ {t} ^ {\mathrm{target}} (x | z) + \| u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2} - \| u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2} ] + C _ {1} \\ \stackrel {(i i i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2} ] + \underbrace {\mathbb {E} _ {t \sim \mathrm{Unif} , z \sim p _ {\mathrm{data}} , x \sim p _ {t} (\cdot | z)} [ - \| u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2} ]} _ {C _ {2}} + C _ {1} \\ \stackrel {(i v)} {=} \mathcal {L} _ {\mathrm{CFM}} (\theta) + \underbrace {C _ {2} + C _ {1}} _ {=: C} \\ \end{array} $$
其中,在 (i) 中我们代入导出的方程,在 (ii) 中我们添加和减去相同的值,在 (iii) 中我们再次使用公式 $\|a-b\|^{2}=\|a\|^{2}-2a^{T}b+\|b\|^{2}$ ,在 (iv) 中我们在 $\theta$ 中定义一个常量。至此证明完毕。 ⑨
因此,流匹配训练包括最小化条件流匹配损失。算法 3 总结了训练过程,并在图 7 中进行了可视化。请注意,该算法有几个显着的特征:首先,我们在训练期间从未实际模拟任何 ODE。人们称算法的这一特点为免模拟。这使得训练变得非常便宜,因为您不必在训练期间推出 ODE 的轨迹(这需要很多步骤)。其次,训练是一个简单的回归目标 - 我们只是针对 $u_{t}^{\text{target}}(x|z)$ 进行回归。所以它和监督学习毕竟没有太大区别。最后,该算法非常简单——很难想象有更简单的训练目标。所有这些使得流匹配成为大规模机器学习模型中极具吸引力的方法。一旦 $u_{t}^{\theta}$ 被训练,我们就可以模拟流模型
$$ \mathrm{d} X _ {t} = u _ {t} ^ {\theta} (X _ {t}) \mathrm{d} t, \quad X _ {0} \sim p _ {\text { init }} \tag {27} $$
例如通过算法 1 获取样本 $X_{1} \sim p_{data}$ 。这整个管道在文献 [25, 27, 1, 26] 中称为流匹配。现在让我们实例化高斯概率路径的条件流匹配损失:
算法 3 流匹配训练程序(针对高斯 CondOT 路径 $p_t(x|z) = \mathcal{N}(tz, (1 - t)^2)$ )
要求:样本数据集 $z \sim p_{\mathrm{data}}$ ,神经网络 $u_t^\theta$
1:对于每个小批量数据做
2:从数据集中采样数据示例 z。
3:采样随机时间 $t \sim \mathrm{Unif}_{[0,1]}$ 。
4:样本噪声$\epsilon \sim \mathcal{N}(0, I_d)$
5:设置
$$ x = t z + (1 - t) \epsilon $$
(一般情况: $x \sim p_t(\cdot | z)$ )
6:计算损失
$$ \mathcal {L} (\theta) = \left\| u _ {t} ^ {\theta} (x) - (z - \epsilon) \right\| ^ {2} $$
(一般情况:$= \| u_t^\theta (x) - u_t^{\mathrm{target}}(x|z)\| ^2)$
7:更新 $\theta \leftarrow \mathrm{grad\_update}(\mathcal{L}(\theta))$ 。
8:结束
示例 13(高斯条件概率路径的流匹配)
让我们回到高斯概率路径 $p_{t}(\cdot|z) = \mathcal{N}(\alpha_{t}z; \beta_{t}^{2}I_{d})$ 的例子,我们可以通过以下方式从条件路径中采样
$$ \epsilon \sim \mathcal {N} (0, I _ {d}) \quad \Rightarrow \quad x _ {t} = \alpha_ {t} z + \beta_ {t} \epsilon \sim \mathcal {N} (\alpha_ {t} z, \beta_ {t} ^ {2} I _ {d}) = p _ {t} (\cdot | z). \tag {28} $$
正如我们在方程 (20) 中推导的那样,条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ 由下式给出
$$ u _ {t} ^ {\text { target }} (x | z) = \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z + \frac {\dot {\beta} _ {t}}{\beta_ {t}} x, \tag {29} $$
其中 $\dot{\alpha}_{t} = \partial_{t}\alpha_{t}$ 和 $\dot{\beta}_{t} = \partial_{t}\beta_{t}$ 是各自的时间导数。代入该公式,条件流匹配损失为
$$ \mathcal {L} _ {\mathrm{CFM}} (\theta) = \mathbb {E} _ {t \sim \text { Unif }, z \sim p _ {\text { data }}, x \sim \mathcal {N} \left(\alpha_ {t} z, \beta_ {t} ^ {2} I _ {d}\right)} [ \| u _ {t} ^ {\theta} (x) - \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z - \frac {\dot {\beta} _ {t}}{\beta_ {t}} x \| ^ {2} ] \tag {30} $$
$$ \stackrel {(i)} {=} \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, \epsilon \sim \mathcal {N} (0, I _ {d})} [ \| u _ {t} ^ {\theta} (\alpha_ {t} z + \beta_ {t} \epsilon) - (\dot {\alpha} _ {t} z + \dot {\beta} _ {t} \epsilon) \| ^ {2} ] \tag {31} $$
在 (i) 中,我们代入方程 (28) 并将 $x$ 替换为 $\alpha_{t}z + \beta_{t}\epsilon$ 。请注意 $\mathcal{L}_{\mathrm{CFM}}$ 的简单性:我们对数据点 $z$ 进行采样,对一些噪声 $\epsilon$ 进行采样,然后采用均方误差。让我们针对 $\alpha_{t} = t$ 和 $\beta_{t} = 1 - t$ 的特殊情况更加具体。相应的概率 $p_t(x|z) = \mathcal{N}(tz, (1 - t)^2)$ 有时称为(高斯)CondOT 概率路径。然后我们有 $\dot{\alpha}_{t} = 1, \dot{\beta}_{t} = -1$ ,这样
$$ \mathcal {L} _ {\mathrm{cfm}} (\theta) = \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, \epsilon \sim \mathcal {N} (0, I _ {d})} [ \| u _ {t} ^ {\theta} (t z + (1 - t) \epsilon) - (z - \epsilon) \| ^ {2} ] $$
许多著名的最先进模型都使用这种简单而有效的程序进行了训练,例如Stable Diffusion 3、Meta 的 Movie Gen Video,以及可能还有更多专有模型。在图 7 中,我们通过一个简单的示例对其进行了可视化,并在算法 3 中总结了训练过程。
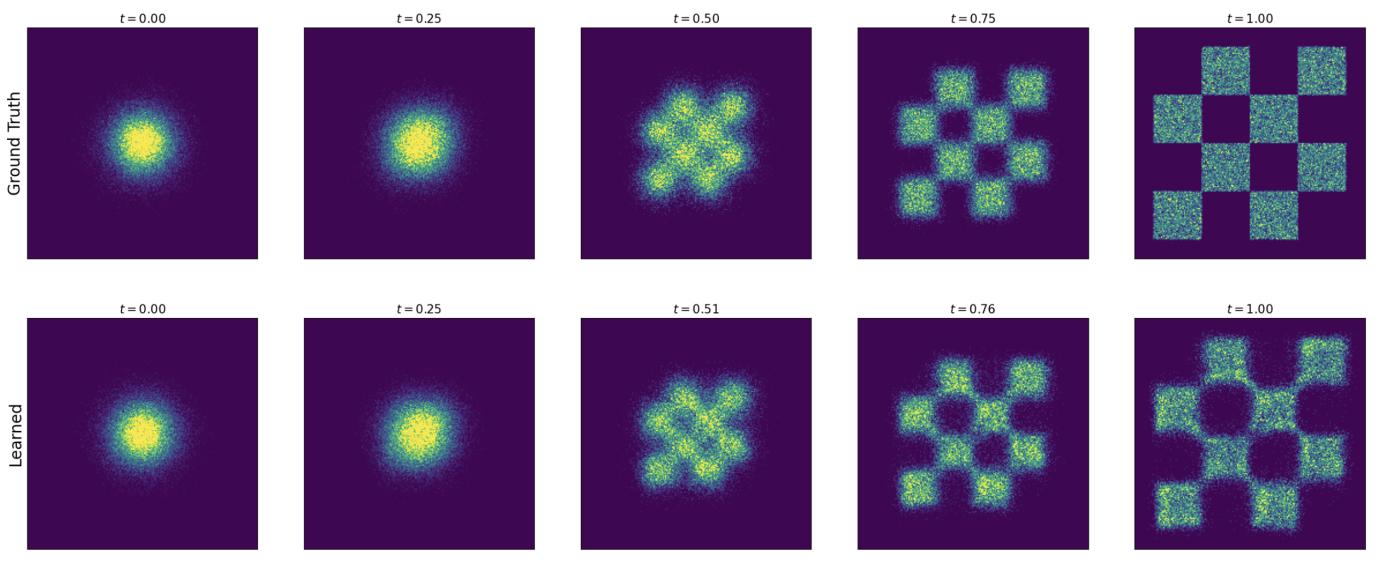
让我们总结一下本节的结果。
总结14(流匹配)
流匹配训练包括学习边缘向量场 $u_{t}^{target}$ 。为了构建它,我们选择一条条件概率路径 $p_{t}(x|z)$ 满足 $p_{0}(\cdot|z)=p_{\mathrm{init}}$ , $p_{1}(\cdot|z)=\delta_{z}$ 。接下来,我们找到一个条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ 使得其对应的流量 $\psi_{t}^{\mathrm{target}}(x|z)$ 满足
$$ X _ {0} \sim p _ {\mathrm{init}} \Rightarrow X _ {t} = \psi_ {t} ^ {\mathrm{target}} (X _ {0} | z) \sim p _ {t} (\cdot | z), $$
或者,等效地,$u_{t}^{target}$ 满足连续性方程。那么边缘向量场定义为
$$ u _ {t} ^ {\mathrm{target}} (x) = \int u _ {t} ^ {\mathrm{target}} (x | z) \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z, \tag {32} $$
遵循边缘概率路径,即
$$ X _ {0} \sim p _ {\mathrm{init}}, \quad \mathrm{d} X _ {t} = u _ {t} ^ {\mathrm{target}} (X _ {t}) \mathrm{d} t \Rightarrow X _ {t} \sim p _ {t} \quad (0 \leq t \leq 1). \tag {33} $$
特别是,该 ODE 的 $X_{1} \sim p_{data}$ ,以便 $u_{t}^{target}$ 根据需要“将噪声转换为数据”。为了学习它,我们最小化条件流匹配损失
$$ \mathcal {L} _ {\mathrm{CFM}} (\theta) = \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} [ \| u _ {t} ^ {\theta} (x) - u _ {t} ^ {\text {target}} (x | z) \| ^ {2} ]. \tag {34} $$
最广泛使用的例子是高斯概率路径。对于这种情况,公式变为:
$$ p _ {t} (x \mid z) = \mathcal {N} \left(x; \alpha_ {t} z, \beta_ {t} ^ {2} I _ {d}\right) \tag {35} $$
$$ u _ {t} ^ {\text { flow }} (x | z) = \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z + \frac {\dot {\beta} _ {t}}{\beta_ {t}} x \tag {36} $$
$$ \mathcal {L} _ {\mathrm{CFM}} (\theta) = \mathbb {E} _ {t \sim \text { Unif }, z \sim p _ {\text { data }}, \epsilon \sim \mathcal {N} (0, I _ {d})} [ \| u _ {t} ^ {\theta} (\alpha_ {t} z + \beta_ {t} \epsilon) - (\dot {\alpha} _ {t} z + \dot {\beta} _ {t} \epsilon) \| ^ {2} ] \tag {37} $$
对于噪声调度程序 $\alpha_{t},\beta_{t}\in \mathbb{R}$ ,即我们选择的连续可微的单调函数,使得 $\alpha_0 = \beta_1 = 0$ $\alpha_{1} = \beta_{0} = 1$ (例如 $\alpha_{t} = t,\beta_{t} = 1 - t$ )。
4 score 函数和score matching
在上一节中,我们展示了如何使用流匹配来训练流量模型。在本节中,我们讨论扩散模型并演示如何使用score matching来训练它们。
4.1 条件score 函数和边际score 函数
到目前为止,我们研究的中心目标是矢量场 $u_{t}(x)$ 。扩散模型 [45, 44] 采用不同的视角,重点关注score 函数。因此,在本节中,我们将用score 函数的语言重新表述我们在这里学到的内容——提供一个新颖的视角。令 $q(x)$ 为任意概率分布。然后 q 的得分函数定义为 $\nabla \log q(x)$ ,即 q 相对于 x 的对数似然的梯度。该分数具有直观的含义:$\nabla \log q(x)$ 是相对于对数似然而言最陡上升的方向。图 8 对此进行了说明。
$q(x)$
让我们回到条件的设置
假设概率路径 $p_{t}(x|z)$ 和边缘概率路径 $p_{t}(x)$ 如第 3 节所示。那么我们可以等价地将条件得分函数定义为 $\nabla \log p_{t}(x|z)$ ,将边际得分函数定义为 $\nabla \log p_{t}(x)$ 。与等式(18)类似,边际得分可以通过条件得分函数$\nabla \log p_{t}(x|z)$表示:
$$ \nabla \log p _ {t} (x) = \int \nabla \log p _ {t} (x | z) \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z. \tag {38} $$
因此,条件分数和边缘分数之间的关系类似于条件向量场和边缘向量场之间的关系。请注意,我们可以通过以下方式证明方程(38):
$$ \nabla \log p _ {t} (x) = \frac {\nabla p _ {t} (x)}{p _ {t} (x)} = \frac {\nabla \int p _ {t} (x | z) p _ {\mathrm{data}} (z) \mathrm{d} z}{p _ {t} (x)} = \frac {\int \nabla p _ {t} (x | z) p _ {\mathrm{data}} (z) \mathrm{d} z}{p _ {t} (x)} = \int \nabla \log p _ {t} (x | z) \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z, (3 9) $$
我们已经将规则 $\partial_{y}\log y=1/y$ 与链式法则结合使用了两次。
示例 15(高斯概率路径的score 函数。)
对于高斯路径 $p_t(x|z) = \mathcal{N}(x; \alpha_t z, \beta_t^2 I_d)$ ,我们可以使用高斯概率密度的形式(见式(97))得到
$$ \nabla \log p _ {t} (x | z) = \nabla \log \mathcal {N} (x; \alpha_ {t} z, \beta_ {t} ^ {2} I _ {d}) = - \frac {x - \alpha_ {t} z}{\beta_ {t} ^ {2}}. \tag {40} $$
请注意,高斯概率路径的得分函数是 x 和 z 的线性函数。对于条件向量场 $u_{t}(x|z)$ 也是如此(参见等式(20))。因此,可以在两者之间进行转换,如下一个命题所示。
命题1(高斯概率路径的转换公式)
对于高斯概率路径 $p_{t}(x|z)=\mathcal{N}(\alpha_{t}z,\beta_{t}^{2}I_{d})$ ,条件(或边际)向量场和条件(或边际)分数通过以下恒等式相关
$$ u _ {t} ^ {\text { target }} (x | z) = a _ {t} \nabla \log p _ {t} (x | z) + b _ {t} x, \quad a _ {t} = \left(\beta_ {t} ^ {2} \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} - \dot {\beta} _ {t} \beta_ {t}\right), \quad b _ {t} = \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} \tag {41} $$
$$ u _ {t} ^ {\text {target}} (x) = a _ {t} \nabla \log p _ {t} (x) + b _ {t} x. \tag {42} $$
特别是,我们注意到条件(或边际)向量场可以从条件(或边际)分数中恢复,反之亦然。
证明。对于条件向量场和条件分数,我们可以得出:
$$ u _ {t} ^ {\mathrm{target}} (x | z) = \left(\dot {\alpha} _ {t} - \frac {\dot {\beta} _ {t}}{\beta_ {t}} \alpha_ {t}\right) z + \frac {\dot {\beta} _ {t}}{\beta_ {t}} x \stackrel {(i)} {=} \left(\beta_ {t} ^ {2} \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} - \dot {\beta} _ {t} \beta_ {t}\right) \left(\frac {\alpha_ {t} z - x}{\beta_ {t} ^ {2}}\right) + \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} x = \left(\beta_ {t} ^ {2} \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} - \dot {\beta} _ {t} \beta_ {t}\right) \nabla \log p _ {t} (x | z) + \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} x $$
在 (i) 中我们刚刚做了一些代数。通过积分,边际流向量场和边际得分函数具有相同的恒等式:
$$ \begin{array}{l} u ^ {\mathrm{target}} (x) = \int u _ {t} ^ {\mathrm{target}} (x | z) \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z = \int [ a _ {t} \nabla \log p _ {t} (x | z) + b _ {t} x ] \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z \\ \stackrel {(i)} {=} a _ {t} \nabla \log p _ {t} (x) + b _ {t} x \\ \end{array} $$
其中 (i) 中我们使用了方程 (38) 以及后验密度积分为 1 的事实。
命题 1 很引人注目,因为它说一旦我们学会了 $u_{t}^{\mathrm{target}}$ ,我们也就学会了得分函数 $\nabla \log p_t(x)$ ,反之亦然。因此,许多扩散模型通过神经网络来学习score 函数 $\nabla \log p_t(x)$。我们将在 4.3 节中讨论这个问题。
备注 16(分数的重新参数化)
方程(41)中高斯概率路径的重新参数化公式是可能的,因为两边(条件向量场和条件分数)都是x和z的线性函数。一旦我们边缘化(边缘向量场和边缘分数),两边都只是后验平均值 $E_{z|x}[z]$ 的线性重新参数化。由此可见,任何允许恢复 $E_{z|x}[z]$ 的量都可以用来恢复无条件向量场和分数。此外,从数值/训练稳定性的角度来看,这样做甚至可能更可取。一种常见的选择是后验均值本身,通常称为降噪器。形式上,我们将条件和边际降噪器定义为
$$ D _ {t} (x | z) = z, \quad D _ {t} (x) = \int z \frac {p _ {t} (x | z) p _ {\mathrm{data}} (z)}{p _ {t} (x)} \mathrm{d} z \stackrel {(i)} {=} \frac {1}{\dot {\alpha} _ {t} \beta_ {t} - \alpha_ {t} \dot {\beta} _ {t}} (\beta_ {t} u _ {t} ^ {\mathrm{target}} (x _ {t}) - \dot {\beta} _ {t} x _ {t}). \tag {43} $$
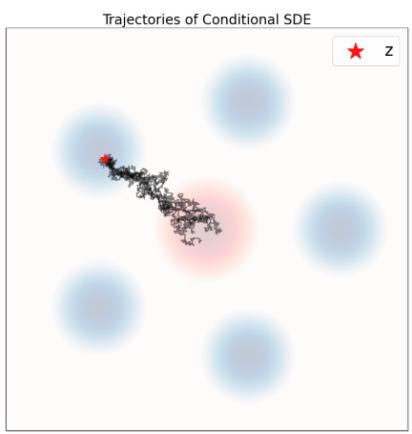
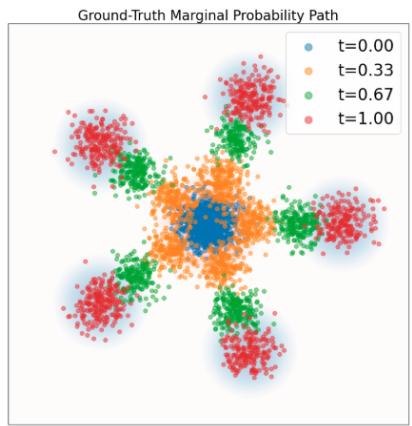
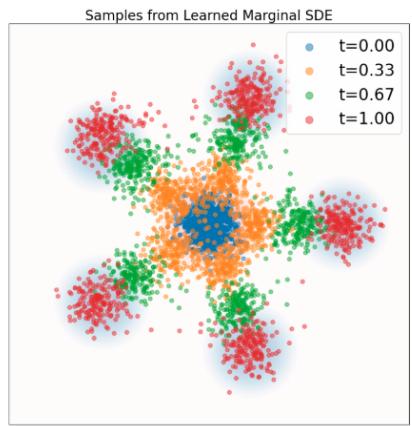
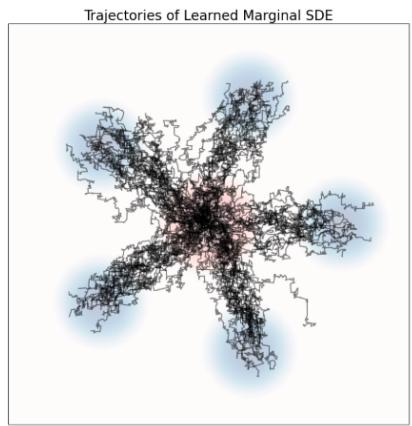
这里,(i) 是从命题 1 中的等价推导得出的。降噪器有一个非常直观的解释:它是给定噪声数据 $x.^{a}$ 的干净数据 z 的期望值。人们通常将此类模型称为去噪扩散模型,因为学习 $D_{t}$ 和学习 $u_{t}^{target}$ 理论上是等价的。
4.2 使用 SDE 进行采样
到目前为止,我们已经演示了如何构建轨迹 $X_{t}$ 遵循所需概率路径的 ODE $p_{t}$ 通过边缘向量场 $u_{t}^{target}$ 。但这种方法仅限于流模型。那么扩散模型呢?现在让我们使用score 函数将此结果扩展到 SDE。
定理 17(SDE 扩展技巧)
像以前一样定义条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ 和 $u_{t}^{\mathrm{target}}(x)$ 。然后,对于任何扩散系数 $\sigma_{t} \geq 0$ ,我们可以通过将随机动力学添加到原始 ODE 的动力学来构造 SDE,如下所示:
$$ X _ {0} \sim p _ {\mathrm{init}}, \quad \mathrm{d} X _ {t} = u _ {t} ^ {\text {target}} (X _ {t}) \mathrm{d} t + \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p _ {t} (X _ {t}) \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \tag {44} $$
$$ = \Big [ u _ {t} ^ {\mathrm{target}} (X _ {t}) + \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p _ {t} (X _ {t}) \Big ] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} $$
$$ \Rightarrow \quad X _ {t} \sim p _ {t} \quad (0 \leq t \leq 1). \tag {45} $$
特别是此 SDE 的 $X_{1} \sim p_{data}$。我们注意到,随机动力学与 Langevin 动力学密切相关,可以被认为是在保留边缘分布 $p_{t}$ 的同时注入噪声。我们在备注 20 中简要讨论了朗之万动力学。
我们在图 9 中说明了定理 17 中描述的动态。正如我们所看到的,轨迹现在是锯齿形的,说明了 SDE 演化的随机性质。然而,正如定理 17 所确定的那样,边际 $p_t$ 保持不变。请注意,上述结果令人震惊,因为即使在训练网络之后,我们也可以选择任何扩散系数 $\sigma_t \geq 0$。理论上,定理 17 对于 $\sigma_t$ 的任何选择都成立。然而,在实践中,我们同时遭受训练误差(神经网络不能完美地近似边缘向量场和分数)和模拟误差(例如,对于 $\sigma_t \gg 0$ ,我们需要在算法 2 中采取非常小的步长)。实际上,对于固定的训练模型,存在一个最优的 $\sigma_t \geq 0$,可以根据经验确定 [23, 1, 28]。 $^{2}$
对于高斯概率路径,我们通过学习边缘向量场免费获得得分函数。
示例 18(高斯 SDE 扩展技巧)
根据命题 1,对于高斯概率路径,我们可以纯粹使用得分函数来表达定理 17 的 SDE:
$$ X _ {0} \sim p _ {\text { init }}, \quad \mathrm{d} X _ {t} = \left[ \left(a _ {t} + \frac {\sigma_ {t} ^ {2}}{2}\right) \nabla \log p _ {t} (X _ {t}) + b _ {t} X _ {t} \right] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \tag {46} $$
$$ \Rightarrow X _ {t} \sim p _ {t} (0 \leq t \leq 1) \tag {47} $$
其中 $a_{t}, b_{t}$ 的定义如命题 1 中所示。
在本节的剩余部分中,我们将通过 Fokker-Planck 方程证明定理 17,该方程将连续性方程从 ODE 扩展到 SDE。为此,我们首先定义拉普拉斯算子 $\Delta$ 通过
$$ \Delta w _ {t} (x) = \sum_ {i = 1} ^ {d} \frac {\partial^ {2}}{\partial x _ {i} ^ {2}} w _ {t} (x) = \operatorname{div} (\nabla w _ {t}) (x), \tag {48} $$
对于标量场 $w_{t}: R^{d} \to R$ 。
定理 19(福克-普朗克方程)
令 $p_t$ 为概率路径,并考虑 SDE
$$ X _ {0} \sim p _ {\text { init }}, \quad \mathrm{d} X _ {t} = u _ {t} (X _ {t}) \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t}. $$
然后 $X_{t}$ 有分布 $p_{t}$ 为所有人 $0 \leq t \leq 1$ 当且仅当福克-普朗克方程成立:
$$ \partial_ {t} p _ {t} (x) = - \operatorname{div} (p _ {t} u _ {t}) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \quad \text { for all } x \in \mathbb {R} ^ {d}, 0 \leq t \leq 1, \tag {49} $$
Fokker-Planck 方程的独立证明可以在 B 节中找到。请注意,定理 11 在 $\sigma_t = 0$ 时从 Fokker-Planck 方程恢复。附加的拉普拉斯项 $\Delta p_t$ 一开始可能很难合理化。熟悉物理学的人会注意到,相同的术语也出现在热方程中(这实际上是福克-普朗克方程的一个特例)。热量通过介质扩散。我们还添加了一个扩散过程(不是物理的而是数学的),因此我们添加了这个额外的拉普拉斯项。现在让我们使用 Fokker-Planck 方程来帮助我们证明定理 17。
定理 17 的证明。根据定理 19,我们需要证明方程 (44) 中定义的 SDE 满足 $p_t$ 的 Fokker-Planck 方程。我们可以通过方向计算来做到这一点:
$$ \begin{array}{l} \partial_ {t} p _ {t} (x) \stackrel {(i)} {=} - \operatorname{div} (p _ {t} u _ {t} ^ {\text { target }}) (x) \\ \stackrel {(i i)} {=} - \operatorname{div} (p _ {t} u _ {t} ^ {\text { target }}) (x) - \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \\ \stackrel {(i i i)} {=} - \operatorname{div} (p _ {t} u _ {t} ^ {\text { target }}) (x) - \operatorname{div} (\frac {\sigma_ {t} ^ {2}}{2} \nabla p _ {t}) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \\ \stackrel {(i v)} {=} - \mathrm{div} (p _ {t} u _ {t} ^ {\mathrm{target}}) (x) - \mathrm{div} (p _ {t} \left[ \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p _ {t} \right]) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \\ \stackrel {(v)} {=} - \operatorname{div} \left(p _ {t} \left[ u _ {t} ^ {\text {target}} + \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p _ {t} \right]\right) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x), \\ \end{array} $$
其中,在 (i) 中我们使用定理 11,在 (ii) 中我们添加和减去相同的项,在 (iii) 中我们使用拉普拉斯算子的定义(方程 (48)),在 (iv) 中我们使用 $\nabla \log p_t = \frac{\nabla p_t}{p_t}$ ,在 (v) 中我们使用散度算子的线性。上述推导表明,方程(44)中定义的 SDE 满足 $p_t$ 的 Fokker-Planck 方程。根据定理 19,这意味着 $X_t \sim p_t$ 对应 $0 \leq t \leq 1$ ,根据需要。
备注20(可选:Langevin Dynamics)
当概率路径恒定时,上述结构有一个著名的特例,即 $p_t = p$ 对于固定分布 $p$ 。在这种情况下,我们设置 $u_t^{\mathrm{target}} = 0$ 并获得SDE
$$ \mathrm{d} X _ {t} = \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p (X _ {t}) \mathrm{d} t + \sigma_ {t} d W _ {t}, \tag {50} $$
这通常被称为朗之万动力学。 $p_{t}$ 是常量这一事实意味着 $\partial_{t}p_{t}(x)=0$ 。从定理 17 可以立即看出,这些动力学满足定理 17 中静态路径 $p_{t}=p$ 的 Fokker-Planck 方程。因此,我们可以得出结论,p 是 Langevin 动力学的平稳分布:
$$ X _ {0} \sim p \Rightarrow X _ {t} \sim p (t \geq 0). $$
与许多马尔可夫过程一样,这些动态在相当一般的条件下收敛到平稳分布 p。也就是说,如果我们采用 $X_{0} \sim p' \neq p$ ,那么 $X_{t} \sim p'_{t}$ ,然后在温和条件下 $p_{t} \to p$ 。这一事实使得朗之万动力学非常有用,因此它可以作为分子动力学模拟以及贝叶斯统计和自然科学中许多其他马尔可夫链蒙特卡罗 (MCMC) 方法的基础。特别是,当 p 为高斯分布时,Ornstein-Uhlenbeck 过程被恢复为 Langevin 动力学的特例,并作为扩散模型初始公式的基础。
备注 21(可选:GLASS 流、ODE 随机演化)
SDE 采样的显着特性(与 ODE 相比)是演化变得随机,即初始点 $X_{0}$ 不能完全确定 t > 0 时的 $X_{t}$。也许令人惊讶的是,也可以通过称为 GLASS Flows [20] 的简单采样技巧纯粹通过 ODE 获得相同的随机转变。这允许利用 SDE 的随机性质(例如通过搜索算法),同时保持 ODE 的效率。
4.3 Score Matching(得分匹配)
剩下的就是展示我们如何学习边际得分函数 $\nabla\log p_{t}(x)$ 。当然,对于高斯概率路径,我们可以通过命题1简单地变换$u_{t}^{\mathrm{target}}(x)$。但是,一般情况下呢?事实证明,我们也可以直接学习边际得分函数。为了近似边际分数 $\nabla\log p_{t}$ ,我们使用称为分数网络 $s_{t}^{\theta}:R^{d}\times[0,1]\to R^{d}$ 的神经网络。和之前一样,我们可以设计一个score matching损失和一个去噪score matching损失:
$$ \mathcal {L} _ {\mathrm{SM}} (\theta) = \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} \left[ \left\| s _ {t} ^ {\theta} (x) - \nabla \log p _ {t} (x) \right\| ^ {2} \right] $$
▶ score matching损失
$$ \mathcal {L} _ {\mathrm{CSM}} (\theta) = \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, x \sim p _ {t} (\cdot | z)} \left[ \left\| s _ {t} ^ {\theta} (x) - \nabla \log p _ {t} (x | z) \right\| ^ {2} \right] $$
▶ 条件score matching损失
区别再次在于使用边际分数 $\nabla \log p_t(x)$ 与使用条件分数 $\nabla \log p_t(x|z)$ 。和以前一样,理想情况下我们希望最小化score matching损失,但不能,因为我们不知道 $\nabla \log p_t(x)$ 。但与之前类似,去噪score matching损失是一个易于处理的替代方案:
定理22
score matching损失等于去噪score matching损失,最多为一个常数:
$$ \mathcal {L} _ {\mathrm{SM}} (\theta) = \mathcal {L} _ {\mathrm{CSM}} (\theta) + C, $$
其中 $C$ 独立于参数 $\theta$ 。因此,它们的梯度一致:
$$ \nabla_ {\theta} \mathcal {L} _ {\mathrm{SM}} (\theta) = \nabla_ {\theta} \mathcal {L} _ {\mathrm{CSM}} (\theta). $$
特别是,对于最小化器 $\theta^{*}$ ,它将保持 $s_{t}^{\theta^{*}} = \nabla \log p_{t}$ 。
证明。请注意,$\nabla\log p_{t}$ 的公式(公式 (38))与 $u_{t}^{target}$ 的公式(公式 (18))看起来相同。因此,该证明与定理 12 的证明相同,将 $u_{t}^{target}$ 替换为 $\nabla\log p_{t}$ 。 ⑨
示例23(去噪扩散模型:高斯概率路径的score matching)
让我们实例化 $p_{t}(x|z)=\mathcal{N}(\alpha_{t}z,\beta_{t}^{2}I_{d})$ 情况下的去噪score matching损失。正如我们在等式(40)中推导的那样,条件分数 $\nabla\log p_{t}(x|z)$ 的公式为
$$ \nabla \log p _ {t} (x | z) = - \frac {x - \alpha_ {t} z}{\beta_ {t} ^ {2}}. \tag {51} $$
代入该公式,条件score matching损失变为:
$$ \begin{array}{l} \mathcal {L} _ {\mathrm{CSM}} (\theta) = \mathbb {E} _ {t \sim \text {Unif}, z \sim p _ {\text {data}}, x \sim p _ {t} (\cdot | z)} \left[ \left\| s _ {t} ^ {\theta} (x) + \frac {x - \alpha_ {t} z}{\beta_ {t} ^ {2}} \right\| ^ {2} \right] \\ \stackrel {(i)} {=} \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, \epsilon \sim \mathcal {N} (0, I _ {d})} \left[ \left\| s _ {t} ^ {\theta} (\alpha_ {t} z + \beta_ {t} \epsilon) + \frac {\epsilon}{\beta_ {t}} \right\| ^ {2} \right] \\ = \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, \epsilon \sim \mathcal {N} (0, I _ {d})} \left[ \frac {1}{\beta_ {t} ^ {2}} \left\| \beta_ {t} s _ {t} ^ {\theta} (\alpha_ {t} z + \beta_ {t} \epsilon) + \epsilon \right\| ^ {2} \right] \\ \end{array} $$
在 (i) 中,我们代入方程 (28) 并将 x 替换为 $\alpha_{t}z + \beta_{t}\epsilon$ 。请注意,网络 $s_{t}^{\theta}$ 本质上是学习预测用于破坏数据样本 z 的噪声。这就解释了为什么上述训练损失被称为去噪score matching。人们很快意识到,对于接近于零的 $\beta_{t} \approx 0$ ,上述损失在数值上不稳定(即去噪score matching仅在添加足够量的噪声时才有效)。因此,在一些有关去噪扩散模型的首批工作中(参见去噪扩散概率模型,[17]),建议删除损失中的常量 $\frac{1}{\beta_{t}^{2}}$ 并将 $s_{t}^{\theta}$ 重新参数化为噪声预测器网络 $\epsilon_{t}^{\theta}: R^{d} \times [0, 1] \to R^{d}$:
$$ - \beta_ {t} s _ {t} ^ {\theta} (x) = \epsilon_ {t} ^ {\theta} (x) \quad \Rightarrow \quad \mathcal {L} _ {\mathrm{DDPM}} (\theta) = \mathbb {E} _ {t \sim \mathrm{Unif}, z \sim p _ {\mathrm{data}}, \epsilon \sim \mathcal {N} (0, I _ {d})} \left[ \| \epsilon_ {t} ^ {\theta} (\alpha_ {t} z + \beta_ {t} \epsilon) - \epsilon \| ^ {2} \right] $$
和以前一样,网络 $\epsilon_{t}^{\theta}$ 本质上是学习预测用于破坏数据样本 z 的噪声。在算法 4 中,我们总结了训练过程。
算法 4 高斯概率路径的score matching训练程序
要求:样本数据集 $z \sim p_{data}$ 、评分网络 $s_{t}^{\theta}$ 或噪声预测器 $\epsilon_{t}^{\theta}$ 1:对于每个小批量数据
2:从数据集中采样数据示例 z。
3:采样随机时间 $t \sim \operatorname{Unif}_{[0,1]}$ 。
4:采样噪声 $\epsilon \sim \mathcal{N}(0, I_{d})$ 5:设置 $x_{t} = \alpha_{t}z + \beta_{t}\epsilon$ (一般情况:$x_{t} \sim p_{t}(\cdot|z)$ )
6:计算损失$\mathcal{L}(\theta) = \|s_{t}^{\theta}(x_{t}) + \frac{\epsilon}{\beta_{t}}\|^{2}$(一般情况:$= \|s_{t}^{\theta}(x_{t}) - \nabla \log p_{t}(x_{t}|z)\|^{2}$)
或者: $\mathcal{L}(\theta) = \|\epsilon_{t}^{\theta}(x_{t}) - \epsilon\|^{2}$ 7:更新模型参数 $\theta$ 通过梯度下降 $\mathcal{L}(\theta)$ .
8:结束
让我们总结一下本节的结果:
摘要 24(score 函数、score matching和随机采样)
令 $p_t(x|z), p_t(x)$ 为条件和边缘概率路径。条件得分函数由 $\nabla \log p_t(x|z)$ 给出,边际得分函数由 $\nabla \log p_t(x)$ 给出。对于每个扩散系数 $\sigma_t \geq 0$ ,以下 SDE 的轨迹遵循概率路径:
$$ X _ {0} \sim p _ {\text {init}}, \quad \mathrm{d} X _ {t} = \left[ u _ {t} ^ {\text {target}} (X _ {t}) + \frac {\sigma_ {t} ^ {2}}{2} \nabla \log p _ {t} (X _ {t}) \right] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \tag {52} $$
$$ \Rightarrow X _ {t} \sim p _ {t} (0 \leq t \leq 1), \tag {53} $$
其中 $u_{t}^{\mathrm{target}}(x)$ 是之前的边缘向量场(参见方程(18))。
score matching。为了学习边际得分函数 $\nabla \log p_{t}(x)$ ,我们可以使用得分网络 $s_{t}^{\theta}$ 并通过去噪得分匹配来训练它
$$ \mathcal {L} _ {\mathrm{CSM}} (\theta) = \mathbb {E} _ {z \sim p _ {\mathrm{data}}, t \sim \text {Unif}, x \sim p _ {t} (\cdot | z)} [ \| s _ {t} ^ {\theta} (x) - \nabla \log p _ {t} (x | z) \| ^ {2} ] \quad \text {(denoising score matching loss)} \tag {54} $$
高斯概率路径。对于最重要的高斯概率路径 $p_{t}(x|z) = \mathcal{N}(x; \alpha_{t}z, \beta_{t}^{2}I_{d})$ 的情况,不需要单独训练 $s_{t}^{\theta}$ 和 $u_{t}^{\theta}$ ,因为我们可以通过以下公式转换它们:
$$ u _ {t} ^ {\theta} (x) = a _ {t} s _ {t} ^ {\theta} (x) + b _ {t} x, \quad a _ {t} = \left(\beta_ {t} ^ {2} \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} - \dot {\beta} _ {t} \beta_ {t}\right), b _ {t} = \frac {\dot {\alpha} _ {t}}{\alpha_ {t}} $$
训练完成后,我们可以模拟如下SDE
$$ X _ {0} \sim p _ {\text { init }}, \quad \mathrm{d} X _ {t} = \left[ \left(1 + \frac {\sigma_ {t} ^ {2}}{2 a _ {t}}\right) u _ {t} ^ {\theta} (X _ {t}) - \frac {\sigma_ {t} ^ {2} b _ {t}}{2 a _ {t}} X _ {t} \right] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \tag {55} $$
$$ = \left[ \left(a _ {t} + \frac {\sigma_ {t} ^ {2}}{2}\right) s _ {t} ^ {\theta} (X _ {t}) + b _ {t} X _ {t} \right] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t} \tag {56} $$
对于任何扩散系数 $\sigma_{t} \geq 0$ 以获得近似样本 $X_{1} \sim p_{data}$ 。人们可以根据经验找到最佳的 $\sigma_{t} \geq 0$ 。
5 引导:如何基于 prompt 条件化
到目前为止,我们考虑的生成式模型是无引导的,例如图像模型只会生成一些图像。从数学上来说,这意味着我们的模型从无条件数据分布 $p_{\mathrm{data}}(z)$ 返回样本。然而,在大多数情况下,我们的目标不仅仅是生成任意对象,而是生成以一些附加信息为条件的对象。换句话说,我们想要引导模型生成某种类型的对象。例如,人们可能会想象一种图像生成式模型,它接收文本prompt y,然后生成适合文本prompt y 的图像 x。正如第 1 节中所讨论的,这意味着我们想要从 $p_{\mathrm{data}}(z|y)$ 中采样,即以 y 为条件的引导数据分布。我们将在本节中讨论这个问题。
备注25(术语)
为了避免与使用“条件”一词来指代 $z \sim p_{data}$(条件概率路径/向量场)上的条件发生符号和术语冲突,我们将使用术语引导来专门指代 y 上的条件,例如文本prompt。
5.1 普通指南
首先,我们讨论如何构建引导生成式模型的“标准”方式。简短的答案如下:我们只需在训练和推理期间向网络提供输入prompt y,并以与之前相同的方式执行所有操作。我们在下面将其正式化。我们认为条件变量或prompt y 存在于空间 Y 中。例如,当 y 对应于文本prompt时,Y 是所有文本的空间。当 y 对应于某个离散类标签时,Y 将是离散的。我们对 Y 不施加任何限制。
我们定义一个引导扩散模型,由一个引导矢量场 $u_{t}^{\theta}(\cdot|y)$ 组成,由一些神经网络参数化,以及一个与时间相关的扩散系数 $\sigma_{t}$ ,共同由下式给出
$$ \text { Neural network: } u ^ {\theta}: \mathbb {R} ^ {d} \times \mathcal {Y} \times [ 0, 1 ] \to \mathbb {R} ^ {d}, (x, y, t) \mapsto u _ {t} ^ {\theta} (x | y) $$
$$ \mathbf {F i x e d}: \sigma_ {t}: [ 0, 1 ] \rightarrow [ 0, \infty), t \mapsto \sigma_ {t} $$
请注意与摘要 7 的区别:我们另外提供引导 $u_{t}^{\theta}$ 与输入 $y \in \mathcal{Y}$ 。对于任何此类 $y \in \mathcal{Y}$ ,然后可以从这样的模型生成样本,如下所示:
初始化:$X_{0} \sim p_{init}$
模拟:$\mathrm{d}X_{t}=u_{t}^{\theta}(X_{t}|y)\mathrm{d}t+\sigma_{t}\mathrm{d}W_{t}$
目标:$X_{1} \sim p_{\text{data}}(\cdot | y)$
▶ 使用简单分布(例如高斯分布)进行初始化
▶ 模拟从 t = 0 到 t = 1 的 SDE。
▶ 目标是 $X_{1}$ 像 $p_{\mathrm{data}}(\cdot|y)$ 一样分发。
当 $\sigma_{t}=0$ 时,我们说这样的模型是引导流模型。在下文中,我们将自己限制在流匹配和流模型上,以使事情更加简洁,但一切都适用于一般情况。
接下来,我们讨论:我们如何训练引导流模型$u_{t}^{\theta}(x|y)$?一个简单的技巧可能会修复我们对 y 的选择,并将我们的数据分布视为 $p_{\mathrm{data}}(x|y)$ 。然后我们像以前一样恢复了无引导生成问题,并且我们可以相应地使用条件流匹配目标构建生成式模型,即

$$ \mathbb {E} _ {z \sim p _ {\mathrm{data}} (\cdot | y), x \sim p _ {t} (\cdot | z)} \| u _ {t} ^ {\theta} (x | y) - u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2}. \tag {57} $$
请注意,标签 y 不会影响条件概率路径 $p_{t}(\cdot|z)$ 或条件向量场 $u_{t}^{\mathrm{target}}(x|z)$ (尽管原则上我们可以使其相关)。扩展对 y 的所有此类选择的期望,因此我们获得了引导条件流匹配目标
$$ \mathcal {L} _ {\mathrm{CFM}} ^ {\text { guided }} (\theta) = \mathbb {E} _ {(z, y) \sim p _ {\mathrm{data}} (z, y), t \sim \operatorname{Unif} [ 0, 1 ], x \sim p _ {t} (\cdot | z)} \| u _ {t} ^ {\theta} (x | y) - u _ {t} ^ {\text { target }} (x | z) \| ^ {2}. \tag {58} $$
等式(58)中的引导目标与等式(26)中的非引导目标之间的主要区别之一是,这里我们采样 $(z,y)\sim p_{\mathrm{data}}$ 而不仅仅是 $z\sim p_{data}$ 。原因是我们的数据分布现在原则上是图像 z 和文本prompt y 上的联合分布。实际上,这意味着方程 (58) 的 PyTorch 实现将涉及返回 z 和 y 批次的数据加载器。
5.2 无分类器引导
理论上,普通引导应该导致 $p_{\mathrm{data}}(\cdot|y)$ 的忠实生成过程。然而,很快就凭经验认识到,采用此过程的图像样本与所需标签 y 的拟合度不够好(见图 11)。这可能有多种原因:模型可能不适合(即我们实际上没有学习真正的边缘向量场)或者我们的数据可能不完美(例如来自万维网的文本图像对有很多错误)。因此,为了真正生成更适合prompt的样本,我们必须找到一种方法来人为地强化prompt变量y。这样做的主要技术称为无分类器引导,广泛应用于最先进的扩散模型中,我们将在接下来讨论。
分类器引导。为简单起见,我们将在这里重点关注高斯概率路径的情况。回顾等式 (15),高斯条件概率路径由下式给出 $p_{t}(\cdot|z)=\mathcal{N}(\alpha_{t}z,\beta_{t}^{2}I_{d})$ 噪声调度器在哪里 $\alpha_{t}$ 和 $\beta_{t}$ 连续可微、单调且满足 $\alpha_{0}=\beta_{1}=0$ 和 $\alpha_{1}=\beta_{0}=1$ 。此外,回想一下我们可以使用命题 1 重写引导向量场 $u_{t}^{\mathrm{target}}(x|y)$ 使用引导score 函数采用以下形式 $\nabla\log p_{t}(x|y)$
$$ u _ {t} ^ {\text { target }} (x | y) = a _ {t} \nabla \log p _ {t} (x | y) + b _ {t} x, \tag {59} $$
接下来,认识到 $p_t(x|y)$ 是条件密度。因此,我们可以使用贝叶斯规则将引导分数重写为
$$ p _ {t} (x \mid y) = \frac {p _ {t} (x) p _ {t} (y \mid x)}{p _ {t} (y)} \tag {60} $$
$$ \nabla \log p _ {t} (x | y) = \nabla \log \left(\frac {p _ {t} (x) p _ {t} (y | x)}{p _ {t} (y)}\right) = \nabla \log p _ {t} (x) + \nabla \log p _ {t} (y | x), \tag {61} $$
其中我们使用相对于变量 x 的梯度 $\nabla$ ,因此 $\nabla\log p_{t}(y)=0$ 。我们可以这样重写
$$ u _ {t} ^ {\mathrm{target}} (x | y) = b _ {t} x + a _ {t} (\nabla \log p _ {t} (x) + \nabla \log p _ {t} (y | x)) = u _ {t} ^ {\mathrm{target}} (x) + a _ {t} \nabla \log p _ {t} (y | x). $$
注意上面方程的形状:引导向量场 $u_{t}^{\mathrm{target}}(x|y)$ 是非引导向量场 $u_{t}^{\mathrm{target}}(x)$ 加上引导变量 y 的似然度 $p_{t}(y|x)$ 的梯度之和。当人们观察到他们的图像 x 与他们的prompt y 不太相符时,扩大 $\nabla\log p_{t}(y|x)$ 项的贡献是一个自然的想法,产生
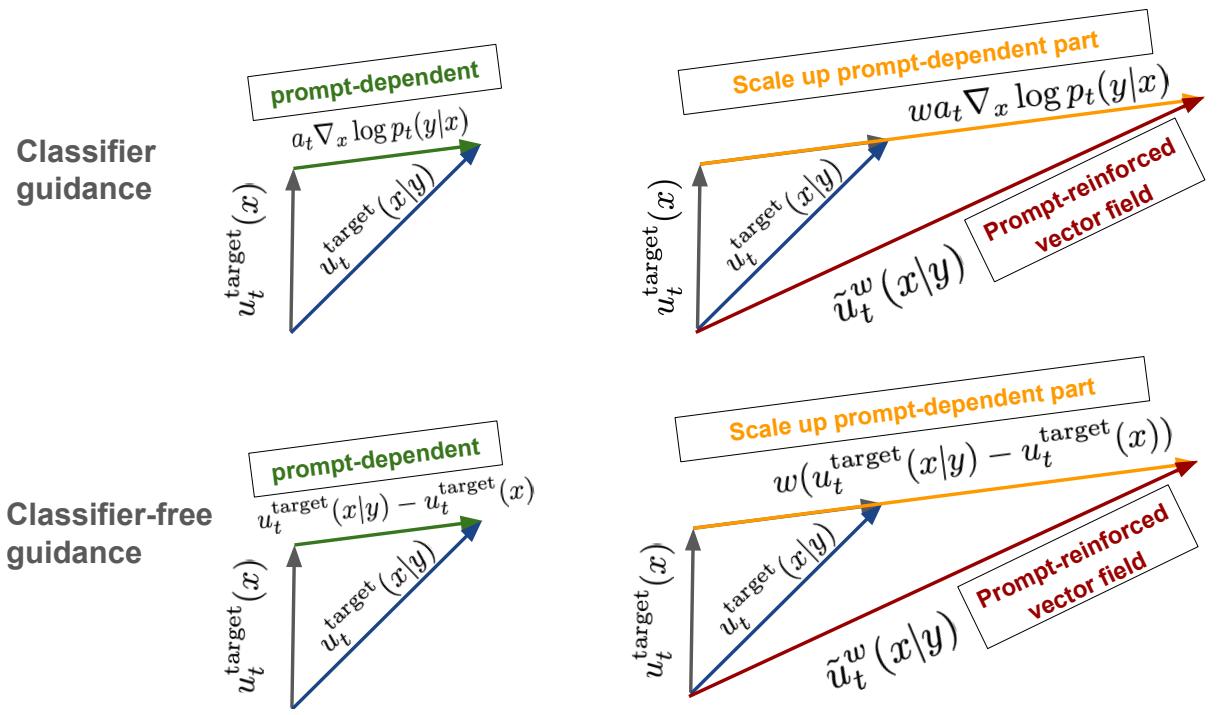
$$ \tilde {u} _ {t} (x | y) = u _ {t} ^ {\text { target }} (x) + w a _ {t} \nabla \log p _ {t} (y | x), \quad (\text { classifier guidance }) \tag {62} $$
其中 w > 1 称为引导尺度。我们如何学习术语 $\log p_{t}(y|x)$ ?请注意,这可以被视为噪声数据的一种分类器(即,它给出给定 x 的 y 的对数似然)。所以我们可以简单地通过监督学习来学习它。这导致分类器引导 [11, 43] (参见图 12 的说明)。分类器引导很大程度上被无分类器引导所取代,这就是为什么我们不会在这里进一步讨论它。然而,正如我们接下来将看到的,它构成了无分类器引导的基础。最后,请注意,这是一个启发式:对于 $w \neq 1$ ,它认为 $\tilde{u}_{t}(x|y) \neq u_{t}^{\mathrm{target}}(x|y)$ ,即因此不是“真正的”引导向量场。
无分类器引导。虽然分类器引导原则上是可能的,但它会遇到困难:首先,我们需要在流/扩散模型旁边训练分类器 - 因此我们有 2 个网络而不是 1 个。此外,如果 $y$ 是高维的,例如一个文本prompt而不仅仅是一个类,那么 $p_t(y|x)$ 可能很难学习,并且梯度 $\nabla \log p_t(y|x)$ 很难获得。因此,引入了无分类器引导[18]。无分类器引导在理论上与分类器引导具有相同的效果,但无需训练单独的分类器。
为此,我们可以再次应用等式
$$ \nabla \log p _ {t} (x | y) = \nabla \log p _ {t} (x) + \nabla \log p _ {t} (y | x) $$
获得
$$ \begin{array}{l} \tilde {u} _ {t} (x | y) = u _ {t} ^ {\mathrm{target}} (x) + w a _ {t} \nabla \log p _ {t} (y | x) \\ = u _ {t} ^ {\mathrm{target}} (x) + w a _ {t} (\nabla \log p _ {t} (x | y) - \nabla \log p _ {t} (x)) \\ = u _ {t} ^ {\text { target }} (x) - \left(w b _ {t} x + w a _ {t} \nabla \log p _ {t} (x)\right) + \left(w b _ {t} x + w a _ {t} \nabla \log p _ {t} (x | y)\right) \\ = (1 - w) u _ {t} ^ {\text { target }} (x) + w u _ {t} ^ {\text { target }} (x | y). \\ \end{array} $$
因此,我们可以将缩放的引导矢量场 $\tilde{u}_t(x|y)$ 表示为非引导矢量场 $u_t^{\mathrm{target}}(x)$ 与引导矢量场 $u_t^{\mathrm{target}}(x|y)$ 的线性组合。然后,该想法可能会训练无引导的 $u_t^{\mathrm{target}}(x)$ (使用例如方程(26))以及引导的 $u_t^{\mathrm{target}}(x|y)$ (使用例如方程(58)),然后在推理时将它们组合以获得 $\tilde{u}_t(x|y)$ 。 “但是等等!”,您可能会问,“那么我们不需要训练两个模型吗!?”。事实证明,我们可以在一个模型中训练这两种模型:我们可以用一个新的、额外的 $\varnothing$ 标签来扩充我们的标签集,该标签表示没有条件调节。然后我们可以处理 $u_t^{\mathrm{target}}(x) = u_t^{\mathrm{target}}(x|\varnothing)$ 。这样,我们就不需要训练单独的模型来增强假设分类器的效果。这种将条件模型和无条件模型合二为一(并随后强化调节)的方法称为无分类器引导 (CFG) [18](参见图 12 中的说明)。
备注26(一般概率路径的推导)
注意施工
$$ \tilde {u} _ {t} (x | y) = (1 - w) u _ {t} ^ {\mathrm{target}} (x) + w u _ {t} ^ {\mathrm{target}} (x | y), $$
对于任何选择概率路径都同样有效,而不仅仅是高斯路径。当 w = 1 时,可以直接验证 $\tilde{u}_{t}(x|y) = u_{t}^{\mathrm{target}}(x|y)$ 。我们使用高斯路径的推导只是为了说明构造背后的直觉,特别是放大假设的“分类器”$\nabla \log p_{t}(y|x)$ 的贡献。
培训和无分类器引导。我们现在必须修改方程(58)中的引导条件流匹配目标,以考虑 $y = \varnothing$ 的可能性。挑战在于,当采样 $(z, y) \sim p_{\mathrm{data}}$ 时,我们永远不会获得 $y = \varnothing$ 。由此可见,我们必须人为地引入$y = \varnothing$的可能性。为此,我们将定义一些超参数 $\eta$ 作为我们丢弃原始标签 y 的概率,并将其替换为 $\varnothing$ 。因此,我们达到了 CFG 条件流匹配训练目标
$$ \mathcal {L} _ {\mathrm{CFM}} ^ {\mathrm{CFG}} (\theta) = \mathbb {E} _ {\square} \| u _ {t} ^ {\theta} (x | y) - u _ {t} ^ {\text {target}} (x | z) \| ^ {2} \tag {63} $$
$$ \Box = (z, y) \sim p _ {\text { data }} (z, y), t \sim \text { Unif } [ 0, 1 ], x \sim p _ {t} (\cdot | z), \text { replace } y = \varnothing \text { with prob. } \eta \tag {64} $$
算法5 高斯概率路径$p_t(x|z) = \mathcal{N}(x; \alpha_t z, \beta_t^2 I_d)$的无分类器引导训练
要求:配对数据集 $(z,y)\sim p_{\mathrm{data}}$ ,神经网络 $u_{t}^{\theta}$
1:对于每个小批量数据做
2:从数据集中采样数据示例 $(z,y)$。
3:采样随机时间 $t \sim \text{Unif}_{[0,1]}$ 。
4: 样本噪声 $\epsilon \sim \mathcal{N}(0, I_d)$ 5: 设置 $x = \alpha_t z + \beta_t \epsilon$ 6: 概率 p 丢弃标签:$y \leftarrow \varnothing$ 7: 计算损失
$$ \mathcal {L} (\theta) = \left\| u _ {t} ^ {\theta} (x | y) - \left(\dot {\alpha} _ {t} z + \dot {\beta} _ {t} \epsilon\right) \right\| ^ {2} $$
8:更新模型参数 $\theta$ 通过梯度下降 $\mathcal{L}(\theta)$ .
9:结束
我们将我们的发现总结如下。
摘要 27(流模型的无分类器指南)
给定无引导边缘向量场 $u_{t}^{\mathrm{target}}(x|\varnothing)$ 、引导边缘向量场 $u_{t}^{\mathrm{target}}(x|y)$ 和引导尺度 w > 1,我们将无分类器引导向量场 $\tilde{u}_{t}(x|y)$ 定义为
$$ \tilde {u} _ {t} (x | y) = (1 - w) u _ {t} ^ {\text { target }} (x | \varnothing) + w u _ {t} ^ {\text { target }} (x | y). \tag {65} $$
通过使用相同的神经网络近似 $u_{t}^{\mathrm{target}}(x|\varnothing)$ 和 $u_{t}^{\mathrm{target}}(x|y)$,我们可以利用以下内容



无分类器引导 CFM (CFG-CFM) 目标,由下式给出
$$ \mathcal {L} _ {\mathrm{CFM}} ^ {\mathrm{CFG}} (\theta) = \mathbb {E} _ {\square} \| u _ {t} ^ {\theta} (x | y) - u _ {t} ^ {\text { target }} (x | z) \| ^ {2} \tag {66} $$
$$ \Box = (z, y) \sim p _ {\text { data }} (z, y), t \sim \text { Unif } [ 0, 1 ], x \sim p _ {t} (\cdot | z), \text { replace } y = \varnothing \text { with prob. } \eta \tag {67} $$
用简单的英语来说,$L_{CFM}^{CFG}$ 可以近似为
$$ (z, y) \sim p _ {\mathrm{data}} (z, y) $$
$$ t \sim \operatorname{Unif} [ 0, 1) $$
$$ x \sim p _ {t} (x | z) $$
有问题。 η, y ← ∅
$$ \widehat {\mathcal {L} _ {\mathrm{CFM}} ^ {\mathrm{CFG}} (\theta)} = \| u _ {t} ^ {\theta} (x | y) - u _ {t} ^ {\mathrm{target}} (x | z) \| ^ {2} $$
▶ 从数据分布中采样$(z, y)$。
▶ 在 $[0,1)$ 上均匀采样 t。
▶ 从条件概率路径 $p_{t}(x|z)$ 中采样 x。
▶ 将 y 替换为 ∅,概率为 η。
▶ 针对条件向量场的回归模型。
在推理时,对于 y 的固定选择,我们可以通过以下方式进行采样
初始化:$X_{0} \sim p_{\mathrm{init}}(x)$
▶ 使用简单分布(例如高斯分布)进行初始化
模拟:$\mathrm{d}X_{t}=\tilde{u}_{t}^{\theta}(X_{t}|y)\mathrm{d}t$
▶ 模拟从 t = 0 到 t = 1 的 ODE。
示例:$X_{1}$
▶ $X_{1}$ 的目标是遵守引导变量 y。
请注意,如果我们使用权重 w > 1,$X_{1}$ 的分布不一定再与 $X_{1} \sim p_{\mathrm{data}}(\cdot|y)$ 一致。但是,根据经验,这显示出与条件的更好一致。因此,无分类器引导是一种启发式方法,其出色的实证结果主要证明其合理性。事实上,您看到的几乎所有由 AI 生成的图像或视频都严重依赖于无分类器的引导 $w \geq 4$ 。在图 11 中,我们展示了 128x128 ImageNet 上基于类的无分类器引导,如 [18] 中所示。同样,在图 13 中,我们可视化了在应用无分类器引导从 MNIST 手写数字数据集中采样时各种引导尺度 w 的影响。
备注 28(扩散模型指南)
将讨论从流动模型扩展到扩散模型是很简单的。只需将 $u_{t}^{\theta}(x|y)$ 替换为 $\tilde{u}_t^\theta (x|y)$ 并使用第 4 节中讨论的 SDE 示例即可。
6 构建大规模图像或视频生成器
在前面的部分中,我们学习了如何训练流匹配或扩散模型以从分布 $p_{\mathrm{data}}(x|y)$ 中进行采样。这个配方是通用的,可以应用于各种不同的数据类型和应用程序。在本节中,我们将深入研究大规模图像和视频生成的特殊情况,包括 FLUX 2.0、Stable Diffusion 3、Nano Banana 和 VEO-3 或 Meta Movie Gen Video 等著名模型。最后,我们将应用迄今为止在实验室中学到的知识从头开始构建我们自己的此类模型版本!本节大致安排如下:
- 神经网络架构:我们首先讨论原始条件输入(包括时间 t 和引导变量)如何 $y_{raw}$ (即离散类标签或原始文本)被转换或嵌入到模型可消化的向量值形式中 $u_{t}^{\theta}(x|y)$ 本身。然后我们讨论流行的架构选择 $u_{t}^{\theta}(x|y)$ ,包括U-Net和扩散变压器。
- latent 空间:我们讨论变分自编码器,它允许在较低维度的latent 空间中进行生成式建模,从而实现超高分辨率图像生成。
- 案例研究:最后,我们将深入研究上面提到的两种最先进的图像和视频模型 - Stable Diffusion 和 Meta MovieGen - 让您了解如何大规模完成工作。
6.1 神经网络架构
让我们首先将注意力转向针对类图像模式(例如图像和视频)的流和扩散模型的可扩展神经网络架构的设计。具体来说,我们将探讨(引导)向量场的任务如何 $u_t^\theta(x|y)$ 带参数 $\theta$ 并落实到实践中。请注意,神经网络必须有 3 个输入:一个向量 $x \in \mathbb{R}^d$ , 条件变量 $y \in \mathcal{Y}$ ,和时间值 $t \in [0,1]$ ,以及一个输出,一个向量 $u_t^\theta(x|y) \in \mathbb{R}^d$ 。对于低维分布(例如我们在前面几节中看到的玩具分布),参数化就足够了 $u_t^\theta(x|y)$ 作为多层感知器(MLP),也称为全连接神经网络。也就是说,在这个简单的设置中,前向传递 $u_t^\theta(x|y)$ 将涉及连接我们的输入 $x, y,$ 和 $t$ ,并将它们传递给 MLP。然而,对于复杂的高维分布,例如图像、视频和蛋白质上的分布,MLP 可能不够,并且通常使用特殊的、特定于应用程序的架构。对于本小节的其余部分,我们将考虑图像(以及扩展的视频)的情况。首先,我们将考虑原始调节信息 - 时间 $t$ 和条件变量 $y$ - 嵌入到实际模型可消化的向量值形式中。其次,我们将考虑此类模型的两种常见架构选择:U-Net [38, 17, 22, 11],以及扩散变压器 (DiT) [12, 30, 28].
6.1.1 嵌入条件变量
嵌入时间。对于简单的玩具模型,将 t 的原始值连接到输入足以训练一个性能相当好的网络。在实践中,标量时间通常使用傅里叶特征嵌入到更高维空间中,使模型能够更忠实地捕获高频时间依赖性 $[46]$ 。明确地说,
特征化由下式给出
$$ \operatorname{TimeEmb} (t) = \sqrt {\frac {2}{d}} \left[ \cos (2 \pi w _ {1} t) \quad \dots \quad \cos (2 \pi w _ {d / 2} t) \quad \sin (2 \pi w _ {1} t) \quad \dots \quad \sin (2 \pi w _ {d / 2} t) \right] ^ {T}, \tag {68} $$
其中频率 $w_{i}$ 按以下方式设置
$$ w _ {i} = w _ {\min} \left(\frac {w _ {\max}}{w _ {\min}}\right) ^ {\frac {i - 1}{d / 2 - 1}}, \quad i = 1, \dots , d / 2. \tag {69} $$
TimeEmb 的这种选择是标准选择,但这种精确形式并不是绝对必要的。相反,上面只是获得维度 d 的规范嵌入的便捷方法,即 $\|\text{TimeEmb}(t)\|=1$ (因为 $\sin^{2}+\cos^{2}=1$ )。
嵌入类标签。什么时候 $y_{raw} \in Y \triangleq \{0, \ldots, N\}$ 只是一个类标签,那么通常最简单的是为每个类别学习一个单独的嵌入向量 $N + 1$ 的可能值 $y_{raw}$ ,并将 y 设置为该嵌入向量。人们会认为这些嵌入的参数包含在 $u_{t}^{\theta}(x|y)$ ,因此会在训练期间学习这些。
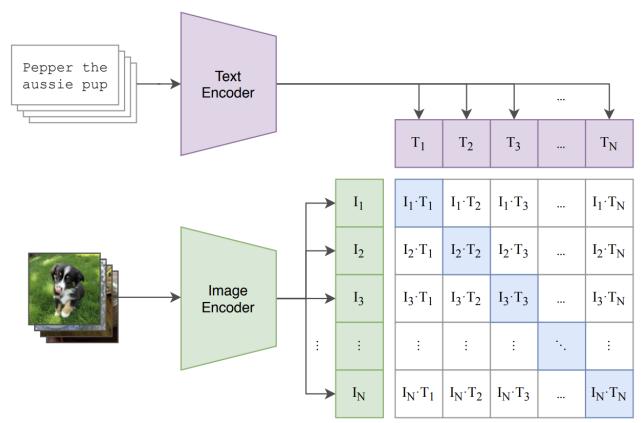
嵌入文本输入当 $y_{raw}$ 是文本prompt时,情况更加复杂,并且方法很大程度上依赖于冻结的预训练模型。此类模型经过训练,可将离散文本输入嵌入到捕获相关信息的连续向量中。其中一种模型称为 CLIP(对比语言图像预训练)。 CLIP 经过训练,学习图像和文本prompt的共享嵌入空间,使用旨在鼓励图像嵌入接近其相应prompt的训练损失,同时远离其他图像和prompt的嵌入 [34]。因此,我们可以将 $y = \text{CLIP}(y_{\text{raw}}) \in \mathbb{R}^{d_{\text{CLIP}}}$ 视为由冻结的、预先训练的 CLIP 模型生成的嵌入。在某些情况下,可能不希望将整个序列压缩为单个表示。在这种情况下,人们还可以考虑使用预先训练的变压器来嵌入prompt,以获得一系列嵌入。在调节时组合多个此类预训练嵌入也很常见,以便同时获得每个模型 [14, 33] 的好处。出于我们的目的,我们可以简单地假设应用这样的模型后,prompt嵌入具有形状
$$ \operatorname{PromptEmbed} \left(y _ {\text { raw }}\right) \in \mathbb {R} ^ {S \times k} $$
6.1.2 扩散变压器
在我们深入研究这些架构的细节之前,让我们回想一下前面的介绍,图像只是一个向量 $x \in R^{C_{image} \times H \times W}$ 。这里 $C_{image}$ 表示通道数(RGB 图像通常有 $C_{input} = 3$ 颜色通道),H 和 W 分别表示图像的高度和宽度(以像素为单位)。一个特别突出的架构类别是所谓的扩散变压器(DiT)及其变体,它们使用注意力机制来构建网络 [49, 30, 28]。扩散变压器有不同的风格。我们在此解释通用设计,并注意 DiT 的具体实例可能会因模型和应用程序的不同而有所不同。在本节的其余部分中,我们将使用 d 表示隐藏维度,L 表示转换器层数,h 表示每层的头数。扩散变压器基于视觉变压器(ViT),其主要思想本质上是将图像划分为补丁,嵌入补丁以获得令牌序列,并通过标准注意力[13]处理生成的令牌。最后应用最终的分片操作以恢复正确形状的图像。初始修补操作只是图像张量 $x \in \mathbb{R}^{C \times H \times W}$ 的重构:
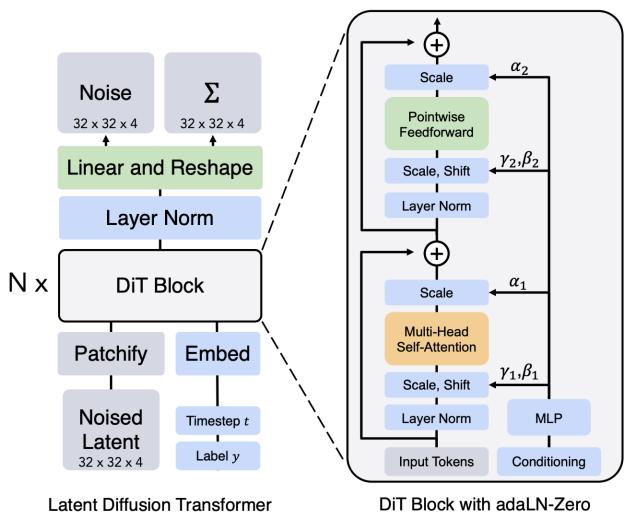
$$ \operatorname{Patchify} (x) \in \mathbb {R} ^ {N \times C ^ {\prime}} $$
其中 $C' = CP^{2}$ 、 $N = (H/P) \cdot (W/P)$ 表示 P 补丁大小。接下来,我们对输出应用线性变换,得到最终的补丁嵌入
$$ \operatorname{PatchEmb} (x) = \operatorname{Patchify} (x) W \in \mathbb {R} ^ {N \times d} $$
其中 $W \in R^{C' \times d}$ 是可学习的权重矩阵。扩散变换器的输入是时间嵌入、prompt嵌入和修补图像张量,由下式给出(参见第 6.1.1 节):
$$ \begin{array}{l} \tilde {t} = \mathrm{TimeEmb} (t) \in \mathbb {R} ^ {d} \\ \tilde {y} = \operatorname{PromptEmb} (y) \in \mathbb {R} ^ {S \times d} \\ \tilde {x} _ {0} = \operatorname{PatchEmb} (x) \in \mathbb {R} ^ {N \times d} \\ \end{array} $$
请注意,所有元素现在都具有所需的变压器隐藏尺寸。然后,扩散变压器通过 DitBlock 中的变压器层迭代更新 $\tilde{z}_{i}$ 为 $i = 0, \cdots, L - 1$ (详细信息请参阅备注 29):
$$ \tilde {x} _ {i + 1} = \operatorname{DiTBlock} \left(\tilde {x} _ {i}, \tilde {t}, \tilde {y}\right) \in \mathbb {R} ^ {N \times d} (i = 0, \dots , L - 1). \tag {70} $$
其中 N 是层数。最后,最后一个操作应用分批操作,将 DiT 输出映射回所需的输出形状:
$$ u = \mathrm{Depatchify} (\tilde {x} _ {N} \tilde {W}) \in \mathbb {R} ^ {C \times H \times W}, $$
其中 $\tilde{W} \in R^{d \times C'}$ 。最终张量 u 作为模型的输出和预测速度 $u_{t}^{\theta}(x|y)$ 。
备注 29(DiT 块)
为了完整起见,我们对单个 DiT 层进行了简短的数学描述。虽然我们试图包含足够的细节以便对 DiT 模型系列有一个总体的了解,但我们提醒读者,这些模型选择强调关键算法选择而不是架构细节。现在,让 $x \in R^{N \times d}$ 表示补丁标记的当前序列(此处为 $x = \tilde{x}_{i}$ ),并让 $y \in R^{S \times d}$ 表示嵌入的引导变量(此处为 $y = \tilde{y}$ )。然后,典型的 DiT 块使用(i)补丁上的自注意力,(ii)对prompt的交叉注意力,以及(iii)通过自适应标准化(AdaLN)进行时间调节来更新 x。
缩放点积注意力。给定查询 $Q \in R^{N \times d_{h}}$ 、键 $K \in R^{M \times d_{h}}$ 和值 $V \in R^{M \times d_{h}}$ ,
$$ \operatorname{Attn} (Q, K, V) = \operatorname{softmax} \left(\frac {Q K ^ {\top}}{\sqrt {d _ {h}}}\right) V \in \mathbb {R} ^ {N \times d _ {h}}, $$
其中 softmax 是按行应用的。
多头注意力。让 $h$ 表示磁头数量,$d_h = \frac{d}{h}$ 表示每个磁头的尺寸。对于每个头 $h \in \{1, \ldots, n_{\mathrm{heads}}\}$ ,学习投影矩阵 $W_Q^{(h)}, W_K^{(h)}, W_V^{(h)} \in \mathbb{R}^{k \times d_h}$ 。定义
$$ \mathrm{head} _ {h} (x, z) = \mathrm{Attn} \bigl (x W _ {Q} ^ {(h)}, z W _ {K} ^ {(h)}, z W _ {V} ^ {(h)} \bigr), $$
其中源序列 $z$ 是
$$ z = x \quad (\text { self - attention on patches }), \qquad z = y \quad (\text { cross - attention to the prompt }). $$
连接头并应用输出投影 $W_{O} \in R^{d \times d}$ :
$$ \text { MultiHeadattention } (x, z) = \text { Concat } \bigl (\text { head } _ {1} (x, z), \ldots , \text { head } _ {h} (x, z) \bigr) W _ {O} \in \mathbb {R} ^ {N \times d}. $$
通过自适应标准化进行时间调节。令 $\tilde{t} \in R^{d}$ 为时间步嵌入。 DiT 中的标准选择是使用 $\tilde{t}$ 生成调节归一化激活 [31] 的每通道缩放/移位参数。具体来说,令 $g : R^{d} \to R^{2d}$ 为 MLP 并设置
$$ (\gamma , \beta) = g (\tilde {t}), $$
其中 $\gamma,\beta\in R^{d}$ (或者,根据实现,为不同的子层(例如注意力和 MLP)单独的 $(\gamma,\beta)$ 对)。给定一个标记矩阵 $x\in R^{N\times d}$ 和一个标准化运算符 $\operatorname{Norm}(\cdot)$ (例如 LayerNorm),
定义调制归一化
$$ \mathrm{AdaNorm} _ {\tilde {t}} (x) = \left(1 + \gamma\right) \odot \mathrm{Norm} (H) + \beta , $$
其中 $\odot$ 表示在令牌维度上广播的元素乘法。
把它放在一起。组合操作以及 DitBlock 由下式给出。
$$ x \leftarrow x + g _ {\text { self }} (\tilde {t}) \odot \text { MultiHeadattention } \bigl (\text { AdaNorm } _ {\tilde {t}} (x), \text { AdaNorm } _ {\tilde {t}} (x) \bigr) $$
$$ x \leftarrow x + g _ {\text { cross }} (\tilde {t}) \text { MultiHeadattention } \bigl (\text { AdaNorm } _ {\tilde {t}} (x), y \bigr) $$
$$ x \leftarrow x + g _ {\mathrm{MLP}} (\tilde {t}) \mathrm{MLP} \bigl (\mathrm{AdaNorm} _ {\tilde {t}} (x) \bigr), $$
其中 MLP 是位置前馈网络,$g\ldots$ 是可学习的门控参数。输出 $x \in R^{N \times d}$ 成为下一层补丁令牌序列(在我们的符号中为 $\tilde{x}_{i+1}$ )。最后,我们注意到类条件 DiT(例如在实验室中实现的 DiT)通常更简单,并且避开交叉注意层,而有利于基于时间和类的 AdaNorm 条件。
6.1.3 优网
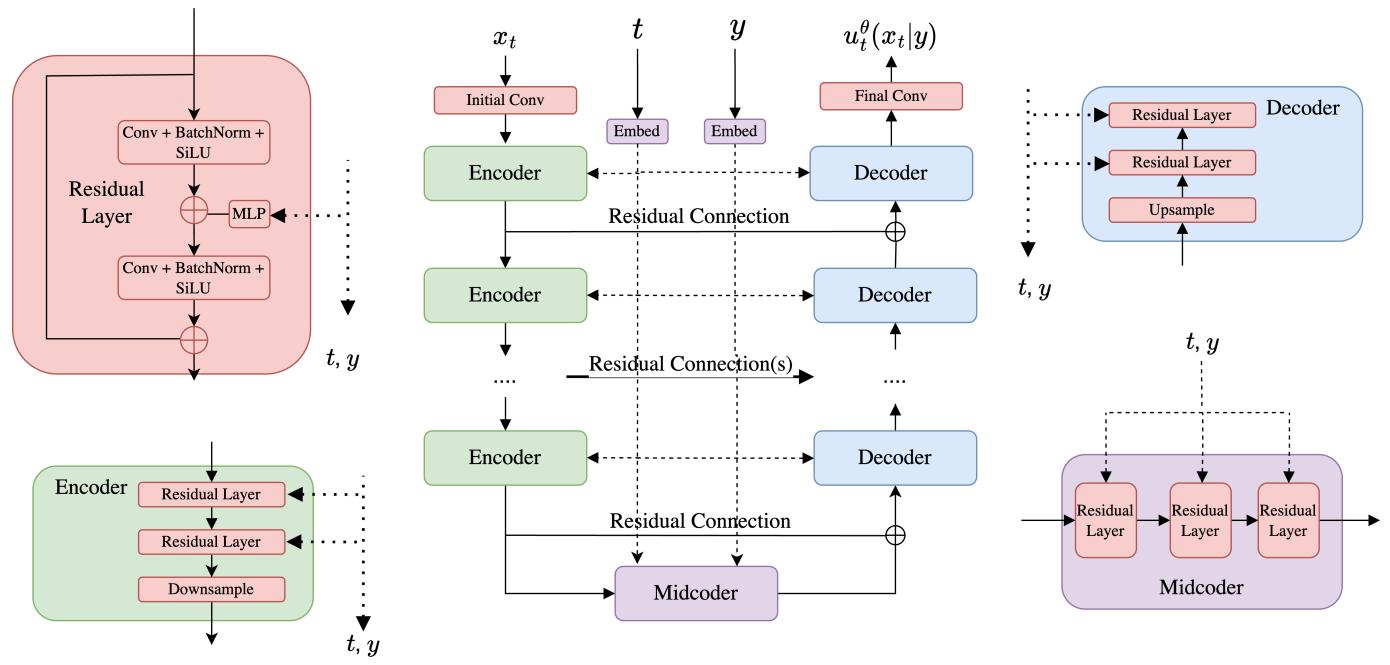
U-Net 架构 [38] 是 DiT 架构的替代架构,是一种特定类型的卷积神经网络。最初是为图像分割而设计的,其关键特征是其输入和输出都具有图像的形状(可能具有不同数量的通道)。这使得它非常适合参数化向量场 $x \mapsto u_{t}^{\theta}(x|y)$ ,对于固定 y, t ,其输入具有图像的形状,其输出也具有图像的形状。因此,U-Net 在许多关于扩散模型的早期文献中得到了广泛的应用[17, 22, 11]。 U-Net 由一系列编码器 $E_{i}$ 和相应的解码器序列 $D_{i}$ 以及中间的潜在处理块组成,我们将其称为中间编码器。 $^{3}$ 举例来说,让我们浏览一下图像 $x_{t} \in R^{3 \times 256 \times 256}$ (我们已经采用了 $(C_{\mathrm{input}}, H, W) = (3, 256, 256)$ )在 U-Net 处理时所采取的路径:
$$ x _ {t} ^ {\mathrm{input}} \in \mathbb {R} ^ {3 \times 2 5 6 \times 2 5 6} \quad \blacktriangleright \text { Input to the U - Net. } $$
$$ x _ {t} ^ {\text { latent }} = \mathcal {E} (x _ {t} ^ {\text { input }}) \in \mathbb {R} ^ {5 1 2 \times 3 2 \times 3 2} \quad \blacktriangleright \text { Pass through encoders to obtain latent. } $$
$$ x _ {t} ^ {\text { latent }} = \mathcal {M} (x _ {t} ^ {\text { latent }}) \in \mathbb {R} ^ {5 1 2 \times 3 2 \times 3 2} \quad \blacktriangleright \text { Pass latent through midcoder. } $$
$$ x _ {t} ^ {\text { output }} = \mathcal {D} (x _ {t} ^ {\text { latent }}) \in \mathbb {R} ^ {3 \times 2 5 6 \times 2 5 6} \quad \blacktriangleright \text { Pass through decoders to obtain output. } $$
请注意,当输入通过编码器时,其表示形式中的通道数量会增加,而图像的高度和宽度会减少。编码器和解码器通常都由一系列卷积层组成(中间有激活函数、池化操作等)。上面未显示的是两点:首先,输入 $x_{t}^{input} \in R^{3 \times 256 \times 256}$ 通常会被馈送到初始预编码块中,以在被馈送到第一个编码器块之前增加通道数量。其次,编码器和解码器通常通过残差连接连接。完整的图片如图 15 所示。在较高层次上,大多数 U-Net 都涉及上述内容的某些变体。然而,上面描述的某些设计选择可能与实践中的各种实现完全不同。特别是,我们在上面选择了纯卷积架构,而在编码器和解码器中通常也包含注意力层。 U-Net 因其编码器和解码器形成的“U”形而得名(见图 15)。
6.2 在latent 空间中工作:(变分)自编码器
到目前为止,我们已经在数据空间 $R^{d}$ 中进行了操作。然而,随着图像分辨率越来越高,在这样的空间内直接建模的成本很快就会变得异常昂贵。例如,具有三个 RGB 颜色通道的 $1024 \times 1024$ 图像对应于 $d = H \cdot W \cdot 3 \approx 3 \times 10^{6}!$ 的总尺寸。请注意,视频的维度进一步增加,因为所有内容都随着帧数 T 的缩放而增加。正如您可以想象的那样,在这样的空间上进行训练很快就会变得不可行。与图像分类的低维输出允许缩小卷积堆栈不同,我们基于流的建模方法要求我们的输出 $u_{t}^{\theta}(x) \in \mathbb{R}^{d}$ 与我们的输入一样大。因此,重要的问题变成:我们如何在合理的内存和计算预算内对高维图像进行建模?
6.2.1 标准自编码器
这个问题的一个自然答案在于压缩:例如,图像的实际空间可能位于高维图像空间的低维流形附近。更具体地说,我们可以考虑一个编码器 $\mu_{\phi}:R^{d}\to R^{k}$ ,连同一些解码器 $\mu_{\theta}:R^{k}\to R^{d}$ ,它们一起映射原始图像 $x\in R^{d}$ 往返于潜伏者 $z\in R^{k}$ , 分别。通常选择尺寸 k 远小于 d。对于图像,例如, $d = 3 \times 1024 \times 1024$ ,下采样以获得例如,并不罕见 $k = 3 \times \frac{1024}{16} \times \frac{1024}{16}$ 。一起, $\mu_{\phi}$ 和 $\mu_{\theta}$ 被称为自编码器。理想情况下, $\mu_{\phi}$ 和 $\mu_{\theta}$ 选择以获得高重建质量,或者换句话说,以便 $\mu_{\theta}(\mu_{\phi}(x))$ 平均值类似于 x。因此,自编码器通常使用重建损失进行训练
$$ \mathcal {L} _ {\mathrm{Recon}} (\phi , \theta) = \mathbb {E} _ {x \sim p _ {\mathrm{data}}} \left[ \left\| \mu_ {\theta} (\mu_ {\phi} (x)) - x \right\| ^ {2} \right]. $$
它测量原始数据点 x 和重建数据点 $\mu_{\theta}(\mu_{\phi}(x))$ 之间的平方误差。
适合生成式建模。不幸的是,上面的重建损失不足以训练一个“好的”自编码器。回想一下,我们的最终目标是在latent 空间中训练生成式模型,并针对潜在分布 $p_{\mathrm{latent}}(z)$ 给出的 $z = \mu_{\phi}(x), x \sim p_{\mathrm{data}}$ 。生成式模型 $p_{\mathrm{data}}(x)$ 然后通过将潜在生成式模型的输出传递给解码器来实现 $\mu_{\theta}$ 。自编码器出现了一个微妙的问题,因为我们目前已经制定了它们,因为我们几乎无法控制 $p_{\mathrm{latent}}(z)$ ,因此基本上不能保证 $p_{\mathrm{latent}}(z)$ 甚至表现得足够好,能够训练这样的生成式模型(即,漂亮、简单、类似高斯)。虽然在latent 空间中转换我们的数据可能会压缩它,但我们可能会改变数据分布 $p_{data}$ 进入一个非常难学的分布 $p_{latent}$ 。因此,问题是:我们如何确保潜在分布 $p_{latent}$ 还乖巧好学吗?为了允许对潜在分布进行更明确的正则化,我们现在将在更通用的概率框架中重新定义自编码器的概念,从而产生变分自编码器的概念。
6.2.2 变分自编码器
通过放宽编码器和解码器是确定性函数的约束,从我们的(确定性)标准自编码器公式中获得变分自编码器(VAE)。特别地,让我们考虑一个编码器 $q_{\phi}(z|x)$ 带参数 $\phi$ ,和一个解码器 $p_{\theta}(x|z)$ 带参数 $\theta$ 。最常见的选择是采取
$$ q _ {\phi} (z | x) = \mathcal {N} (z; \mu_ {\phi} (x), \mathrm{diag} (\sigma_ {\phi} ^ {2} (x))), \quad p _ {\theta} (x | z) = \mathcal {N} (x; \mu_ {\theta} (z), \sigma_ {\theta} ^ {2} (z) I _ {d}) \tag {71} $$
其中 $\mu_{\phi}(x) \in \mathbb{R}^k$ 、 $\sigma_{\phi}^{2}(x) \in \mathbb{R}_{\geq 0}^{k}$ 、 $\mu_{\theta}(z) \in \mathbb{R}^d$ 和 $\sigma_{\theta}^{2}(z) \in \mathbb{R}_{\geq 0}$ 被参数化为神经网络,diag 表示对角矩阵。为了对变量进行编码或解码,我们采样
$$ \begin{array}{l} z \sim q _ {\phi} (\cdot | x) \quad (\text { encode }) \\ x \sim p _ {\theta} (\cdot | z) \quad (\text { decode }) \\ \end{array} $$
最后,我们注意到当 $\sigma_{\phi}(x) = 0$ 和 $\sigma_{\theta}(x) = 0$ 总是时,我们恢复标准自编码器。让我们看看重建损失是什么样子的。一个自然的目标如下:
$$ \mathcal {L} _ {\mathrm{VAE-Recon}} (\phi , \theta) = - \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x), z \sim q _ {\phi} (\cdot | x)} [ \log p _ {\theta} (x | z) ] \tag {72} $$
请注意两个变化:我们现在采样 $z \sim q_{\phi}(z|x)$ ,而不是确定性编码。此外,我们现在在解码时采用 x 的负对数似然,即损失有效地询问:如果我们对其进行编码和解码,我们的原始数据点 x 的可能性有多大 - 并且我们考虑所有可能的解码/编码,因为现在事情已经变得随机。对于高斯情况,该重建损失变为:
$$ \mathcal {L} _ {\mathrm{VAE-Recon}} (\phi , \theta) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x), z \sim q _ {\phi} (z | x)} \left[ \frac {1}{2 \sigma_ {\theta} ^ {2} (z)} \| x - \mu_ {\theta} (z) \| ^ {2} + \frac {d}{2} \log \sigma_ {\theta} ^ {2} (z) \right] + \text { const } \tag {73} $$
其中我们使用正态分布的密度(参见方程(97))因此,VAE 重建损失与标准 AE 重建损失没有太大不同,我们只需考虑所有可能的编码 $z \sim q_{\phi}(\cdot|x)$ 。取决于解码器方差的第二项控制重建精度和预测不确定性之间的权衡。许多实现(包括实验室中的实现)将 $\sigma_{\phi}(x)$ 和 $\sigma_{\theta}(z)$ 修复为学习的标量常数(即,分别独立于 x 和 z),从而避免学习方差时的病态行为和数值稳定性。因此,这种情况下的 VAE 重建损失基本上变成了标准自编码器重建损失,直至编码和常数的随机性:
$$ \mathcal {L} _ {\mathrm{VAE-Recon}} (\phi , \theta) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x), z \sim q _ {\phi} (z | x)} \left[ \frac {1}{2 \sigma_ {\theta} ^ {2}} \| x - \mu_ {\theta} (z) \| ^ {2} \right] + \text { const } \tag {74} $$
现在让我们重新审视我们的目标:我们想要创建数据分布 $p_{\mathrm{data}}(x)$ 的编码,以便在将其映射到latent 空间后,分布变得“好”或易于学习。为此,现在让我们介绍一个关于潜在 z 的先验分布 $p_{\mathrm{prior}}(z)$ 。出于我们的目的,我们将 $p_{\mathrm{prior}} = \mathcal{N}(0, I_k)$ 视为各向同性高斯。这种先验分布 $p_{prior}$ 的选择有效地代表了潜在分布应该是什么样子的“理想”情况。正态分布非常容易学习,因此可以满足我们获得“可训练”潜在分布的目标。因此,重要的想法是规范我们的编码器,以确保编码数据分布尽可能接近 $p_{prior}$ ,这是我们通过辅助损失来实现的
$$ \mathcal {L} _ {\mathrm{VAE-Prior}} (\phi) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x)} \left[ D _ {\mathrm{KL}} (q _ {\phi} (\cdot | x) \parallel p _ {\mathrm{prior}}) \right], \tag {75} $$
其中 $D_{KL}$ 是 Kullback-Leibler (KL) 散度。 KL 散度是衡量两个概率分布差异程度的基本方法。详细解释它超出了本文的范围,但我们在备注 30 中给出了简要背景,以提醒读者。现在这里定义的损失 $L_{VAE-Prior}$ 非常直观:我们希望任何数据点 x 的编码分布看起来都像高斯分布。如果我们对所有 x 都这样做,那么很自然地预期我们的潜在分布也将呈现高斯分布。
备注30(KL散度的背景)
对于两个概率密度 q、p,Kullback-Leibler 散度(KL 散度)定义为
$$ D _ {\mathrm{KL}} (q (x) \parallel p (x)) = \int q (x) \log \frac {q (x)}{p (x)} = \mathbb {E} _ {X \sim q} \left[ \log \frac {q (X)}{p (X)} \right]. $$
KL 散度是分布之间差异的标准度量。特别是,KL 散度满足以下有用的属性:
$$ D _ {\mathrm{KL}} (q (x) \parallel p (x)) \geq 0, \tag {76} $$
$$ D _ {\mathrm{KL}} (q (x) \parallel p (x)) = 0 \quad \Leftrightarrow \quad q = p. \tag {77} $$
即,当且仅当两个概率分布一致时,它总是非负的并且为零。
为了定义变分自编码器的损失函数,我们现在可以将重建和先验损失与参数权重 $\beta \geq 0$ 结合起来,以达到 VAE 训练目标:
$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = \mathcal {L} _ {\mathrm{VAE-Recon}} (\phi , \theta) + \beta \mathcal {L} _ {\mathrm{VAE-Prior}} (\phi) \tag {78} $$
$$ = - \mathbb {E} _ {x \sim p _ {\text { data }} (x), z \sim q _ {\phi} (z | x)} [ \log p _ {\theta} (x \mid z) ] + \beta \mathbb {E} _ {x \sim p _ {\text { data }} (x)} [ D _ {K L} (q _ {\phi} (\cdot | x) | | p _ {\text { prior }}) ] \tag {79} $$
其中第一个被加数强制潜在变量可以有效地解码回数据,第二个被加数强制我们的潜在分布接近高斯分布。参数 $\beta$ 控制每个的强度。为了使这个损失更加具体,让我们推导高斯情况下的 KL 散度:
示例 31(各向同性高斯之间的 KL 散度)
令 $q(x) = \mathcal{N}(x; \mu_q, \mathrm{diag}(\sigma_q^2))$ 和 $p(x) = \mathcal{N}(x; \mu_p, \mathrm{diag}(\sigma_p^2))$ 为具有对角协方差矩阵的高斯函数,其中 $\sigma_q, \sigma_p \in \mathbb{R}_{\geq 0}^d$ ,其中 $x \in \mathbb{R}^d$ 。然后
$$ D _ {\mathrm{KL}} (q \parallel p) = \frac {1}{2} \left(\mathcal {K} \left(\frac {\sigma_ {q} ^ {2}}{\sigma_ {p} ^ {2}}\right) + \frac {\| \mu_ {q} - \mu_ {p} \| ^ {2}}{\sigma_ {p} ^ {2}}\right), \quad \text { where } \mathcal {K} (\alpha) = \sum_ {i = 1} ^ {d} \alpha_ {i} - \log \alpha_ {i} - 1. \tag {80} $$
上面的表达式很直观:如果均值和方差一致,那么 $D_{\mathrm{KL}}(q \parallel p) = 0$ 。此外,它随着平方误差的增加而增加 $\|\mu_{q} - \mu_{p}\|^{2}$ 平均向量之间。最后,函数 $\mathcal{K}(\alpha)$ 有一个唯一的最小值 $\alpha = 1$ 以便 $D_{\mathrm{KL}}(q \parallel p)$ 最小化时 $\sigma_{q} = \sigma_{p}$ .
证明。我们对 d = 1 进行证明(通过对每个维度求和来证明 d > 1 的情况类似)。给定正态分布的密度,我们知道(参见方程(97)):
$$ \log q (x) = - \frac {1}{2} \log (2 \pi \sigma_ {q} ^ {2}) - \frac {1}{2 \sigma_ {q} ^ {2}} \| x - \mu_ {q} \| ^ {2}, \quad \log p (x) = - \frac {1}{2} \log (2 \pi \sigma_ {p} ^ {2}) - \frac {1}{2 \sigma_ {p} ^ {2}} \| x - \mu_ {p} \| ^ {2} $$
然后
$$ D _ {\mathrm{KL}} (q \| p) = \mathbb {E} _ {x \sim q} \big [ \log q (x) - \log p (x) \big ] = \frac {1}{2} \log \frac {\sigma_ {p} ^ {2}}{\sigma_ {q} ^ {2}} + \frac {1}{2 \sigma_ {p} ^ {2}} \mathbb {E} _ {q} \big [ \| x - \mu_ {p} \| ^ {2} \big ] - \frac {1}{2 \sigma_ {q} ^ {2}} \mathbb {E} _ {q} \big [ \| x - \mu_ {q} \| ^ {2} \big ]. \tag {81} $$
对于 $x\sim \mathcal{N}(\mu_q,\sigma_q^2 I)$ 我们有
$$ \mathbb {E} _ {q} \big [ \| x - \mu_ {q} \| ^ {2} \big ] = \mathrm{tr} (\sigma_ {q} ^ {2} I) = \sigma_ {q} ^ {2}. $$
将此与 $x - \mu_{p} = (x - \mu_{q}) + (\mu_{q} - \mu_{p})$ 和 $E_{q}[x - \mu_{q}] = 0$ 的事实相结合,我们得到
$$ \mathbb {E} _ {q} \big [ \| x - \mu_ {p} \| ^ {2} \big ] = \mathbb {E} _ {q} \big [ \| x - \mu_ {q} \| ^ {2} \big ] + \| \mu_ {q} - \mu_ {p} \| ^ {2} = \sigma_ {q} ^ {2} + \| \mu_ {q} - \mu_ {p} \| ^ {2}. $$
将这些代入方程 (81) 得到 (80)。

$$ \mathcal {L} _ {\mathrm{VAE-Prior}} (\phi) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x)} \left[ D _ {\mathrm{KL}} \left(q _ {\phi} (\cdot | x) \| \mathcal {N} \left(0, I _ {k}\right)\right) \right] = \mathbb {E} \left[ \frac {1}{2} \mathcal {K} \left(\sigma_ {\phi} ^ {2} (x)\right) + \frac {1}{2} \| \mu_ {\phi} (x) \| ^ {2} \right] \tag {82} $$
这种损失很直观:均值 $\mu_{\phi}(x)$ 因不为零而受到惩罚,方差因不为零而受到惩罚
与 1 不同。作为 VAE 的总损失,我们得到
$$ \begin{array}{l} \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) \\ = \mathcal {L} _ {\text { VAE - Recon }} (\phi , \theta) + \beta \mathcal {L} _ {\text { VAE - Prior }} (\phi) \\ = \mathbb {E} _ {x \sim p _ {\text {data}} (x), z \sim q _ {\phi} (z | x)} \left[ \underbrace {\frac {1}{2 \sigma_ {\theta} ^ {2} (z)} \| x - \mu_ {\theta} (z) \| ^ {2}} _ {\text {recon. error}} + \underbrace {\frac {d}{2} \log \sigma_ {\theta} ^ {2} (z)} _ {\text {decoder confidence}} + \underbrace {\frac {\beta}{2} \mathcal {K} (\sigma_ {\phi} ^ {2} (x))} _ {\text {make latent variance = 1}} + \underbrace {\frac {\beta}{2} \| \mu_ {\phi} (x) \| ^ {2}} _ {\text {make latent mean = 0}} \right] \tag {83} \\ \end{array} $$
上述损失函数的四项非常直观:第一项只是重建误差。第二个错误描述了解码器的不确定性:较小的方差使解码器更加“自信”,但也会更强烈地惩罚重建错误。此外,我们希望使潜在方差为 1,均值为 0 - 以强制潜在分布接近高斯分布。
训练 VAE。仍有待讨论如何最小化 VAE 损失 $\mathcal{L}_{\mathrm{VAE}}(\phi,\theta)$ 。损失的问题在于,到目前为止,我们对 $(q_{\phi}(z|x))$ 的期望值的分布仍然取决于参数 $\phi$ 。但是,我们可以应用所谓的重新参数化技巧来重写它。具体来说,对于
$$ q _ {\phi} (z | x) = \mathcal {N} (z; \mu_ {\phi} (x), \sigma_ {\phi} ^ {2} (x) I _ {k}) $$
我们可以通过以下方式获取样品
$$ \epsilon \sim \mathcal {N} (0, I _ {k}), \quad z = \mu_ {\phi} (x) + \sigma_ {\phi} (x) \epsilon \Rightarrow z \sim q _ {\phi} (\cdot | x) $$
请注意,在此等式中,噪声/随机性的唯一来源来自 $\epsilon$ ,其分布独立于 $\phi$ 。因此,我们可以将损失重写为:
$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x), \epsilon \sim \mathcal {N} (0, I _ {k})} \left[ \frac {1}{2 \sigma_ {\theta} ^ {2} (z)} \| x - \mu_ {\theta} (\mu_ {\phi} (x) + \sigma_ {\phi} (x) \epsilon) \| ^ {2} + \frac {d}{2} \log \sigma_ {\theta} ^ {2} (z) + \frac {\beta}{2} \mathcal {K} \left(\sigma_ {\phi} ^ {2} (x)\right) + \frac {\beta}{2} \| \mu_ {\phi} (x) \| ^ {2} \right] $$
重新参数化后,随机性仅来自 $\epsilon \sim \mathcal{N}(0, I_k)$ ,其分布不依赖于 $\phi$ 。因此,我们可以使用深度学习的标准工具来最小化这种损失。为了进一步简化事情,我们可以再次在各处设置 $\sigma_{\theta}^{2}(z) = \sigma^{2}$ 常量并获得:
$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = \mathbb {E} _ {x \sim p _ {\mathrm{data}} (x), \epsilon \sim \mathcal {N} (0, I _ {k})} \left[ \frac {1}{2 \sigma^ {2}} \| x - \mu_ {\theta} (\mu_ {\phi} (x) + \sigma_ {\phi} (x) \epsilon) \| ^ {2} + \frac {\beta}{2} \mathcal {K} \left(\sigma_ {\phi} ^ {2} (x)\right) + \frac {\beta}{2} \| \mu_ {\phi} (x) \| ^ {2} \right] $$
在算法6中,我们总结了VAE的训练过程。
实用的评论。我们在这里开发的结构展示了自编码器设计的原理。当然,在实践中,人们可能会添加更多的损失项或其他约束。因此,我们最后添加有关自编码器的实用注释:
- 选择$\beta$(和 KL 热身)。大 $\beta$ 强制潜伏更接近先前,但可能会损害重建并可能触发后验崩溃(编码器忽略 x 并输出 $q_{\phi}(z|x) \approx \mathcal{N}(0, I_k)$ )。常见的稳定是 KL 预热:从 $\beta = 0$ 开始,并在第一个时期内逐渐将其增加到目标值。然而,在所有现代自编码器中, $\beta$ 值非常小,即 $\beta << 1$ 。
算法 6 $\beta$ -VAE 训练过程(具有固定方差的高斯解码器 $p_{\theta}(x|z) = \mathcal{N}(x; \mu_{\theta}(z), \tilde{\sigma}^{2}I_{d})$ )
要求:样本数据集 $x \sim p_{data}$ 、编码器网络 $(\mu_{\phi}(x), \log \sigma_{\phi}^{2}(x))$ 、解码器网络 $\mu_{\theta}(z)$ 、潜在暗淡 k、常量 $\beta \geq 0$ 、 $\sigma^{2} > 0$ 1:对于每个小批量 $\{x_{i}\}_{i=1}^{B}$ 执行
2:对每个 $x_{i}$ 进行编码:$\mu_{i} \leftarrow \mu_{\phi}(x_{i})$ 、 $\log \sigma_{i}^{2} \leftarrow \log \sigma_{\phi}^{2}(x_{i})$ 3:采样噪声 $\epsilon_{i} \sim \mathcal{N}(0, I_{k})$ 4:重新参数化:$z_{i} \leftarrow \mu_{i} + \sigma_{i} \odot \epsilon_{i}$ (其中 $\sigma_{i} = \exp(\frac{1}{2} \log \sigma_{i}^{2})$ )
5:解码平均值:$\hat{x}_{i} \leftarrow \mu_{\theta}(z_{i})$ 6:重建损失:
$$ \mathcal {L} _ {\mathrm{recon}} \leftarrow \frac {1}{B} \sum_ {i = 1} ^ {B} \frac {1}{2 \tilde {\sigma} ^ {2}} \left\| x _ {i} - \hat {x} _ {i} \right\| ^ {2} $$
7:KL 损失到之前的 $p_{\mathrm{prior}}(z)=\mathcal{N}(0,I_{k})$ :
$$ \mathcal {L} _ {\mathrm{KL}} \leftarrow \frac {1}{B} \sum_ {i = 1} ^ {B} \frac {1}{2} \sum_ {j = 1} ^ {k} \left(\mu_ {i, j} ^ {2} + \sigma_ {i, j} ^ {2} - \log \sigma_ {i, j} ^ {2} - 1\right) $$
8:总损失:$L \leftarrow L_{recon} + \beta L_{KL}$
9:更新$(\phi, \theta) \leftarrow \text{grad\_update}(\mathcal{L})$
10:结束
- 解码器方差。学习高斯解码器方差 $\sigma_{\theta}^{2}$ 在数值上可能很微妙,并且可能会导致退化的解决方案,除非进行正则化。为了稳定性,许多实现将 $p_{\theta}(x|z) = \mathcal{N}(x;\mu_{\theta}(z),\sigma^{2}I_{d})$ 修复为常量 $\sigma^2$ ,这使得重建项与均方误差成正比(最多为常量)。
- 超出像素 MSE 的重建损失。对于图像,像素级高斯似然(均方误差)通常会产生过于平滑的重建。在实践中,人们添加感知损失(使用预训练网络的特征空间损失)来提高清晰度和语义保真度。
- 对抗性和混合性目标。为了进一步提高视觉真实感,可以在解码样本上使用鉴别器,将 VAE 目标与对抗性损失(VAE-GAN 风格)结合起来。这通常会锐化输出,但会引入额外的优化不稳定性和额外的超参数。
备注 32(在latent 空间中工作)
为了训练潜在生成式模型,我们只需遵循现有的训练方法,但直接在latent 空间中工作。在训练时,我们从以下位置抽取样本 $q_{\phi}(z|x)$ 和 $x \sim p_{data}$ ,在推理时,我们从潜在扩散或流动模型中采样 z,然后使用进行解码 $x = \mu_{\mathrm{mean}}(z)$ (请注意,我们采用平均值而不是随机样本,以避免噪声引起的伪影)。直观地说,训练有素的自编码器可以被认为过滤掉高频或其他语义上无意义的细节,从而允许生成式模型“专注于”重要的、感知相关的特征 [36]。在撰写本文档时,几乎所有最先进的图像和视频生成方法都遵循所谓的潜在扩散范式,涉及在自编码器的latent 空间内训练流或扩散模型 [36, 48]。然而,需要注意的是:在训练扩散模型之前还需要训练自编码器。至关重要的是,现在的性能还取决于自编码器将图像压缩到latent 空间并恢复美观图像的效果。
我们在 D 节中提供了有关 VAE 的额外讨论。
6.3 案例研究:Stable Diffusion 3 和 Meta Movie Gen
我们通过简要研究两个大型生成式模型来结束本节:用于图像生成的 Stable Diffusion 3 和用于视频生成的 Meta 的 Movie Gen Video [14, 33]。正如您将看到的,这些模型使用我们在这项工作中描述的技术以及额外的架构增强功能来扩展和适应丰富的结构化条件模式,例如基于文本的输入。
6.3.1 稳定扩散3
稳定扩散是一系列最先进的图像生成式模型。这些模型是最早使用大规模潜在扩散模型进行图像生成的模型。如果您还没有这样做,我们强烈建议您自行在线测试 (https://stability.ai/news/stable-diffusion-3)。
稳定扩散 3 使用与我们在这项工作中研究的相同的条件流匹配目标(参见算法 4)。 $^{4}$ 正如他们的论文中所述,他们广泛测试了各种流量和扩散替代方案,并发现流匹配性能最佳。对于训练,它使用如上所述的无分类器引导训练(删除类别标签)。此外,稳定扩散 3 遵循第 6.1 节中概述的方法,通过在预训练自编码器的latent 空间内进行训练。训练一个好的自编码器是第一篇稳定扩散论文的一大贡献。
为了增强文本调节,Stable Diffusion 3 使用 3 种不同类型的文本嵌入(包括 CLIP 嵌入以及由 Google T5-XXL [35] 编码器的预训练实例产生的顺序输出,与 [3, 39] 中采用的方法类似)。 CLIP 嵌入提供了输入文本的粗略、总体嵌入,而 T5 嵌入提供了更细粒度的上下文级别,允许模型关注调节文本的特定元素。为了适应这些顺序上下文嵌入,作者随后建议扩展扩散变换器,不仅关注图像的补丁,还关注文本嵌入,从而将调节能力从最初为 DiT 提出的基于类的方案扩展到顺序上下文嵌入。这种提议的修改后的 DiT 被称为多模态 DiT (MM-DiT),如图 16 所示。他们最终的最大模型有 80 亿个参数。对于采样,他们使用欧拉模拟方案和 2.0-5.0 之间的无分类器引导权重,使用 50 个步骤(即必须评估网络 50 次)。
6.3.2 元电影生成视频
接下来,我们讨论 Meta 的视频生成器 Movie Gen Video (https://ai.meta.com/research/movie-gen/)。由于数据不是图像而是视频,因此数据 $x$ 位于空间 $\mathbb{R}^{T\times C\times H\times W}$ 中,其中 $T$ 表示新的时间维度(即帧数)。正如我们将看到的,在此视频设置中做出的许多设计选择可以被视为改编图像设置中的现有技术(例如,自编码器、扩散变换器等)来处理这种额外的时间维度。
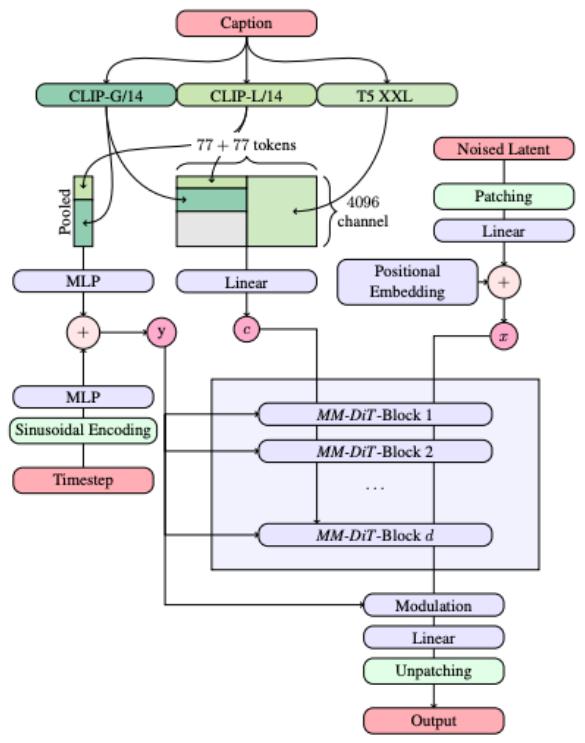
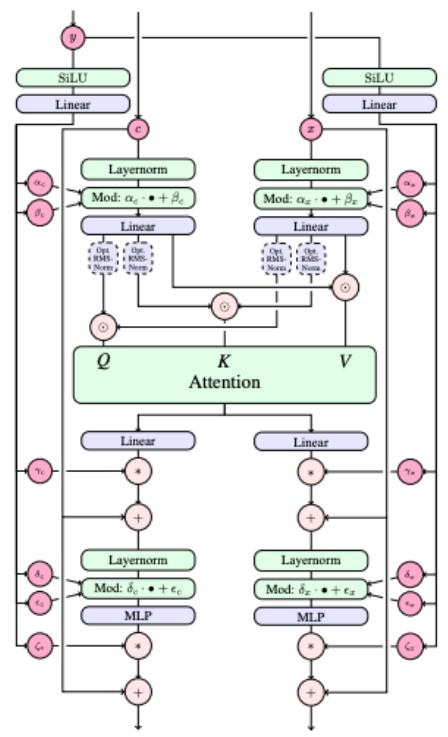
Movie Gen Video 利用条件流匹配目标和相同的直线调度程序 $\alpha_{t}=t,\sigma_{t}=1-t$ 。与 Stable Diffusion 3 一样,Movie Gen Video 也在冻结的、预训练的自编码器的latent 空间中运行。请注意,用于减少内存消耗的自编码器对于视频来说比图像更重要 - 这就是为什么现在大多数视频生成器生成的视频长度非常有限。具体来说,作者建议通过引入时间自编码器(TAE)来处理增加的时间维度,该自编码器将原始视频 $x_{t}^{\prime}\in R^{T^{\prime}\times3\times H\times W}$ 映射到潜在的 $x_{t}\in R^{T\times C\times H\times W}$ ,并带有 $\frac{T^{\prime}}{T}=\frac{H^{\prime}}{H}=\frac{W^{\prime}}{W}=8$ [33] 。为了适应长视频,提出了一种时间平铺程序,通过该程序将视频分割成多个片段,每个片段分别进行编码器,并将潜在图像缝合在一起[33]。模型本身 - 即 $u_{t}^{\theta}(x_{t})$ - 由类似 DiT 的主干给出,其中 $x_{t}$ 沿时间和空间维度进行修补。然后,图像块通过变压器,该变压器采用图像块之间的自注意力以及与语言模型嵌入的交叉注意力,类似于 Stable Diffusion 3 使用的 MM-DiT。对于文本调节,Movie Gen Video 采用三种类型的文本嵌入:UL2 嵌入,用于基于粒度的基于文本的推理 [47],ByT5 嵌入,用于关注字符级细节(例如例如,prompt明确要求存在特定文本)[50],以及在共享文本图像嵌入空间 [24, 33] 中训练的 MetaCLIP 嵌入。他们最终最大的模型有 300 亿个参数。为了获得更详细和更广泛的处理,我们鼓励读者查看 Movie Gen 技术报告本身 [33]。
7 离散扩散模型:通过扩散构建语言模型
在前面的部分中,我们探索了作为欧几里得空间 $\mathbb{R}^d$ 上的生成式模型的流模型与扩散模型,它允许我们生成由向量 $z\in \mathbb{R}^d$ 表示的数据点。然而,并非所有数据都自然地建模为欧几里得空间 $\mathbb{R}^d$ 中的点。许多数据类型(例如文本或 DNA)更自然地被视为离散状态空间 $S$ 的元素。最重要的是,语言由我们想要建模的一系列离散标记组成。我们如何将流模型与扩散模型应用于此类数据类型?事实证明,我们在前面几节中学到的原理也适用于此类数据类型。所得模型在机器学习文献 [5, 16] 中称为离散扩散模型。然而,重要的是要记住,不存在数学扩散过程(SDE 不存在于离散状态空间中)。我们不使用 ODE/SDE,而是使用连续时间马尔可夫链 (CTMC)。接下来,我们将解释 CTMC 模型(参见第 7.1 节)以及如何学习它们(参见第 7.2 节),使我们能够使用流模型和扩散模型的原理构建大型语言模型(LLM)。
7.1 连续时间马尔可夫链(CTMC)模型
在本节中,我们将解释连续时间马尔可夫链(CTMC)。您可以将 CTMC 视为 SDE 的离散类似物,我们可以使用它来构建生成离散状态的神经网络模型。此外,我们将介绍 CTMC 模型,即允许使用 CTMC 生成离散序列(例如文本)的神经网络模型。
让我们首先描述我们的状态空间 S。让 $V = \{v_{1}, \cdots, v_{V}\}$ 作为我们的词汇表。状态空间由 $S = V^{d}$ 给出,其中 $d \in N$ 是序列长度,$V \in N$ 是词汇表大小。对于语言, $\{v_{1}, \cdots, v_{V}\}$ 可以枚举我们的字母表或一组离散标记,而 S 代表长度为 d 的序列(或句子)集。对于 DNA,$\{v_{1}, \cdots, v_{V}\}$ 可以是所有 4 个 DNA 碱基,并且 S 可以是长度为 d 的所有 DNA 序列。
接下来,令$X_{t}$为S上的随机过程,即S中的随机轨迹$X : [0,1] \to S, t \mapsto X_{t}$。我们要求$X_{t}$为马尔可夫过程,即没有记忆的过程。具体来说,这意味着以下条件成立
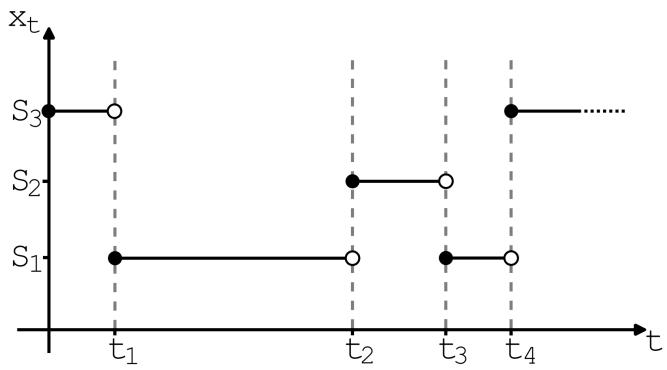
$$ \underbrace {p (X _ {t + h} | X _ {t} , X _ {t _ {1}} , \cdots , X _ {t _ {k}})} _ {\text {prob. of future given present and past}} = \underbrace {p (X _ {t + h} | X _ {t})} _ {\text {prob. of future given present}} \quad \text {(for all 0 < h, 0\leq t_{1} < t_{2} < \cdots < t_{k} < t)} $$
换句话说,未来事件的概率仅取决于现在——过去与未来不再相关。请注意,ODE/SDE(虽然不在离散状态空间上)也是马尔可夫过程。这里,$X_{t}$位于离散空间上,因此被称为马尔可夫链,特别是连续时间马尔可夫链(CTMC)。数量 $p_{t + h|t}(X_{t + h}|X_t)$ 是转移概率,它们与马尔可夫链的初始分布 $X_0 \sim p_0$ 一起完全确定 CTMC。因此,当我们说 CTMC 时,您也可以只考虑转移概率 $p_{t + h|t}(X_{t + h}|X_t)$ 。
接下来,让我们推导离散设置中矢量场的模拟。由于我们处于离散设置中,我们只能在状态之间跳转(或切换) - 我们不能再像指定 ODE 时那样进入一个方向。因此,我们定义了一个速率矩阵 $Q_{t}(y|x)$ ,它有效地总结了从状态 $x \in S$ 跳转(或切换)到状态 $y \in S$ 的速率。形式上,速率矩阵 $Q_{t}$ 由有界函数(时间连续)给出
$$ Q: S \times S \times [ 0, 1 ] \rightarrow \mathbb {R}, \quad (x, y, t) \mapsto Q _ {t} (y | x) \tag {84} $$
其中 $Q_{t}(y|x)$ 描述从 x 到 y 的切换速率,使得
(1) 流出率为正: $Q_{t}(y|x)\geq 0$ 每当 $x\neq y$ (85)
(2) 停留率等于负流出率:$Q_{t}(x|x) = -\sum_{y \neq x} Q_{t}(y|x)$ 对于所有 $x$ (86)
这两个条件很直观:第一个条件表示从 x 切换到不同状态 $y \neq x$ 的速率只能是非负的(不切换只对应于 0 - 因此小于 0 的速率是没有意义的)。第二个条件表示,留在 x 的比率 $Q_{t}(x|x)$ 应与离开 x 的比率相抵消 - 这本质上是一个一致性条件,表示您必须留在 x 或离开(没有第三种选择)。请注意,这些条件特别意味着 $Q_{t}(x|x) \leq 0$ 。因此, $Q_{t}(y|x)$ 是一个矩阵,其对角线项均为非正,而所有非对角线项均为非负。
我们现在可以定义微分方程的模拟,即 CTMC“遵循”速率矩阵的条件。这个想法基本上是 X 的分布或演化应该遵循速率矩阵 $Q_{t}$ 。换句话说,我们要求转移概率满足
$$ \frac {\mathrm{d}}{\mathrm{d} h} p _ {t + h \mid t} (X _ {t + h} = y \mid X _ {t} = x) _ {| h = 0} = Q _ {t} (y \mid x) \quad \text { for all } x, y \in S, 0 \leq t \tag {87} $$
左边是从切换概率的无穷小变化率 $x$ 到 $y$ 。我们施加的条件是这些概率应按照速率矩阵的指定进行变化。让我们简单地检查一下请求这些条件是否合理,即我们简单地设置 $Q_{t}(y|x)$ 如方程(87)所示,它是一个有效的速率矩阵吗?为了 $h = 0$ ,从切换的概率 $x$ 到 $y \neq x$ 为零(因为没有时间过去),即 $p_{t|t}(y|x) = 0$ 为所有人 $y \neq x$ 。因此,我们知道导数一定是非负的,并且 $Q_{t}(y|x) \geq 0$ 每当 $y \neq x$ 。这将检查等式 (85) 中的第一个条件是否成立。进一步,我们知道
$$ \begin{array}{l} \sum_ {y \neq x} Q _ {t} (y | x) = \sum_ {y \neq x} \frac {\mathrm{d}}{\mathrm{d} h} p (X _ {t + h} = y | X _ {t} = x) _ {| h = 0} = \frac {\mathrm{d}}{\mathrm{d} h} \sum_ {y \neq x} p (X _ {t + h} = y | X _ {t} = x) _ {| h = 0} = \frac {\mathrm{d}}{\mathrm{d} h} (1 - p (X _ {t + h} = x | X _ {t} = x)) \\ = - Q _ {t} (x | x) \\ \end{array} $$
我们使用的概率总和为 1。这显示了方程 (86)。这会检查每个 CTMC 是否至少有一个满足方程 (87) 的速率矩阵。但是如果我们倒退——如果我们指定 $Q_{t}$ ,是否有相应的 CTMC,如果有,它是唯一的吗?情况确实如此。
定理33(CTMC存在唯一性)
对于任何速率矩阵 $Q_{t}$ (在时间 t 内有界且连续),存在唯一的马尔可夫链 $X_{t}$ (即一组唯一的转移概率 $p_{t+h|t}(y|x)$ ),使得方程(87)成立。
对于感兴趣的读者,我们在 C 节中提供了一个独立的证明。该定理的关键要点是,出于机器学习的目的,我们可以构造一个速率矩阵 $Q_{t}$ (例如通过神经网络),并假设存在一个与 $Q_{t}$ 相对应的唯一马尔可夫链。
示例34(具有相等跳转率的双状态CTMC)
让 $S = \{a, b\}$ 并考虑一个时间同质 CTMC $(X_t)_{t \geq 0}$ ,它以恒定速率 $\lambda > 0$ 在两种状态之间切换:
$$ Q = \begin{array}{c c c} & a & b \\ \hline a & - \lambda & \lambda \\ b & \lambda & - \lambda \end{array} . $$
那么时间增量 $h \geq 0$ 上的转移概率在时间 t 上也是恒定的,由下式给出
$$ \left( \begin{array}{c c} p (X _ {t + h} = a | X _ {t} = a) & p (X _ {t + h} = a | X _ {t} = b) \\ p (X _ {t + h} = b | X _ {t} = a) & p (X _ {t + h} = b | X _ {t} = b) \end{array} \right) = \frac {1}{2} \left( \begin{array}{c c} 1 + e ^ {- 2 \lambda h} & 1 - e ^ {- 2 \lambda h} \\ 1 - e ^ {- 2 \lambda h} & 1 + e ^ {- 2 \lambda h} \end{array} \right). $$
人们可以手动检查等式(87)是否成立,即这些转移概率确实是该速率矩阵的正确概率。事实上,这些速率非常直观:链条以瞬时速率 $\lambda$ 不断翻转。指数项 $e^{-2\lambda h}$ 描述了初始状态的记忆如何衰减。随着无限时间的流逝,即对于 $h \to \infty$ ,它认为
$$ P (h) \to \left( \begin{array}{c c} \frac {1}{2} & \frac {1}{2} \\ \frac {1}{2} & \frac {1}{2} \end{array} \right), $$
因此该链忘记了它的起始位置,并且处于 $a$ 或 $b$ 中,概率为 $1/2$ 。切换速率 $\lambda > 0$ 越高,收敛速度越快。
CTMC模拟。接下来,让我们考虑如何模拟 CTMC 的轨迹。令 h > 0 为步长,$p_{init}$ 为 S 上的初始分布,例如$p_{init} = Unif_{S}$ 是 S 上的均匀分布。然后我们可以通过设置 $X_{0} \sim p_{init}$ 和设置来迭代模拟它
$$ X _ {t + h} \sim p _ {t + h | t} (\cdot | X _ {t}) $$
现在,如果我们知道 $p_{t+h|t}(\cdot|X_t)$ ,这就会起作用。然而,对于除了最简单的 CTMC 之外的所有 CTMC,我们通常不知道封闭形式的转换内核,只能访问速率矩阵 $Q_t$ 。尽管如此,根据方程(87):
$$ p _ {t + h | t} (X _ {t + h} = y | X _ {t} = x) = p _ {t | t} (X _ {t} = y | X _ {t} = x) + h Q _ {t} (y | x) + R _ {t} (h) = 1 _ {y = x} + h Q _ {t} (y | x) + R _ {t} (h) $$
其中 $R_{t}(h)$ 是一个错误项,对于较小的 $h$ ,我们可以忽略它。因此,对于小的 $h$ ,我们可以设置
$$ p _ {t + h | t} (X _ {t + h} = y | X _ {t} = x) \approx 1 _ {y = x} + h Q _ {t} (y | x) =: \tilde {p} _ {t + h | t} (y | x) $$
通过我们对速率矩阵施加的条件,可以检查 $\tilde{p}_{t+h|t}(y|x)$ 确实是小 h 的有效概率分布。因此,我们可以通过以下方式近似采样下一个点
$$ X _ {t + h} \sim \tilde {p} _ {t + h | t} (\cdot | x) = (1 _ {y = x} + h Q _ {t} (y | x)) _ {y \in S} \tag {88} $$
由于上面只是一个离散分布,我们可以通过标准方法轻松地从中采样。这是模拟 CTMC 的简单方法。
CTMC模型。接下来,让我们定义如何在神经网络中参数化 CTMC。 CTMC 模型(或离散扩散模型)由初始分布给出 $p_{init}$ 通过 S 和神经网络 $Q_{t}^{\theta}$ 带参数 $\theta$ 这样对于每个输入 $x \in S$ 该模型返回速率矩阵的单列
$$ x \mapsto \{Q _ {t} ^ {\theta} (y | x) \} _ {y \in S} $$
我们希望模型返回整个列,因为我们需要它来模拟 CTMC(方程(88)),即采样下一个状态。
上述模型的一个复杂问题是空间 S 可能非常大。特别是 $|S| = V^{d}$ ,其中 V 是我们的词汇量大小,d 是序列长度。这种指数增长使得基本上不可能将速率矩阵的整个列存储在内存中 - $\{Q_{t}^{\theta}(y|x)\}_{y\in S}$ 永远无法在计算机中表示。因此,我们必须对模型进行约束。具体来说,几乎所有 CTMC 模型都被分解(见图 18),这实际上是一个稀疏约束。具体来说,因式分解的 CTMC 模型由 CTMC 模型 $Q_{t}^{\theta}$ 给出,使得对于所有 $y = (y_{1}, \cdots, y_{d}), x = (x_{1}, \cdots, x_{d}) \in S = \mathcal{V}^{d}$ 它保持
$$ Q _ {t} ^ {\theta} (y | x) = 0 \quad \mathrm{whenever} y _ {i} \neq x _ {i} \mathrm{formorethanoneposition} i $$
我们打电话给所有 $y$ 不同于 $x$ 邻居最多有一个令牌 $N(x)$ 的 $x$ 。我们可以将分解的 CTMC 模型写为
$$ x \mapsto \{Q _ {t} ^ {\theta} (y | x) \} _ {y \in N (x)} = \left( \begin{array}{c c} Q _ {t} ^ {\theta} (v _ {1}, 1 | x) & \dots Q _ {t} ^ {\theta} (v _ {V}, 1 | x) \\ \dots & \\ Q _ {t} ^ {\theta} (v _ {1}, d | x) & \dots Q _ {t} ^ {\theta} (v _ {V}, d | x) \end{array} \right) $$
其中 $Q_{t}(y|x)=Q_{t}^{\theta}(v_{i},j|x)$ 现在给出从 $x=(x_{1},\cdots,x_{d})$ 到 x 的邻居的速率,我们用 $v_{i}$ 交换第 j 个元素,即 $y=(x_{1},\cdots,x_{j-1},v_{i},x_{j+1},\cdots,x_{d})$ 。每行对应于每个位置 $i=1,\cdots,d$ 的速率矩阵,即我们需要
$$ Q _ {t} ^ {\theta} (v, i | x) \geq 0 \text { if } v \neq x _ {i}, \quad Q _ {t} (x _ {i}, i | x) = - \sum_ {v \neq x _ {i}} Q _ {t} ^ {\theta} (v, i | x) $$
我们可以轻松地在神经网络的输出上强制执行这些条件,例如可以在序列长度 d 和输出维度 V 上使用变换器模型。另请注意,因式分解的速率矩阵使输出形状为 $d \times V$ - 该大小在维度上线性增加(而不是指数增加)。
模拟 CTMC 模型。为了从 CTMC 模型中采样,我们对 $X_{0} \sim p_{init}$ 进行采样,并执行迭代,根据方程 (88) 对下一个状态进行采样。我们在算法 7 中提出了一种算法。如图所示,对于因式分解的 CTMC 模型,可以使用并行的每个令牌欧拉近似,其中每个令牌在小步长 h > 0 期间独立更新。该近似与 h > 0 中的完整 CTMC 欧拉步骤一致,但允许同时更新多个令牌的 $O(h^{2})$ 概率。
通用率矩阵
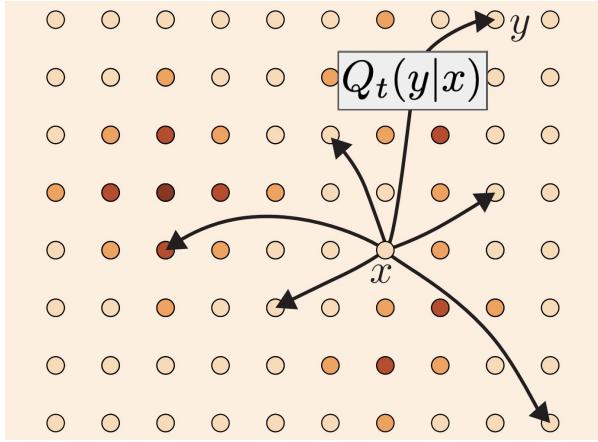
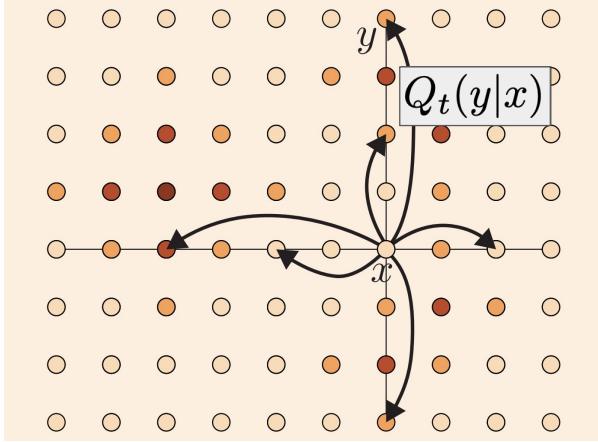
算法 7 从因式分解 CTMC 模型中采样
要求:速率网络 $Q_{t}^{\theta}$ (因式分解),初始分布 $p_{init}$ ,步数 n
1: 设置 $t \leftarrow 0$ ,步长 $h \leftarrow \frac{1}{n}$ 2: 绘制样本 $X_{0} \sim p_{init}$ ,其中 $X_{0} = (X_{0}^{(1)}, \ldots, X_{0}^{(d)}) \in \mathcal{V}^{d}$ 3: 对于 $i = 1, \ldots, n$ 做
4:计算因子跳转率 $\{q_{j}(v)\}_{j=1..d, v \in V} \leftarrow Q_{t}^{\theta}(\cdot \mid X_{t})$ 5:对于 $j = 1, \ldots, d$ (并行)执行
6: $x \leftarrow X_{t}^{(j)}$ {位置 j 处的当前标记}
7:定义每个位置的欧拉转移概率 $\tilde{p}_{j,t}(\cdot \mid X_{t}^{(j)} = x)$ 通过
$$ \tilde {p} _ {j, t} (v \mid x) = \left\{ \begin{array}{l l} h q _ {j} (v), & v \neq x, \\ 1 - h \sum_ {v ^ {\prime} \in \mathcal {V} \setminus \{x \}} q _ {j} (v ^ {\prime}), & v = x. \end{array} \right. $$
8:示例 $X_{t+h}^{(j)} \sim \text{CATEGORICAL}(\{\tilde{p}_{j,t}(v \mid x)\}_{v \in \mathcal{V}})$ 9:结束 10: 设置 $t \leftarrow t + h$ 11: 结束 12:返回$X_{1}$
7.2 训练CTMC模型
接下来我们讨论如何学习 CTMC 模型。其原理与流匹配相同:(1)我们构建噪声和数据之间插值的概率路径。 (2)我们推导出条件利率矩阵和边际利率矩阵。 (3) 我们以免模拟的方式学习边际利率矩阵。我们现在将逐步解释这个食谱。
在本节中,数据分布 $p_{data}$ 是 S 上的分布,以概率质量函数为特征。即 $p_{\mathrm{data}} : S \to \mathbb{R}_{\geq 0}, z \mapsto p_{\mathrm{data}}(z)$ 和 $\sum_{z \in S} p_{\mathrm{data}}(z) = 1$ 。我们不知道$p_{data}$,但我们在训练期间以数据集的形式访问样本$z \sim p_{data}$。例如,万维网上的所有文本。我们的目标是学习生成样本 $z \sim p_{data}$ 。我们的目标是训练 CTMC 模型 $Q_{t}^{\theta}$ 使得
$$ X _ {0} \sim p _ {\mathrm{init}}, X _ {t} \mathrm{CTMCof} Q _ {t} ^ {\theta} \Rightarrow X _ {1} \sim p _ {\mathrm{data}} $$
正如您可能意识到的,这与欧几里得情况 $R^{d}$ (参见第 2 节和第 3 节)没有什么不同,只是我们使用 CTMC 模型而不是流动/扩散模型。
7.2.1 条件和边缘概率路径
我们定义 $\delta_{z}(x)$ 具有这样的功能 $\delta_{z}(x)=0$ 如果 $x\neq z$ 和 $\delta_{z}(x)=1$ 如果x=z。 (离散)条件概率路径由一组分布给出 $p_{t}(x|z)$ 为了 $x,z\in S$ 和 $0\leq t\leq1$ 这样
$$ p _ {0} (\cdot | z) = p _ {\mathrm{init}}, \quad p _ {1} (\cdot | z) = \delta_ {z} $$
与欧几里得情况类似,离散条件概率路径在独立于 $z$ 的分布和所有质量都在 $z$ 上的分布之间插值。 (离散)边缘概率路径由下式给出
$$ p _ {t} (x) = \sum_ {z \in S} p _ {t} (x | z) p _ {\mathrm{data}} (z) $$
人们可以轻松检查边缘概率路径是否插入了“噪声”和数据:
$$ p _ {0} = p _ {\text { init }}, \quad p _ {1} = p _ {\text { data }} \tag {89} $$
示例 35(因式分解混合路径(每个标记独立的噪声))
令 $S = \mathcal{V}^d$ 和 $p_{\mathrm{init}}(x) = \prod_{j=1}^{d} p_{\mathrm{init}}^{(j)}(x_j)$ 为因式分解的初始分布。修复调度程序 $0 \leq \kappa_t \leq 1$ ,以便 $\kappa_0 = 0, \kappa_1 = 1$ 和 $\frac{\mathrm{d}}{\mathrm{d}t} \dot{\kappa}_t \geq 0$ 。定义条件路径
$$ p _ {t} (x | z) = \prod_ {j = 1} ^ {d} \Big [ (1 - \kappa_ {t}) p _ {\mathrm{init}} ^ {(j)} (x _ {j}) + \kappa_ {t} \delta_ {z _ {j}} (x _ {j}) \Big ]. $$
同样,可以通过绘制 i.i.d 来采样 $x \sim p_{t}(\cdot \mid z)$。掩码 $m_{j} = 0, 1$ 和噪声 $\xi_{j} \sim p_{\mathrm{init}}^{(j)}$ ,然后设置
$$ m _ {j} \sim \mathrm{Bernoulli} (\kappa_ {t}), \quad \xi_ {j} \sim p _ {\mathrm{init}} ^ {(j)} $$
$$ x _ {j} = m _ {j} z _ {j} + (1 - m _ {j}) \xi_ {j}, \quad j = 1, \dots , d $$
$$ x = (x _ {1}, \dots , x _ {d}) $$
我们将上述称为分解混合路径。上述过程以 $1 - \kappa_{t}$ 的概率有效地独立地“销毁”序列中每个位置的第 j 个令牌,即对于 $t = 0 \quad 1 - \kappa_{t} = 1$ 且所有信息都被销毁,对于 t = 1 则认为 $1 - \kappa_{t} = 0$ 并且没有信息被销毁。请注意,这与高斯概率路径示例 8 类似,信息以调度程序 $\kappa_{t}$ 确定的速度逐渐被破坏。然而,它也不同于高斯概率路径,因为因式分解的混合路径不会移动/传输概率质量(因为我们在离散空间中,所以没有方向)——它只是淡入一种分布并淡出另一种分布。
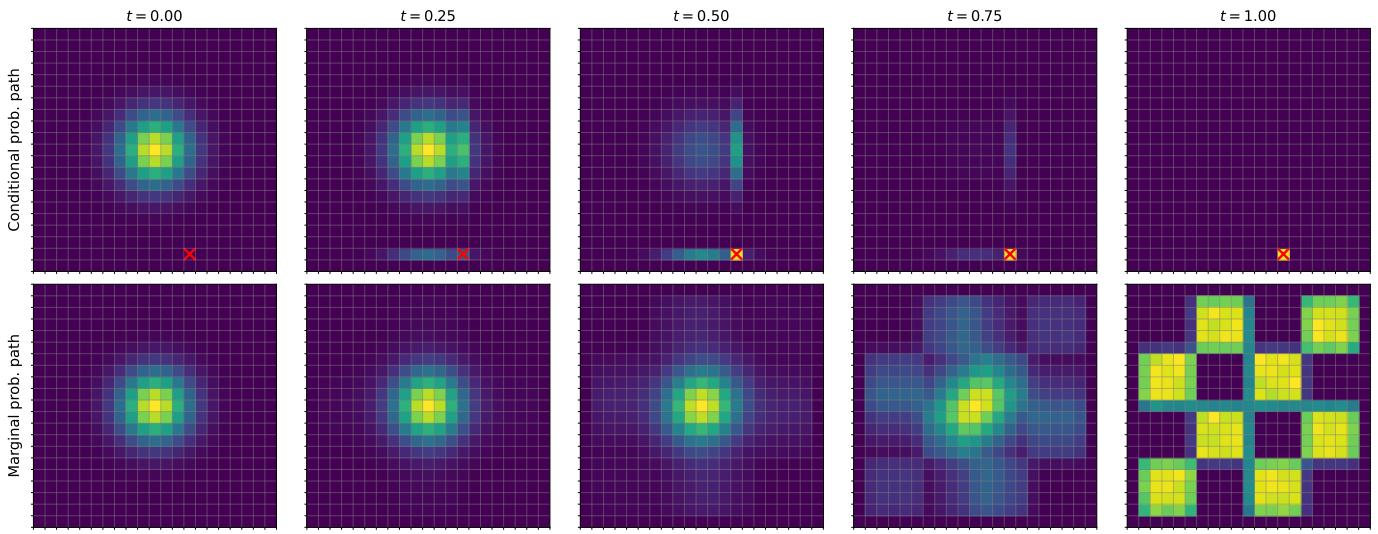
7.2.2 条件和边际利率矩阵
下一步,我们将构建离散流匹配的训练目标。首先,我们构造一个条件速率矩阵 - 类似于流匹配的条件向量场。令 $Q_{t}^{z}(y|x)$ 为每个数据点 $z \in S$ 的速率矩阵。那么我们称其为条件率矩阵如果
$$ X _ {0} \sim p _ {\mathrm{init}}, X _ {t} \mathrm{CTMCof} Q _ {t} ^ {z} \Rightarrow X _ {t} \sim p _ {t} (\cdot | z) $$
换句话说,条件率矩阵使得其 CTMC“遵循”条件概率路径。条件利率矩阵作为构建块来构建遵循边缘概率路径的边际利率矩阵:
定理36(离散边缘化技巧)
边际利率矩阵定义为
$$ Q _ {t} (y | x) = \sum_ {z \in S} Q _ {t} ^ {z} (y | x) \frac {p _ {t} (x | z) p _ {\text { data }} (z)}{p _ {t} (x)} = \sum_ {z \in S} Q _ {t} ^ {z} (y | x) p _ {1 | t} (z | x) \quad \text { where } p _ {1 | t} (z | x) := \frac {p _ {t} (x | z) p _ {\text { data }} (z)}{p _ {t} (x)} \tag {90} $$
是一个有效的速率矩阵并且满足以下条件:
$$ X _ {0} \sim p _ {\mathrm{init}}, X _ {t} \text {CTMC of} Q _ {t} \Rightarrow X _ {t} \sim p _ {t} $$
特别地,式(89)的$X_{1} \sim p_{data}$,即边际率矩阵的CTMC将噪声转换为数据。
为了证明这一说法,我们需要一个 CTMC 的基本方程,即所谓的柯尔莫哥洛夫前向方程:
命题2(柯尔莫哥洛夫前向方程)
让 $p_t$ 是一组分布 $S$ 对于每一个 $0 \leq t \leq 1$ 。进一步,让 $X_t$ 成为具有矩阵的 CTMC $Q_t$ 和初始分布 $p_0$ 。然后 $X_t \sim p_t$ 为所有人 $0 \leq t \leq 1$ 当且仅当柯尔莫哥洛夫远期方程 (KFE) 成立:
$$ \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} (x) = \sum_ {y \in S} Q _ {t} (x | y) p _ {t} (y) $$
KFE 证明。为了证明 KFE 是必要的,假设 $p_t(x)$ 是 CTMC 的真实边际,即 $X_t \sim p_t$ 对于每一个 $0 \leq t \leq 1$ 。然后我们可以计算:
$$ \begin{array}{l} \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} (x) \stackrel {(i)} {=} \frac {\mathrm{d}}{\mathrm{d} h} _ {| h = 0} p _ {t + h} (x) \\ \stackrel {(i i)} {=} \frac {\mathrm{d}}{\mathrm{d} h} _ {| h = 0} \sum_ {y} p _ {t + h | t} (x | y) p _ {t} (y) \\ \stackrel {(i i i)} {=} \sum_ {y} \frac {\mathrm{d}}{\mathrm{d} h} _ {| h = 0} p _ {t + h | t} (x | y) p _ {t} (y) \\ \stackrel {(i v)} {=} \sum_ {y} Q _ {t} (x | y) p _ {t} (y) \\ \end{array} $$
其中,在 (i) 中我们简单地使用时间偏移,在 (ii) 中我们使用转移概率的定义,在 (iii) 中我们交换总和和导数,在 (iv) 中我们使用速率矩阵的定义(参见方程(87))。
接下来,为了证明 KFE 是足够的,我们可以将 KFE 重写为矩阵形式:
$$ \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} = Q _ {t} p _ {t} $$
在此等式中,我们将 $p_{t} = (p_{t}(x))_{x \in S}$ 视为向量,将 $Q_{t} = (Q_{t}(y|x))_{x,y \in S}$ 视为矩阵。请注意,上面是向量空间 $R^{S}$ 上的线性常微分方程。如定理中所述,其初始条件由 $p_{0}$ 确定。因此,如果任何其他边际集 $q_{t}$ 满足该方程,我们知道通过 ODE 的唯一性(参见定理 3),我们可以得出 $q_{t} = p_{t}$ 的结论。这说明KFE也足够了。 ⑨
定理 36 的证明。使用 KFE,仍需证明定理中定义的边际利率矩阵(参见方程(90))满足 KFE:
$$ \begin{array}{l} \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} (x) \stackrel {(i)} {=} \frac {\mathrm{d}}{\mathrm{d} t} \sum_ {z \in S} p _ {t} (x | z) p _ {\mathrm{data}} (z) \\ \stackrel {(i i)} {=} \sum_ {z \in S} \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} (x | z) p _ {\mathrm{data}} (z) \\ \stackrel {(i i i)} {=} \sum_ {z \in S} \left[ \sum_ {y \in S} Q _ {t} ^ {z} (x | y) p _ {t} (y | z) \right] p _ {\text { data }} (z) \\ \stackrel {(i v)} {=} \sum_ {y \in S} p _ {t} (y) \left[ \sum_ {z \in S} Q _ {t} ^ {z} (x | y) \frac {p _ {t} (y | z) p _ {\text { data }} (z)}{p _ {t} (y)} \right] \\ \stackrel {(v)} {=} \sum_ {y \in S} p _ {t} (y) Q _ {t} (x | y) \\ \end{array} $$
其中 $(i)$ 遵循边缘概率路径的定义,在 $(ii)$ 中我们交换总和与导数,在 $(iii)$ 中我们使用条件利率矩阵上的 KFE,在 $(iv)$ 中我们乘以和除以 $p_{t}(y)$ ,在 $(v)$ 中我们使用边际利率矩阵 $Q_{t}(y|x)$ 的定义。这说明KFE已经实现了。该声明紧接着命题 2。 ☐
现在让我们导出分解混合路径的条件速率矩阵的具体示例。
示例37(因式分解混合路径的条件速率矩阵)
设置 $\frac{d}{dt}\kappa_{t}=\dot{\kappa}_{t}$ 。因式分解的混合路径具有因式分解的条件速率矩阵,由下式给出
$$ \begin{array}{l} Q _ {t} ^ {z} (y | x) = (Q _ {t} ^ {z} (v _ {i}, j | x _ {j})) _ {v _ {i}, j} \\ Q _ {t} ^ {z} (v _ {i}, j | x _ {j}) = \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z _ {j}} (v _ {i}) - \delta_ {x _ {j}} (v _ {i})) \\ = \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} \left\{ \begin{array}{l l} 0 & \text {if x_{j} = z_{j}} \\ 1 & \text {if v_{i} = z_{j} ,x_{j} \neq z_{j}} \\ 0 & \text {if v_{i} \neq z_{j} ,x_{j} \neq z_{j}} \\ - 1 & \text {if v_{i} = x_{j} ,x_{j} \neq z_{j}} \end{array} \right. \\ \end{array} $$
请注意,这是一个非常简单的速率矩阵:它只允许跳转到 $z^{j}$ - 即,如果任何令牌 j 被更新,它必须跳转到终端数据点 $z = (z_{1}, \cdots, z_{d})$ 的令牌值 - 并且如果我们还没有到达,它只会跳转到 $z^{j}$ 。
证明。我们注意到,因式分解的混合路径完全因式分解为独立分量,建议的条件速率矩阵也是如此。因此,我们可以不失一般性地假设 d = 1。因此我们只对每个维度进行计算。那么,我们可以推导出:
$$ \begin{array}{l} \frac {\mathrm{d}}{\mathrm{d} t} p _ {t} (x | z) \stackrel {(i)} {=} \frac {\mathrm{d}}{\mathrm{d} t} \left[ (1 - \kappa_ {t}) p _ {\text { init }} (x) + \kappa_ {t} \delta_ {z} (x) \right] \\ \stackrel {(i i)} {=} \dot {\kappa} _ {t} \delta_ {z} (x) - \dot {\kappa} _ {t} p _ {\mathrm{init}} (x) \\ \stackrel {(i i i)} {=} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z} (x) - [ (1 - \kappa_ {t}) p _ {\mathrm{init}} (x) + \kappa_ {t} \delta_ {z} (x) ]) \\ \stackrel {(i v)} {=} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z} (x) - p _ {t} (x | z)) \\ \stackrel {(v)} {=} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} \delta_ {z} (x) \left(1 - p _ {t} (x | z)\right) + \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z} (x) - 1) p _ {t} (x | z) \\ \stackrel {(v i)} {=} \sum_ {y \neq x} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} \delta_ {z} (x) p _ {t} (y | z) + \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z} (x) - 1) p _ {t} (x | z) \\ \stackrel {(v i i)} {=} \sum_ {y \neq x} Q _ {t} ^ {z} (x | y) p _ {t} (y | z) + Q _ {t} ^ {z} (x | x) p _ {t} (x | z) \\ \stackrel {(v i i i)} {=} \sum_ {y \in S} Q _ {t} ^ {z} (x | y) p _ {t} (y | z) \\ \end{array} $$
其中 $(i)$ 使用 d = 1 的分解混合路径的定义, $(ii)$ 通过求导并设置 $\frac{d}{dt}\kappa_t = \dot{\kappa}_t$ 获得, $(iii)$ 遵循简单代数, $(iv)$ 遵循分解混合路径的定义, $(v)$ 遵循简单代数, $(vi)$ 遵循 $\sum_{y \in S} p_t(y|z) = 1$ 的定义, $(vii)$ 通过速率矩阵的定义,而 $(viii)$ 通过简单代数。以上表明 KFE 已满足,因此声明如下。
7.2.3 学习边际利率矩阵
在本节中,我们推导了训练 CTMC 模型的基本算法。根据定理36,训练CTMC模型$Q_{t}^{\theta}(y|x)$可以通过学习边际率矩阵来实现。
在本节中,我们现在将自己限制在分解混合路径(参见示例 35),因为这是迄今为止大多数离散扩散/流动匹配模型使用的路径。在这种情况下,边际利率矩阵具有非常直观的形状:
定理 38(分解混合路径的边缘化技巧)
因式分解混合路径的边际速率矩阵被因式分解并具有以下形式
$$ Q _ {t} (v _ {i}, j | x) = \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (p _ {1 | t} (z _ {j} = v _ {i} | x) - \delta_ {x _ {j}} (v _ {i})) $$
其中 $p_{1|t}(z_{j}=v_{i}|x)$ 是在给定完整噪声序列 x 的情况下,第 j 个位置(序列中的第 j 个标记)等于 $v_{i}$ 的条件概率。
证明。边际利率矩阵由下式给出
$$ Q _ {t} (y | x) = \sum_ {z \in S} Q _ {t} ^ {z} (y | x) p _ {1 | t} (z | x) \tag {91} $$
现在,每当 y 和 x 不是邻居(相差多个标记)时,每个 z 都会 $Q_{t}^{z}(y|x)=0$ 。因此,在这种情况下也 $Q_{t}(y|x)=0$ 。这表明边际利率矩阵也会因式分解。那么它认为
$$ Q _ {t} (v _ {i}, j | x) = \sum_ {z \in S} Q _ {t} ^ {z} (v _ {i}, j | x) p _ {1 | t} (z | x) \tag {92} $$
$$ \stackrel {(i)} {=} \sum_ {z \in S} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} (\delta_ {z _ {j}} (v _ {i}) - \delta_ {x _ {j}} (v _ {i})) p _ {1 | t} (z | x) \tag {93} $$
$$ \stackrel {(i i)} {=} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} \left(\sum_ {z \in S} \delta_ {z _ {j}} (v _ {i}) p _ {1 | t} (z | x) - \delta_ {x _ {j}} (v _ {i})\right) \tag {94} $$
$$ \stackrel {(i i i)} {=} \frac {\dot {\kappa} _ {t}}{1 - \kappa_ {t}} \left(p _ {1 | t} (z _ {j} = v _ {i} | x) - \delta_ {x _ {j}} (v _ {i})\right) \tag {95} $$
其中 (i) 遵循条件率矩阵的公式(参见示例 37),(ii) 遵循 $\sum_{z\in S}p_{1|t}(z|x) = 1$ 的事实,(iii) 遵循边缘化。至此证明完毕。
前面的定理很值得注意:边际利率矩阵实际上是概率 $p_{1|t}(z_{j}=v_{i}|x)$ 的重新参数化。这实际上只不过是为每个标记位置 $j=1,\ldots,d$ 学习一个分类器。换句话说,我们可以简单地将去噪概率网络定义为
$$ p _ {1 | t} ^ {\theta}: \underbrace {x} _ {\text { network input }} \mapsto \underbrace {(p _ {1 | t} ^ {\theta} (z _ {j} = v _ {i} | x)) _ {j = 1 , \cdots , d , v _ {i} \in \mathcal {V}}} _ {\text { network output }} $$
请注意,网络输出的形状为 $d \times V$ 。我们可以通过简单的 softmax 层获得每个 token 位置的概率。网络本身可以是标准的序列到序列网络,例如变压器工作(见第 6.1.2 节)。
由于这只是每个位置 j 的分类器,因此我们可以通过每个 $j = 1, \cdots, d$ 的交叉熵损失来训练这样的网络。这导致离散流匹配损失由下式给出
$$ \mathcal {L} _ {\mathrm{DFM}} (\theta) = \mathbb {E} _ {z \sim p _ {\mathrm{data}}, t \sim \mathrm{Unif} _ {[ 0, 1 ]}, x \sim p _ {t} (\cdot | z)} \left[ \sum_ {j = 1} ^ {d} - \log p _ {1 | t} ^ {\theta} (z _ {j} | x) \right] $$
这是值得注意的:为了训练生成式模型,我们所需要做的就是为每个位置 j 训练一个分类器模型。与连续流匹配简化为简单回归(参见第 3 节)的方式相同,离散流匹配和离散扩散模型简化为简单的分类训练。在算法8中,我们总结了训练算法。训练后,我们可以通过算法 7 进行采样。
示例39(掩蔽扩散语言模型)
上述方法的一个具体例子是掩码扩散语言模型(MDLM)。 MDLM 的想法是,我们可以使用新的标记 [mask] 来扩展标记 $V = \{v_{1}, \cdots, v_{V}\}$ 的词汇表,该新标记表示该标记丢失(或被屏蔽)。具体来说,我们设置 $V = \{v_{1}, \cdots, v_{V}, [mask]\}$ ,初始点就是 $[mask]^{d}$ ,即全屏蔽的序列。形式上,这意味着在上述框架中设置 $p_{init} = \delta_{[mask]^{d}}$ 。采样过程如图 20 所示。
算法8 训练分解CTMC模型(离散扩散)
要求:序列 $z \sim p_{data}$ 和 $z = (z_1, \ldots, z_d) \in \mathcal{V}^d$ 的数据集;
V 上的初始(噪声)代币边际 $p_{\text{init}}^{(j)}$;安排 $\kappa_t \in [0, 1]$ ;
后网络 $f_\theta$ 返回 V 上的每个位置的 logits;优化器OPT
1:对于每次训练迭代
2:采样数据点 $z \sim p_{data}$ 3:采样时间 $t \sim \text{Unif}[0, 1]$ 并计算 $\kappa \leftarrow \kappa_t$ 4:采样噪声状态 $x \sim p_t(\cdot \mid z)$(分解混合路径):
5:对于 $j = 1, \ldots, d$ (并行)做
6: 样本掩码 $m_j \sim \text{Bernoulli}(\kappa)$ 7: 样本噪声标记 $\xi_j \sim p_{\text{init}}^{(j)}$ 8: 设置 $x_j \leftarrow m_j z_j + (1 - m_j) \xi_j$ 9: 结束
10: $x \leftarrow (x_1, \ldots, x_d)$ 11: 通过网络中的 logits 预测终端令牌后验:
$$ \ell_ {j} (\cdot) \leftarrow f _ {\theta} (x, t) _ {j} \quad \Rightarrow \quad p _ {1 | t} ^ {\theta} (v \mid x) _ {j} = \operatorname{Softmax} \left(\ell_ {j}\right) (v) $$
12:离散流匹配损失(z 的 token-wise NLL):
$$ \mathcal {L} _ {\mathrm{DFM}} (\theta) \leftarrow \sum_ {j = 1} ^ {d} \left[ - \log p _ {1 | t} ^ {\theta} (z _ {j} \mid x) _ {j} \right] $$
13:更新参数:$\theta \leftarrow \mathrm{OPT.STEP}\big(\nabla_{\theta}\mathcal{L}_{\mathrm{DFM}}(\theta)\big)$
14:结束
现在,这完成了训练和采样 CTMC 模型的完整流程,使我们能够生成文本等离散序列。当前最先进的离散扩散模型 $[4]$ 使用本工作中描述的方法,并使用在网络规模数据上训练的神经网络(通常是 Transformer)。
备注40(发电机匹配)
您可能想知道为什么流动/扩散模型的原理可以如此无缝地转换为离散状态空间。事实证明,流匹配的原理并不是流量甚至 CTMC 所独有的。相反,这些是使用马尔可夫过程构建生成式模型的一般学习原则。这一想法催生了生成器匹配框架 $[19]$ ,该框架将离散和连续流和扩散模型扩展并统一为一个。生成器是向量场 $u_{t}$ 和速率矩阵 $Q_{t}$ 的泛化。可以为任何数据模态和状态空间构建马尔可夫过程和生成器。例如,您可以为平滑流形 $[8, 10]$ (例如几何数据)、混合状态空间(例如联合文本和图像生成) $[6]$ 以及其他马尔可夫过程(例如跳跃过程 $[19, 7]$ )构建模型。
8 参考文献
[1] Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. “Stochastic interpolants: A unifying framework for flows and diffusions”. In: arXiv preprint arXiv:2303.08797 (2023).
[2] Brian DO Anderson. “Reverse-time diffusion equation models”. In: Stochastic Processes and their Applications 12.3 (1982), pp. 313–326.
[3] Yogesh Balaji et al. eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers. 2023. arXiv: 2211.01324 [cs.CV]. URL: https://arxiv.org/abs/2211.01324.
[4] Tiwei Bie et al. “Llada2. 0: Scaling up diffusion language models to 100b”. In: arXiv preprint arXiv:2512.15745 (2025).
[5] Andrew Campbell et al. “A continuous time framework for discrete denoising models”. In: Advances in Neural Information Processing Systems 35 (2022), pp. 28266–28279.
[6] Andrew Campbell et al. “Generative flows on discrete state-spaces: Enabling multimodal flows with applications to protein co-design”. In: arXiv preprint arXiv:2402.04997 (2024).
[7] Andrew Campbell et al. “Trans-dimensional generative modeling via jump diffusion models”. In: Advances in Neural Information Processing Systems 36 (2023), pp. 42217–42257.
[8] Ricky TQ Chen and Yaron Lipman. “Flow matching on general geometries”. In: arXiv preprint arXiv:2302.03660 (2023).
[9] Earl A Coddington, Norman Levinson, and T Teichmann. Theory of ordinary differential equations. 1956.
[10] Valentin De Bortoli et al. “Riemannian score-based generative modelling”. In: Advances in neural information processing systems 35 (2022), pp. 2406–2422.
[11] Prafulla Dhariwal and Alex Nichol. Diffusion Models Beat GANs on Image Synthesis. 2021. arXiv: 2105.05233 [cs.LG]. URL: https://arxiv.org/abs/2105.05233.
[12] Alexey Dosovitskiy. “An image is worth 16x16 words: Transformers for image recognition at scale”. In: arXiv preprint arXiv:2010.11929 (2020).
[13] Alexey Dosovitskiy et al. An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. 2021. arXiv: 2010.11929 [cs.CV]. URL: https://arxiv.org/abs/2010.11929.
[14] Patrick Esser et al. Scaling Rectified Flow Transformers for High-Resolution Image Synthesis. 2024. arXiv:2403.03206 [cs.CV]. URL: https://arxiv.org/abs/2403.03206.
[15] Lawrence C Evans. Partial differential equations. Vol. 19. American Mathematical Society, 2022.
[16] Itai Gat et al. “Discrete flow matching”. In: Advances in Neural Information Processing Systems 37 (2024), pp. 133345–133385.
[17] Jonathan Ho, Ajay Jain, and Pieter Abbeel. “Denoising diffusion probabilistic models”. In: Advances in neural information processing systems 33 (2020), pp. 6840–6851.
[18] Jonathan Ho and Tim Salimans. Classifier-Free Diffusion Guidance. 2022. arXiv: 2207.12598 [cs.LG]. URL: https://arxiv.org/abs/2207.12598.
[19] Peter Holderrieth et al. “Generator matching: Generative modeling with arbitrary markov processes”. In: arXiv preprint arXiv:2410.20587 (2024).
[20] Peter Holderrieth et al. “GLASS Flows: Transition Sampling for Alignment of Flow and Diffusion Models”. In: arXiv preprint arXiv:2509.25170 (2025).
[21] Arieh Iserles. A first course in the numerical analysis of differential equations. Cambridge university press, 2009.
[22] Alexia Jolicoeur-Martineau et al. “Adversarial score matching and improved sampling for image generation”. In: arXiv preprint arXiv:2009.05475 (2020).
[23] Tero Karras et al. “Elucidating the design space of diffusion-based generative models”. In: Advances in Neural Information Processing Systems 35 (2022), pp. 26565–26577.
[24] Samuel Lavoie et al. Modeling Caption Diversity in Contrastive Vision-Language Pretraining. 2024. arXiv:2405.00740 [cs.CV]. URL: https://arxiv.org/abs/2405.00740.
[25] Yaron Lipman et al. “Flow matching for generative modeling”. In: arXiv preprint arXiv:2210.02747 (2022).
[26] Yaron Lipman et al. “Flow Matching Guide and Code”. In: arXiv preprint arXiv:2412.06264 (2024).
[27] Xingchao Liu, Chengyue Gong, and Qiang Liu. “Flow straight and fast: Learning to generate and transfer data with rectified flow”. In: arXiv preprint arXiv:2209.03003 (2022).
[28] Nanye Ma et al. “Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers”. In: arXiv preprint arXiv:2401.08740 (2024).
[29] Xuerong Mao. Stochastic differential equations and applications. Elsevier, 2007.
[30] William Peebles and Saining Xie. Scalable Diffusion Models with Transformers. 2023. arXiv: 2212.09748 [cs.CV]. URL: https://arxiv.org/abs/2212.09748.
[31] Ethan Perez et al. “Film: Visual reasoning with a general conditioning layer”. In: Proceedings of the AAAI conference on artificial intelligence. Vol. 32. 1. 2018.
[32] Lawrence Perko. Differential equations and dynamical systems. Vol. 7. Springer Science & Business Media, 2013.
[33] Adam Polyak et al. Movie Gen: A Cast of Media Foundation Models. 2024. arXiv: 2410.13720 [cs.CV]. URL: https://arxiv.org/abs/2410.13720.
[34] Alec Radford et al. Learning Transferable Visual Models From Natural Language Supervision. 2021. arXiv:2103.00020 [cs.CV]. URL: https://arxiv.org/abs/2103.00020.
[35] Colin Raffel et al. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. 2023. arXiv: 1910.10683 [cs.LG]. URL: https://arxiv.org/abs/1910.10683.
[36] Robin Rombach et al. High-Resolution Image Synthesis with Latent Diffusion Models. 2022. arXiv: 2112.10752 [cs.CV]. URL: https://arxiv.org/abs/2112.10752.
[37] Robin Rombach et al. “High-resolution image synthesis with latent diffusion models”. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022, pp. 10684–10695.
[38] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. “U-net: Convolutional networks for biomedical image segmentation”. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer. 2015, pp. 234–241.
[39] Chitwan Saharia et al. Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding. 2022. arXiv: 2205.11487 [cs.CV]. URL: https://arxiv.org/abs/2205.11487.
[40] Simo Särkkä and Arno Solin. Applied stochastic differential equations. Vol. 10. Cambridge University Press, 2019.
[41] Jascha Sohl-Dickstein et al. “Deep unsupervised learning using nonequilibrium thermodynamics”. In: International conference on machine learning. PMLR. 2015, pp. 2256–2265.
[42] Yang Song and Stefano Ermon. “Generative modeling by estimating gradients of the data distribution”. In: Advances in neural information processing systems 32 (2019).
[43] Yang Song et al. Score-Based Generative Modeling through Stochastic Differential Equations. 2021. arXiv:2011.13456 [cs.LG]. URL: https://arxiv.org/abs/2011.13456.
[44] Yang Song et al. “Score-Based Generative Modeling through Stochastic Differential Equations”. In: International Conference on Learning Representations (ICLR). 2021.
[45] Yang Song et al. “Score-based generative modeling through stochastic differential equations”. In: arXiv preprint arXiv:2011.13456 (2020).
[46] Matthew Tancik et al. Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains. 2020. arXiv: 2006.10739 [cs.CV]. URL: https://arxiv.org/abs/2006.10739.
[47] Yi Tay et al. UL2: Unifying Language Learning Paradigms. 2023. arXiv: 2205.05131 [cs.CL]. URL: https://arxiv.org/abs/2205.05131.
[48] Arash Vahdat, Karsten Kreis, and Jan Kautz. “Score-based generative modeling in latent space”. In: Advances in neural information processing systems 34 (2021), pp. 11287–11302.
[49] Ashish Vaswani et al. Attention Is All You Need. 2023. arXiv: 1706.03762 [cs.CL]. URL: https://arxiv.org/abs/1706.03762.
[50] Linting Xue et al. ByT5: Towards a token-free future with pre-trained byte-to-byte models. 2022. arXiv: 2105.13626 [cs.CL]. URL: https://arxiv.org/abs/2105.13626.
[51] Jingfeng Yao, Bin Yang, and Xinggang Wang. “Reconstruction vs. generation: Taming optimization dilemma in latent diffusion models”. In: Proceedings of the Computer Vision and Pattern Recognition Conference. 2025, pp. 15703–15712.
A 概率论提醒
我们简要概述了概率论的基本概念。本节部分摘自[26]。
A.1 随机向量
考虑 $d$ 维欧几里得空间 $x = (x^1, \ldots, x^d) \in \mathbb{R}^d$ 中的数据,具有标准欧几里得内积 $\langle x, y \rangle = \sum_{i=1}^{d} x^i y^i$ 和范数 $\|x\| = \sqrt{\langle x, x \rangle}$ 。我们将考虑具有连续概率密度函数 (PDF) 的随机变量 (RV) $X \in \mathbb{R}^d$,定义为连续函数 $p_X: \mathbb{R}^d \to \mathbb{R}_{\geq 0}$ 为事件 $A$ 提供概率
$$ \mathbb {P} (X \in A) = \int_ {A} p _ {X} (x) \mathrm{d} x, \tag {96} $$
在哪里 $\int p_X(x)\mathrm{d}x = 1$ 。按照惯例,我们在对整个空间进行积分时省略积分区间 $(\int \equiv \int_{\mathbb{R}^d})$ 。为了保持符号简洁,我们将参考 PDF $p_{X_t}$ 房车的 $X_{t}$ 简单地说 $p_t$ 。我们将使用符号 $X\sim p$ 或者 $X\sim p(X)$ 表明 $X$ 是根据分布 $p$ 。生成式建模中一种常见的 PDF 是 $d$ 维各向同性高斯:
$$ \mathcal {N} (x; \mu , \sigma^ {2} I) = (2 \pi \sigma^ {2}) ^ {- \frac {d}{2}} \exp \left(- \frac {\| x - \mu \| _ {2} ^ {2}}{2 \sigma^ {2}}\right), \tag {97} $$
其中 $\mu \in \mathbb{R}^d$ 和 $\sigma \in \mathbb{R}_{>0}$ 分别代表分布的平均值和标准差。
RV 的期望是在最小二乘意义上最接近 X 的常数向量:
$$ \mathbb {E} [ X ] = \underset {z \in \mathbb {R} ^ {d}} {\arg \min} \int \| x - z \| ^ {2} p _ {X} (x) \mathrm{d} x = \int x p _ {X} (x) \mathrm{d} x. \tag {98} $$
计算 RV 函数期望的一种有用工具是无意识统计学家定律:
$$ \mathbb {E} \left[ f (X) \right] = \int f (x) p _ {X} (x) \mathrm{d} x. \tag {99} $$
必要时,我们将期望下的随机变量表示为 $\mathbb{E}_{X}f(X)$ 。
A.2 条件密度和期望
给定两个随机变量 $X, Y \in R^{d}$ ,它们的联合 PDF $p_{X,Y}(x, y)$ 有边际
$$ \int p _ {X, Y} (x, y) \mathrm{d} y = p _ {X} (x) \text { and } \int p _ {X, Y} (x, y) \mathrm{d} x = p _ {Y} (y). \tag {100} $$
请参见图 21,了解两个 RV 的联合 PDF 的说明。 $\mathbb{R}$ ( $d = 1$ )。条件 PDF $p_{X|Y}$ 描述随机变量的 PDF $X$ 当以事件为条件时 $Y = y$ 与密度 $p_Y(y) > 0$ :
$$ p _ {X \mid Y} (x \mid y) := \frac {p _ {X , Y} (x , y)}{p _ {Y} (y)}, \tag {101} $$
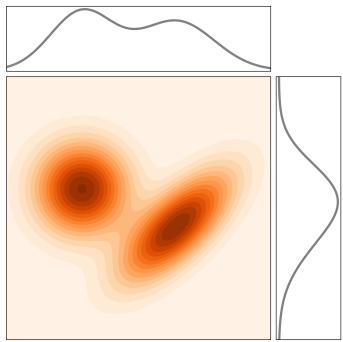
对于条件 PDF $p_{Y|X}$ 也是如此。贝叶斯规则将条件 PDF $p_{Y|X}$ 和 $p_{X|Y}$ 表示为
$$ p _ {Y \mid X} (y \mid x) = \frac {p _ {X \mid Y} (x \mid y) p _ {Y} (y)}{p _ {X} (x)}, \tag {102} $$
对于 $p_{X}(x) > 0$ 。
条件期望 $\mathbb{E}[X|Y]$ 是最小二乘意义上的 $g_{\star}(Y)$ 到 $X$ 的最佳逼近函数:
$$ \begin{array}{l} g _ {\star} := \underset {g: \mathbb {R} ^ {d} \to \mathbb {R} ^ {d}} {\arg \min} \mathbb {E} \left[ \| X - g (Y) \| ^ {2} \right] = \underset {g: \mathbb {R} ^ {d} \to \mathbb {R} ^ {d}} {\arg \min} \int \| x - g (y) \| ^ {2} p _ {X, Y} (x, y) \mathrm{d} x \mathrm{d} y \\ = \underset {g: \mathbb {R} ^ {d} \rightarrow \mathbb {R} ^ {d}} {\arg \min} \int \left[ \int \| x - g (y) \| ^ {2} p _ {X | Y} (x | y) \mathrm{d} x \right] p _ {Y} (y) \mathrm{d} y. \tag {103} \\ \end{array} $$
对于 $y \in \mathbb{R}^d$ 使得 $p_Y(y) > 0$ 的条件期望函数为
$$ \mathbb {E} \left[ X | Y = y \right] := g _ {\star} (y) = \int x p _ {X | Y} (x | y) \mathrm{d} x, \tag {104} $$
其中第二个等式是在 Y = y 时取方程 (103) 中内括号的最小值得出的,与方程 (98) 类似。将 $g_{\star}$ 与随机变量 Y 组合,我们得到
$$ \mathbb {E} [ X | Y ] := g _ {\star} (Y), \tag {105} $$
这是 $R^{d}$ 中的随机变量。令人困惑的是, $E[X|Y=y]$ 和 $E[X|Y]$ 通常都称为条件期望,但它们是不同的对象。特别是, $E[X|Y=y]$ 是一个函数 $R^{d} \to R^{d}$ ,而 $E[X|Y]$ 是一个随机变量,假设 $R^{d}$ 中的值。为了消除这两个术语的歧义,我们的讨论将使用此处介绍的符号。
tower 属性是一个有用的属性,有助于简化涉及两个 RV X 和 Y 的条件期望的推导:
$$ \mathbb {E} \left[ \mathbb {E} [ X | Y ] \right] = \mathbb {E} [ X ] \tag {106} $$
因为 $E[X|Y]$ 是一个 RV,它本身是 RV Y 的函数,所以外部期望计算 $E[X|Y]$ 的期望。塔的属性可以通过使用上面的一些定义来验证:
$$ \begin{array}{l} \mathbb {E} \left[ \mathbb {E} [ X | Y ] \right] = \int \left(\int x p _ {X | Y} (x | y) \mathrm{d} x\right) p _ {Y} (y) \mathrm{d} y \\ \stackrel {(1 0 1)} {=} \int \int x p _ {X, Y} (x, y) \mathrm{d} x \mathrm{d} y \\ \stackrel {(1 0 0)} {=} \int x p _ {X} (x) \mathrm{d} x = \mathbb {E} [ X ]. \\ \end{array} $$
最后,考虑一个涉及两个 RV $f(X,Y)$ 和 $Y$ 的有用属性,其中 $X$ 和 $Y$ 是两个任意 RV。然后,通过使用无意识统计学家定律和(104),我们获得恒等式
$$ \mathbb {E} \left[ f (X, Y) | Y = y \right] = \int f (x, y) p _ {X | Y} (x | y) \mathrm{d} x. \tag {107} $$
B A 福克-普朗克方程的证明
在本节中,我们给出 Fokker-Planck 方程的独立证明,其中包括作为特殊情况的连续性方程(定理 11)。我们强调,本节对于理解本文档的其余部分来说不是必需的,并且在数学上更先进。如果您想了解福克-普朗克方程的来源,那么本节适合您。
定理 41(福克-普朗克方程)
令 $p_t$ 为 $p_0 = p_{\text{init}}$ 的概率路径,并考虑 SDE
$$ X _ {0} \sim p _ {\mathrm{init}}, \quad \mathrm{d} X _ {t} = u _ {t} (X _ {t}) \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t}. $$
然后 $X_{t}$ 有分布 $p_{t}$ 为所有人 $0 \leq t \leq 1$ 当且仅当福克-普朗克方程成立:
$$ \partial_ {t} p _ {t} (x) = - \mathrm{div} (p _ {t} u _ {t}) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \quad \text { for all } x \in \mathbb {R} ^ {d}, 0 \leq t \leq 1, \tag {108} $$
我们首先证明福克-普朗克方程是一个必要条件,即如果 $X_{t} \sim p_{t}$ ,则满足福克-普朗克方程。证明的技巧是使用测试函数 f,即无限可微(“平滑”)并且仅在有界域内非零的函数 $f : R^{d} \to R$ (紧支持)。我们使用这样一个事实:对于任意可积函数 $g_{1}, g_{2} : R^{d} \to R$ ,它认为
$$ g _ {1} (x) = g _ {2} (x) \text { for all } x \in \mathbb {R} ^ {d} \quad \Leftrightarrow \quad \int f (x) g _ {1} (x) \mathrm{d} x = \int f (x) g _ {2} (x) \mathrm{d} x \text { for all test functions } f \tag {109} $$
换句话说,我们可以将逐点等式表示为取积分的等式。测试函数的有用之处在于它们是平滑的,即我们可以采用梯度和高阶导数。特别是,我们可以对任意测试函数 $f_{1}, f_{2}$ 使用分部积分:
$$ \int f _ {1} (x) \frac {\partial}{\partial x _ {i}} f _ {2} (x) \mathrm{d} x = - \int f _ {2} (x) \frac {\partial}{\partial x _ {i}} f _ {1} (x) \mathrm{d} x \tag {110} $$
条件是 $f_{1}, f_{2}$ 及其乘积 $f_{1} \cdot f_{2}$ 可积。通过将其与散度和拉普拉斯算子的定义一起使用(参见方程(22)),我们得到恒等式:
$$ \int \nabla f _ {1} ^ {T} (x) f _ {2} (x) \mathrm{d} x = - \int f _ {1} (x) \operatorname{div} \left(f _ {2}\right) (x) \mathrm{d} x \quad \left(f _ {1}: \mathbb {R} ^ {d} \rightarrow \mathbb {R}, f _ {2}: \mathbb {R} ^ {d} \rightarrow \mathbb {R} ^ {d}\right) \tag {111} $$
$$ \int f _ {1} (x) \Delta f _ {2} (x) \mathrm{d} x = \int f _ {2} (x) \Delta f _ {1} (x) \mathrm{d} x \quad (f _ {1}: \mathbb {R} ^ {d} \rightarrow \mathbb {R}, f _ {2}: \mathbb {R} ^ {d} \rightarrow \mathbb {R}) \tag {112} $$
现在我们继续证明。我们使用 SDE 轨迹的随机更新,如方程 (6) 所示:
$$ X _ {t + h} = X _ {t} + h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t}) + h R _ {t} (h) \tag {113} $$
$$ \approx X _ {t} + h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t}) \tag {114} $$
现在为了可读性,我们只是忽略错误术语 $R_{t}(h)$ ,因为无论如何我们都会采用 $h \rightarrow 0$ 。那么我们就可以
进行如下计算:
$$ \begin{array}{l} f (X _ {t + h}) - f (X _ {t}) \stackrel {(1 1 4)} {=} f (X _ {t} + h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t})) - f (X _ {t}) \\ \stackrel {(i)} {=} \nabla f (X _ {t}) ^ {T} \left(h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t}))\right) \\ + \frac {1}{2} \left(h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t}))\right) ^ {T} \nabla^ {2} f (X _ {t}) \left(h u _ {t} (X _ {t}) + \sigma_ {t} (W _ {t + h} - W _ {t}))\right) \\ \stackrel {(i i)} {=} h \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \sigma_ {t} \nabla f (X _ {t}) ^ {T} (W _ {t + h} - W _ {t}) \\ + \frac {1}{2} h ^ {2} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) u _ {t} (X _ {t}) + h \sigma_ {t} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) (W _ {t + h} - W _ {t}) + \\ + \frac {1}{2} \sigma_ {t} ^ {2} (W _ {t + h} - W _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) (W _ {t + h} - W _ {t}) \\ \end{array} $$
其中 (i) 我们使用了二阶泰勒近似 $f$ 大约 $X_{t}$ 在 (ii) 中我们使用了 Hessian 矩阵 $\nabla^2 f$ 是一个对称矩阵。注意 $\mathbb{E}[W_{t + h} - W_t|X_t] = 0$ 和 $W_{t + h} - W_t|X_t\sim \mathcal{N}(0,hI_d)$ 。所以
$$ \begin{array}{l} \mathbb {E} [ f (X _ {t + h}) - f (X _ {t}) | X _ {t} ] \\ = h \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \frac {1}{2} h ^ {2} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) u _ {t} (X _ {t}) + \frac {h}{2} \sigma_ {t} ^ {2} \mathbb {E} _ {\epsilon_ {t} \sim \mathcal {N} (0, I _ {d})} [ \epsilon_ {t} ^ {T} \nabla^ {2} f (X _ {t}) \epsilon_ {t} ] \\ \stackrel {(i)} {=} h \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \frac {1}{2} h ^ {2} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) u _ {t} (X _ {t}) + \frac {h}{2} \sigma_ {t} ^ {2} \mathrm{trace} (\nabla^ {2} f (X _ {t})) \\ \stackrel {(i i)} {=} h \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \frac {1}{2} h ^ {2} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) u _ {t} (X _ {t}) + \frac {h}{2} \sigma_ {t} ^ {2} \Delta f (X _ {t}) \\ \end{array} $$
其中,在 (i) 中我们使用了 $\mathbb{E}_{\epsilon_{t}\sim\mathcal{N}(0,I_{d})}[\epsilon_{t}^{T}A\epsilon_{t}]=\operatorname{trace}(A)$ 的事实,在 (ii) 中我们使用了拉普拉斯矩阵和 Hessian 矩阵的定义。有了这个,我们就明白了
$$ \begin{array}{l} \partial_ {t} \mathbb {E} [ f (X _ {t}) ] \\ = \lim _ {h \rightarrow 0} \frac {1}{h} \mathbb {E} [ f (X _ {t + h}) - f (X _ {t}) ] \\ = \lim _ {h \to 0} \frac {1}{h} \mathbb {E} [ \mathbb {E} [ f (X _ {t + h}) - f (X _ {t}) | X _ {t} ] ] \\ = \mathbb {E} [ \lim _ {h \to 0} \frac {1}{h} \left(h \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \frac {1}{2} h ^ {2} u _ {t} (X _ {t}) ^ {T} \nabla^ {2} f (X _ {t}) u _ {t} (X _ {t}) + \frac {h}{2} \sigma_ {t} ^ {2} \Delta f (X _ {t})\right) ] \\ = \mathbb {E} [ \nabla f (X _ {t}) ^ {T} u _ {t} (X _ {t}) + \frac {1}{2} \sigma_ {t} ^ {2} \Delta f (X _ {t}) ] \\ \stackrel {(i)} {=} \int \nabla f (x) ^ {T} u _ {t} (x) p _ {t} (x) \mathrm{d} x + \int \frac {1}{2} \sigma_ {t} ^ {2} \Delta f (x) p _ {t} (x) \mathrm{d} x \\ \stackrel {(i i)} {=} - \int f (x) \mathrm{div} (u _ {t} p _ {t}) (x) \mathrm{d} x + \int \frac {1}{2} \sigma_ {t} ^ {2} f (x) \Delta p _ {t} (x) \mathrm{d} x \\ = \int f (x) \left(- \operatorname{div} \left(u _ {t} p _ {t}\right) (x) + \frac {1}{2} \sigma_ {t} ^ {2} \Delta p _ {t} (x)\right) \mathrm{d} x \\ \end{array} $$
其中,在 (i) 中,我们使用 $p_{t}$ 作为 $X_{t}$ 的分布的假设,在 (ii) 中,我们使用方程 (111) 和方程 (112)。请注意,要使用它,我们需要产品 $p_{t}(x)u_{t}(x)$ 的可积性,即
$$ \int p _ {t} (x) \| u _ {t} (x) \| \mathrm{d} x < \infty $$
请注意,这种条件在机器学习中几乎总是成立(由于数值精度限制,数据和函数有界)。因此,认为
$$ \partial_ {t} \mathbb {E} [ f (X _ {t}) ] = \int f (x) \left(- \operatorname{div} (p _ {t} u _ {t}) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x)\right) \mathrm{d} x \quad (\text { for all } f \text { and } 0 \leq t \leq 1) \tag {115} $$
$$ \stackrel {(i)} {\Leftrightarrow} \quad \partial_ {t} \int f (x) p _ {t} (x) \mathrm{d} x = \int f (x) \left(- \operatorname{div} \left(p _ {t} u _ {t}\right) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x)\right) \mathrm{d} x \quad (\text {for all} f \text {and} 0 \leq t \leq 1) \tag {116} $$
$$ \stackrel {(i i)} {\Leftrightarrow} \quad \int f (x) \partial_ {t} p _ {t} (x) \mathrm{d} x = \int f (x) \left(- \operatorname{div} (p _ {t} u _ {t}) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x)\right) \mathrm{d} x \quad (\text {for all} f \text {and} 0 \leq t \leq 1) \tag {117} $$
$$ \stackrel {(i i i)} {\Leftrightarrow} \quad \partial_ {t} p _ {t} (x) = - \operatorname{div} \left(p _ {t} u _ {t}\right) (x) + \frac {\sigma_ {t} ^ {2}}{2} \Delta p _ {t} (x) \quad (\text { for all } x \in \mathbb {R} ^ {d}, 0 \leq t \leq 1) \tag {118} $$
其中,在 (i) 中我们使用了 $X_{t} \sim p_{t}$ 假设,在 (ii) 中我们用积分交换了导数,(iii) 我们使用了方程 (109)。这就完成了福克-普朗克方程是必要条件的证明。
最后,我们解释为什么它也是一个充分条件。福克-普朗克方程是偏微分方程 (PDE)。更具体地,它是所谓的抛物型偏微分方程。与定理 3 类似,在给定固定初始条件的情况下,此类微分方程具有唯一解(参见 [15,第 7 章])。现在,如果方程(108)成立 $p_t$ ,我们刚刚在上面表明它也必须适用于真实分布 $q_t$ 的 $X_t$ (IE。 $X_t \sim q_t$ ) - 换句话说,两者 $p_t$ 和 $q_t$ 是抛物线偏微分方程的解。此外,我们知道初始条件是相同的,即 $p_0 = q_0 = p_{\mathrm{init}}$ 通过构建插值概率路径。因此,根据微分方程解的唯一性,我们知道 $p_t = q_t$ 为所有人 $0 \leq t \leq 1$ - 这意味着 $X_t \sim q_t = p_t$ 这就是我们想要展示的。
C 连续时间马尔可夫链的存在唯一性
我们在本节中证明定理 33。
证明。唯一性:我们需要证明只能有一个满足方程(87)的转换内核$p_{t'|t}(X_{t'} = y|X_t = x)$。第一步,我们意识到方程(87)意味着
$$ \frac {\mathrm{d}}{\mathrm{d} t ^ {\prime}} p _ {t ^ {\prime} \mid t} (X _ {t ^ {\prime}} = y | X _ {t} = x) \tag {119} $$
$$ = \frac {\mathrm{d}}{\mathrm{d} h} p _ {t ^ {\prime} + h \mid t} (X _ {t ^ {\prime} + h} = y \mid X _ {t} = x) _ {| h = 0} \tag {120} $$
$$ = \frac {\mathrm{d}}{\mathrm{d} h} \left[ \sum_ {z \in S} p _ {t ^ {\prime} + h \mid t ^ {\prime}} (X _ {t ^ {\prime} + h} = y | X _ {t ^ {\prime}} = z) p _ {t ^ {\prime} \mid t} (X _ {t ^ {\prime}} = z | X _ {t} = x) \right] _ {| h = 0} \tag {121} $$
$$ = \sum_ {z \in S} Q _ {t ^ {\prime}} (y | z) p _ {t ^ {\prime} | t} \left(X _ {t ^ {\prime}} = z \mid X _ {t} = x\right) \tag {122} $$
对于固定的 x, t,可以将 $t' \mapsto p_{t'|t}(X_{t'} = y|X_t = x)$ 视为向量值函数,上面是该函数的线性常微分方程(Kolmgorov 前向方程,事实上,参见命题 2),初始条件已知,即 $p_{t|t}(X_t = y|X_t = x) = \delta_y(x)$ 。众所周知,每个线性 ODE 都有唯一的解(参见定理 3),因此 $p_{t'|t}(X_{t'} = y|X_t = x)$ 也必须是唯一的。
存在性:相反,任何线性 ODE 都有一个解,即我们知道对于每个 $x, t$ 都有一个 $p_{t'|t}(X_{t'} = y|X_t = x)$ 使得
$$ p _ {t \mid t} (X _ {t} = y \mid X _ {t} = x) = \delta_ {y} (x) \tag {123} $$
$$ \frac {\mathrm{d}}{\mathrm{d} t ^ {\prime}} p _ {t ^ {\prime} \mid t} (X _ {t ^ {\prime}} = y | X _ {t} = x) = \sum_ {z \in S} Q _ {t ^ {\prime}} (y | z) p _ {t ^ {\prime} \mid t} (X _ {t ^ {\prime}} = z | X _ {t} = x) \tag {124} $$
对于 $t' = t$ ,这尤其意味着方程(87)。在这种情况下,仍然需要证明 $p_{t'|t}(X_{t'} = y|X_t = x)$ 是一个有效的转换内核,即必须满足以下 3 个属性:
$$ \sum_ {y \in S} p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = y | X _ {t} = x) = 1 \tag {125} $$
$$ p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = y | X _ {t} = x) \geq 0 \tag {126} $$
$$ \sum_ {z \in S} p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = y | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) = p _ {t _ {2} | t _ {0}} (y | x) \tag {127} $$
对于第一个属性,可以观察到它对于 $t' = t$ 通过方程 (123) 成立并且
$$ \frac {\mathrm{d}}{\mathrm{d} t ^ {\prime}} \sum_ {y \in S} p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = y | X _ {t} = x) \tag {128} $$
$$ = \sum_ {y \in S} \frac {\mathrm{d}}{\mathrm{d} t ^ {\prime}} p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = y | X _ {t} = x) \tag {129} $$
$$ = \sum_ {z \in S} \left[ \sum_ {y \in S} Q _ {t ^ {\prime}} (y | z) \right] p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = z | X _ {t} = x) \tag {130} $$
$$ = 0 \tag {131} $$
其中我们使用了速率矩阵的列总和为 0 的事实。为了显示第二个属性,请注意它在时间 $t' = t$ 成立。此外,每当 $p_{t'|t}(X_{t'} = y|X_t = x) = 0$ 时,它必须保持
$$ \frac {\mathrm{d}}{\mathrm{d} t ^ {\prime}} p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = y | X _ {t} = x) = \sum_ {z \neq y} \underbrace {Q _ {t ^ {\prime}} (y | z)} _ {\geq 0} p _ {t ^ {\prime} | t} (X _ {t ^ {\prime}} = z | X _ {t} = x) $$
$$ \geq 0 $$
因此,每当 $p_{t'|t}(X_{t'} = y|X_t = x) = 0$ 时,它只能增加。因此,$p_{t'|t}(X_{t'} = y|X_t = x)$ 永远不会为负数。
要显示第三个属性,请将 $q_{t_2|t_0}(y|x)$ 定义为
$$ q _ {t _ {2} | t _ {0}} (y | x) = \sum_ {z \in S} p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = y | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) $$
然后我们知道
$$ q _ {t _ {2} = t _ {1} | t _ {0}} (y | x) = \sum_ {z \in S} \delta_ {y} (z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) = p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = y | X _ {t _ {0}} = x) $$
和
$$ \begin{array}{l} \frac {\mathrm{d}}{\mathrm{d} t _ {2}} q _ {t _ {2} | t _ {0}} (y | x) = \sum_ {z \in S} \frac {\mathrm{d}}{\mathrm{d} t _ {2}} p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = y | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) \\ = \sum_ {z \in S} \sum_ {\tilde {z} \in S} Q _ {t _ {2}} (y | \tilde {z}) p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = \tilde {z} | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) \\ = \sum_ {\tilde {z} \in S} Q _ {t _ {2}} (y | \tilde {z}) \left[ \sum_ {z \in S} p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = \tilde {z} | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) \right] \\ = \sum_ {\tilde {z} \in S} Q _ {t _ {2}} (y | \tilde {z}) q _ {t _ {2} | t _ {0}} (\tilde {z} | x) \\ \end{array} $$
这表明 $p_{t_2|t_0}(z|x)$ 和 $q_{t_2|t_0}(z|x)$ 满足相同的 ODE。因此,它必须保持
$$ \sum_ {z \in S} p _ {t _ {2} | t _ {1}} (X _ {t _ {2}} = y | X _ {t _ {1}} = z) p _ {t _ {1} | t _ {0}} (X _ {t _ {1}} = z | X _ {t _ {0}} = x) = q _ {t _ {2} | t _ {0}} (y | x) = p _ {t _ {2} | t _ {0}} (y | x) $$
这显示了第三个属性。所以$p_{t'|t}(y|x)$确实是满足式(87)的转换核。至此证明完毕。
D 关于 VAE 的其他观点
在本节中,我们将扩展正文中提出的 VAE 的处理,并根据方程(83)提供总 VAE 损失的变分推导。第一步,请注意编码器和解码器都会在 x 和潜在 z 上产生联合分布,即,
$$ q _ {\phi} (x, z) = p _ {\mathrm{data}} (x) q _ {\phi} (\cdot | x) \quad \text {(encoder joint)} $$
$$ p _ {\theta} (x, z) = p _ {\theta} (x | z) p _ {\text { prior }} (z) \quad (\text { decoder joint }) $$
因此,我们可以将训练 VAE 概念化为学习 $\phi$ 和 $\theta$ ,以便编码器和解码器联合分布相当相似。我们可以通过联合潜在分布和数据分布的 KL 散度来做到这一点:
$$ \begin{array}{l} D _ {\mathrm{KL}} (q _ {\phi} (x, z) \parallel p _ {\theta} (x, z)) = D _ {\mathrm{KL}} (p _ {\mathrm{data}} (x) q _ {\phi} (z \mid x) \parallel p _ {\theta} (x \mid z) p _ {\mathrm{prior}} (z)) \\ = \mathbb {E} _ {\blacksquare} \left[ \log \left(\frac {p _ {\text {data}} (x) q _ {\phi} (z \mid x)}{p _ {\theta} (x \mid z) p _ {\text {prior}} (z)}\right) \right] \tag {132} \\ = \mathbb {E} _ {\blacksquare} \left[ \log p _ {\mathrm{data}} (x) \right] + \mathbb {E} _ {\blacksquare} \left[ \log \left(\frac {q _ {\phi} (z \mid x)}{p _ {\mathrm{prior}} (z)}\right) \right] - \mathbb {E} _ {\blacksquare} \left[ \log p _ {\theta} (x \mid z) \right] \\ \blacksquare = x \sim p _ {\mathrm{data}} (x) z \sim q _ {\phi} (z | x). \\ \end{array} $$
现在让我们依次检查剩下的三个术语。首先,我们发现
$$ \mathbb {E} _ {\blacksquare} \left[ \log p _ {\text { data }} (x) \right] = \mathbb {E} _ {x \sim p _ {\text { data }} (x)} \left[ \log p _ {\text { data }} (x) \right] = C, \tag {133} $$
对于一些独立于 $\phi$ 和 $\theta$ 的常数 C 。接下来,我们发现
$$ \mathbb {E} _ {\blacksquare} \left[ \log \left(\frac {q _ {\phi} (z \mid x)}{p _ {\text { prior }} (z)}\right) \right] = \mathbb {E} _ {x \sim p _ {\text { data }} (x)} \left[ D _ {\mathrm{KL}} (q _ {\phi} (z \mid x) \parallel p _ {\text { prior }} (z)) \right] \tag {134} $$
鼓励 $q_{\phi}(z \mid x)$ 类似于之前的 $p_{\mathrm{prior}}(z)$ 。最后,我们发现
$$ - \mathbb {E} _ {x \sim p _ {\text { data }} (x) z \sim q _ {\phi} (z | x)} [ \log p _ {\theta} (x \mid z) ] \tag {135} $$
对应于平均负对数似然,因此可以最小化重建损失。忽略常数项,我们结合先验惩罚项和重构项,得到 VAE 损失实际上只是联合数据和latent 空间中的 KL 散度:
$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = \underbrace {\mathbb {E} _ {x \sim p _ {\text { data }} (x)} \left[ D _ {\mathrm{KL}} (q _ {\phi} (z \mid x) \| p _ {\text { prior }} (z)) \right]} _ {\text { prior enforcement loss }} - \underbrace {\mathbb {E} _ {x \sim p _ {\text { data }} (x) z \sim q _ {\phi} (z | x)} [ \log p _ {\theta} (x \mid z) ]} _ {\text { reconstruction loss }} \tag {136} $$
$$ = D _ {\mathrm{KL}} \left(q _ {\phi} (x, z) \| p _ {\theta} (x, z)\right) + \text { const } \tag {137} $$
因此,我们可以将 VAE 解释为潜在图像和图像联合空间中的 KL 散度。
VAE 作为生成式模型。我们现在解释如何将 VAE 解释为生成式模型。我们可以通过设置 $z \sim p_{\text{prior}} = \mathcal{N}(0, I_k)$ 并从解码器采样 $x \sim p_\theta(\cdot | z)$ 来生成样本。由此产生的
我们得到的分布由下式给出:
$$ p _ {\theta} (x) = \int_ {z} p _ {\theta} (x | z) p _ {\text { prior }} (z) \mathrm{d} z $$
我们现在想要证明 VAE 学会从 $p_{\theta}$ 进行近似采样。为了证明这一点,我们需要以下结果:
命题3(链式法则)
令 $q(x,z), p(x,z)$ 为两个变量 $x \in \mathbb{R}^{l_1}, z \in \mathbb{R}^{l_2}$ 的分布。那么,它认为:
$$ D _ {\mathrm{KL}} (q (z, x) \parallel p (z, x)) = D _ {\mathrm{KL}} (q (x) \parallel p (x)) + \mathbb {E} _ {x \sim q} \left[ D _ {\mathrm{KL}} (q (z | x) \parallel p (z | x)) \right]. $$
特别是,由于等式(76),第二个被加数为非负数,因此我们得到数据处理不等式
$$ D _ {\mathrm{KL}} (q (x) \parallel p (x)) \leq D _ {\mathrm{KL}} (q (z, x) \parallel p (z, x)). \tag {138} $$
证明。
$$ \begin{array}{l} D _ {\mathrm{KL}} (q (z, x) \parallel p (z, x)) = \mathbb {E} _ {q} \left[ \log \frac {q (z , x)}{p (z , x)} \right] \\ = \mathbb {E} _ {(x, z) \sim q} \left[ \log \frac {q (z | x)}{p (z | x)} \frac {q (x)}{p (x)} \right] \\ = \mathbb {E} _ {(x, z) \sim q} \left[ \log {\frac {q (z | x)}{p (z | x)}} \right] + \mathbb {E} _ {x \sim q} \left[ \log {\frac {q (x)}{p (x)}} \right] \\ = D _ {\mathrm{KL}} (q (x) \parallel p (x)) + \mathbb {E} _ {x \sim q} \left[ D _ {\mathrm{KL}} (q (z | x) \parallel p (z | x)) \right] \\ \end{array} $$
其中我们反复应用了 KL 散度的定义。

$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = D _ {\mathrm{KL}} (q _ {\phi} (x, z) \parallel p _ {\theta} (x, z)) + \text { const } \geq D _ {\mathrm{KL}} (p _ {\mathrm{data}} (x) \parallel p _ {\theta} (x)) + \text { const } \tag {139} $$
我们使用了 $q_{\phi}(x,z)$ 的 x 边距是 $p_{data}$ 的事实。换句话说,VAE 损失最小化了数据分布 $p_{data}$ 和 VAE 生成的分布之间 KL 散度的上限。因此,我们可以将 VAE 本身视为生成式模型。同理,我们可以证明
$$ \mathcal {L} _ {\mathrm{VAE}} (\phi , \theta) = D _ {\mathrm{KL}} (q _ {\phi} (x, z) \parallel p _ {\theta} (x, z)) + \mathrm{const} \geq D _ {\mathrm{KL}} (q _ {\phi} (z) \parallel p _ {\mathrm{prior}} (z)) + \mathrm{const} \tag {140} $$
换句话说,VAE 目标最小化潜在分布和先验分布之间 KL 散度的上限。
为什么不停留在 VAE 上呢?根据上面的讨论,VAE 本身可以实现为生成式模型,编码器的存在只是为了促进互补解码器的训练,该解码器将高斯分布转换为所需的数据分布。然后可以通过采样 $z \sim p_{prior}$ 然后采样 $x \sim p_{\theta}(x|z)$ 来获得样本。那么,为什么我们坚持在学习到的latent 空间中训练一个单独的生成式模型呢?答案与方程(139)和方程(140)左右两边之间所谓的摊销差距有关,它恰好对应于信息处理不等式中的差距。当且仅当 $q_{\phi}(z|x) = p_{\theta}(z|x)$ 时,此间隙为零,在这种情况下,编码器代表真实的后验。因此,例如,虽然 $D_{\mathrm{KL}}(q_{\phi}(x,z) \parallel p_{\theta}(x,z))$ 被最小化意味着 $D_{\mathrm{KL}}(q_{\phi}(z) \parallel p_{\mathrm{prior}}(z))$ 被最小化(参见方程(140)),但前者的减少并不一定意味着后者同样减少。因此,在训练结束时,$D_{\mathrm{KL}}(q_{\phi}(x,z) \parallel p_{\theta}(x,z))$ 和摊销缺口同时成立
$$ D _ {\mathrm{KL}} (q _ {\phi} (x, z) \parallel p _ {\theta} (x, z)) - D _ {\mathrm{KL}} (q _ {\phi} (z) \parallel p _ {\text { prior }} (z)) \tag {141} $$
没有完全最小化,因此 $q_{\phi}(z) \neq p_{\mathrm{prior}}(z)$ 。最后,观察到在训练期间,解码器学习从 $q_{\phi}(z)$ 而不是 $p_{\mathrm{prior}}(z)$ 进行重建,因此在推理期间切换到从 $p_{\mathrm{prior}}(z)$ 进行重建将相当于从训练中脱离分布。但实际上,这种不匹配是一个功能而不是一个错误。实践表明,流模型和扩散模型通常比用于实现 VAE 解码器的卷积堆栈能力更强,因此将一些生成复杂性转移给潜在生成式模型是有意义的。我们稍后会在讨论中回到这一点。此外,超出了这些注释的范围,扩散和流动模型的变分公式将这些建模族本身实现为 VAE。
证据下限。经过适当的重新排列,方程(132)中的项可以呈现各种互补的观点。一是所谓的证据下限,我们提取如下。观察对于固定 x
$$ \mathbb {E} _ {z \sim q _ {\phi} (z | x)} \left[ \log \left(\frac {q _ {\phi} (z \mid x)}{p _ {\theta} (x \mid z) p _ {\text { prior}} (z)}\right) \right] = \mathbb {E} _ {z \sim q _ {\phi} (z | x)} \left[ \log \left(\frac {q _ {\phi} (z \mid x)}{p _ {\theta} (z \mid x)}\right) \right] - \log p _ {\theta} (x) \tag {142} $$
$$ = D _ {\mathrm{KL}} \left(q _ {\phi} (z \mid x) \| p _ {\theta} (z \mid x)\right) - \log p _ {\theta} (x) $$
第一个等式是从哪里获得的
$$ p _ {\theta} (z \mid x) = \frac {p _ {\theta} (x \mid z) p _ {\mathrm{prior}} (z)}{p _ {\theta} (x)}. $$
因此,我们可以重新排列方程(142)以获得
$$ \mathbb {E} _ {z \sim q _ {\phi} (z | x)} \left[ \log \left(\frac {p _ {\theta} (x \mid z) p _ {\text { prior }} (z)}{q _ {\phi} (z \mid x)}\right) \right] + D _ {\mathrm{KL}} (q _ {\phi} (z \mid x) \| p _ {\theta} (z \mid x)) = \log p _ {\theta} (x), \tag {143} $$
由此可见
$$ \underbrace {\mathbb {E} _ {z \sim q _ {\phi} (z | x)} \left[ \log \left(\frac {p _ {\theta} (x \mid z) p _ {\text { prior }} (z)}{q _ {\phi} (z \mid x)}\right) \right]} _ {\triangleq \operatorname{ELBO} (x; \phi , \theta)} \leq \underbrace {\log p _ {\theta} (x)} _ {\text { evidence }}. \tag {144} $$
因此,左侧通常称为证据下界,或 ELBO。我们现在可以根据 ELBO 重写方程 (136) 中的 $L_{VAE}$
$$ \begin{array}{l} \mathcal {L} _ {\mathrm{VAE}} = D _ {\mathrm{KL}} (q _ {\phi} (x, z) \parallel p _ {\theta} (x, z)) + \mathrm{const} \\ = \mathbb {E} _ {x \sim p _ {\mathrm{data}}} \mathbb {E} _ {z \sim q _ {\phi} (z | x)} \left[ \log \left(\frac {p _ {\mathrm{data}} (x) q _ {\phi} (z \mid x)}{p _ {\theta} (x \mid z) p _ {\mathrm{prior}} (z)}\right) \right] + \mathrm{const} \\ = \mathbb {E} _ {x \sim p _ {\text { data }}} [ \log p _ {\text { data }} (x) - \operatorname{ELBO} (x; \phi , \theta) ] + \text { const } \tag {145} \\ = - \mathbb {E} _ {x \sim p _ {\mathrm{data}}} \left[ \operatorname{ELBO} (x; \phi , \theta) \right] \underbrace {- H (p _ {\mathrm{data}}) + \operatorname{const}} _ {\text {const}} \\ = - \mathbb {E} _ {x \sim p _ {\mathrm{data}}} [ \mathrm{ELBO} (x; \phi , \theta) ] + \mathrm{const} \\ \end{array} $$
因此最初的 VAE 目标可以被视为简单地试图最大化预期的 ELBO。最后,让我们考虑一下在我们完美训练 VAE 的情况下会发生什么。
备注 42(当 $q_{\phi}(x,z) \approx p_{\theta}(x,z)$ 时会发生什么)?
首先,请注意,用于训练潜在生成式模型的采样分布由边际给出
$$ q _ {\phi} (z) = \int_ {x} q _ {\phi} (z | x) p _ {\mathrm{data}} (x) \mathrm{d} x. $$
如果 $q_{\phi}(x,z) = p_{\theta}(x,z)$ ,那么特别是
$$ q _ {\phi} (z) = p _ {\theta} (z) = p _ {\mathrm{prior}} (z). $$
因此,$q_{\phi}(x,z) \approx p_{\theta}(x,z)$ 意味着潜在采样分布的正则化。其次,$q_{\phi}(x,z) \approx p_{\theta}(x,z)$ 意味着变分近似 $p_{\theta}(x \mid z) \approx q_{\phi}(x \mid z)$ 是好的,进而意味着低重建误差。
备注 43(VAE 有什么变化?)
为什么我们不能简单地采用 $q_{\phi}(\cdot \mid x) = p_{\theta}(\cdot \mid x)$ ,从而保证 $q_{\phi}(x,z) = p_{\theta}(x,z) = 0$ ?原因是,虽然我们知道可能性 $p_{\theta}(x \mid z)$ ,但后验概率
$$ p _ {\theta} (z \mid x) = \frac {p _ {\theta} (x \mid z) p _ {\mathrm{prior}} (z)}{p _ {\theta} (x)} $$
通常很棘手,因为我们无法获得 $p_{\theta}(x)$ 的可能性。因此,VAE 中变分的存在是由于 $q_{\phi}(\cdot \mid x)$ 作为棘手的后验 $p_{\theta}(\cdot \mid x)$ 的替代品或变分近似。
重建与一代。给定一个编码器 $q_{\phi}(z|x)$ , 解码器 $p_{\theta}(x|z)$ ,和潜在生成式模型 $r_{\psi}$ 训练样本 $q_{\phi}(z)$ ,我们可以考虑以下两种生成式模型
$$ r _ {\psi , \theta} ^ {\mathrm{recon}} (x _ {\mathrm{out}}) = \int_ {z, x _ {\mathrm{in}}} p _ {\theta} (x _ {\mathrm{out}} \mid z) q _ {\phi} (z \mid x _ {\mathrm{data}}) p _ {\mathrm{data}} (x _ {\mathrm{data}}) \mathrm{d} z \mathrm{d} x _ {\mathrm{in}} \qquad \mathrm{(reconstruction~sampler)} $$
$$ r _ {\psi , \phi} ^ {\mathrm{gen}} (x _ {\mathrm{out}}) = \int_ {z _ {\mathrm{gen}}} p _ {\theta} (x _ {\mathrm{out}} | z _ {\mathrm{gen}}) r _ {\psi} (z _ {\mathrm{gen}}) \mathrm{d} z _ {\mathrm{gen}} \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \qquad \mathrm{(generativesampler)} $$
换句话说,重建采样器从 $x_{data} \in p_{data}$ 开始编码到 z,并解码到 $x_{out}$ ,而生成采样器从生成式模型的 $z_{gen} \in r_{\psi}$ 开始,然后通过解码器。通过计算两个采样器分布到 $p_{data}$ 的 Fréchet 起始距离,我们获得了重建 FID (rFID) 和生成 FID (gFID)。人们还可以考虑通过平均失真(重建的均方根误差)来测量重建采样器的质量,尽管这样的度量对于生成采样器没有意义。事实证明,重建采样器的质量和生成采样器的质量之间存在天然的张力。低 rFID(高质量重建采样器)通常表明潜在信息丢失较少,因此潜在分布 $q_{\phi}(z)$ 在很大程度上类似于 $p_{data}$ ,因此学习潜在生成式模型的任务可能会更加困难,从而提高 gFID。相反,高 rFID 通常表示高信息丢失,并且更容易学习潜在分布 $q_{\phi}(z)$,从而降低 gFID。这种现象如图 22 所示。
劳动分工。重建生成采样器的权衡迫使我们考虑如何在自编码器和潜在生成式模型 $r_{\psi}$ 之间分配信息丢失。直观地, $r_{\psi}$ 通过一些学习向量场 $u_{t}^{\psi}(z_{t})$ ,将标准高斯传输到 $q_{\phi}(z) \approx p_{\mathrm{prior}}$ ,之后解码器 $p_{\theta}(x|z)$ 将 $q_{\phi}(z)$ 传输到 $p_{data}$ 。现在让我们(不精确地)将速率定义为潜在分布 $q_{\phi}(z)$ 与 $p_{\mathrm{prior}}(z)$ 匹配的程度,并通过扩展,将生成任务委托给潜在生成式模型的程度。 $^{5}$ 这种分工可以通过绘制速率和失真之间的帕累托边界来可视化,如图 22 所示。特别是,当速率高时,失真低,反之亦然,这为前面关于重建与生成采样器质量的讨论提供了第二种视角。我们通过以下见解来结束我们的讨论。
直觉44(分工)
图 22 的关键见解是,帕累托边界的“膝盖”处存在最佳的劳动分工,此时我们获得低速率(高压缩!)而没有高失真。换句话说,这样的点对应于压缩级别,该压缩级别同时降低了训练底层生成式模型的难度,同时保留了合理的重建质量。
E 扩散模型文献指南
文献中有一整套围绕扩散模型和流匹配的模型。当您阅读这些论文时,您可能会发现呈现本课程材料的不同(但等效)方式。这使得阅读这些论文有时会有点令人困惑。因此,我们想简要概述各种框架及其差异,并将它们放在历史背景中。这对于理解本文档的其余部分不是必需的,而是为了在您阅读文献时为您提供支持。
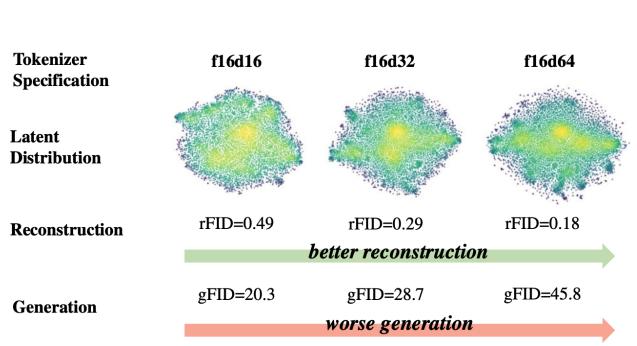
离散时间与连续时间。第一篇去噪扩散模型论文 $[41, 42, 17]$ 没有使用 SDE,而是在离散时间上构造马尔可夫链,即时间步长 $t = 0, 1, 2, 3, \ldots$ 。迄今为止,您会在文献中发现很多使用这种离散时间公式的作品。虽然这种结构因其简单性而颇具吸引力,但时间离散方法的缺点是它迫使您在训练之前选择时间离散化。此外,损失函数需要通过证据下界(ELBO)来近似 - 顾名思义,这只是我们实际想要最小化的损失的下界。后来,宋等人。 $[45]$ 表明这些构造本质上是时间连续 SDE 的近似。此外,在连续时间情况下,ELBO 损失变得严格(即它不再是下界)(例如,请注意定理 12 和定理 22 是等式而不是下界 - 这在离散时间情况下会有所不同)。这使得 SDE 结构变得流行,因为它在数学上被认为是“更干净的”,并且可以通过 ODE/SDE 采样器进行训练后控制模拟误差。但值得注意的是,这两种模型都采用相同的损失,并没有本质上的不同。
“正向过程”与概率路径。第一波去噪扩散模型 [41, 42, 17, 45] 没有使用术语概率路径,而是通过所谓的前向过程构建了数据点 $z \in \mathbb{R}^d$ 的噪声过程。这是以下形式的 SDE
$$ \bar {X} _ {0} = z, \quad \mathrm{d} \bar {X} _ {t} = u _ {t} ^ {\text { forw }} (\bar {X} _ {t}) \mathrm{d} t + \sigma_ {t} ^ {\text { forw }} \mathrm{d} \bar {W} _ {t} \tag {146} $$
这个想法是在绘制数据点之后 $z \sim p_{data}$ 一种方法是模拟前向过程,从而破坏或“干扰”数据。前向过程的设计使得 $t \to \infty$ 其分布收敛于高斯分布 $\mathcal{N}(0, I_d)$ 。换句话说,对于 $T \gg 0$ 它认为 $\bar{X}_T \sim \mathcal{N}(0, I_d)$ 大约。请注意,这本质上对应于概率路径: $\bar{X}_t$ 给定 $\bar{X}_0 = z$ 是条件概率路径 $\bar{p}_t(\cdot | z)$ 和分布 $\bar{X}_t$ 被边缘化 $z \sim p_{data}$ 对应于边缘概率路径 $\bar{p}_t$ .⁶ 但是,请注意,通过这种构造,我们需要知道 $X_t | X_0 = z$ 以封闭形式来训练我们的模型以避免模拟 SDE。这本质上限制了向量场 $u_t^{forw}$ 到那些我们知道分布的 $\bar{X}_t | \bar{X}_0 = z$ 以封闭形式。因此,在整个扩散模型文献中,前向过程中的矢量场始终是仿射形式,即 $u_t^{forw}(x) = a_t x$ 对于某些连续函数 $a_t$ 。对于这种选择,我们可以使用条件分布的已知公式 [40, 44, 23]:
$$ \bar {X} _ {t} | \bar {X} _ {0} = z \sim \mathcal {N} (\alpha_ {t} z, \beta_ {t} ^ {2} I), \quad \alpha_ {t} = \exp \left(\int_ {0} ^ {t} a _ {r} \mathrm{d} r\right), \quad \beta_ {t} ^ {2} = \alpha_ {t} ^ {2} \int_ {0} ^ {t} \frac {(\sigma_ {r} ^ {\mathrm{forw}}) ^ {2}}{\alpha_ {r} ^ {2}} d r $$
请注意,这些只是高斯概率路径。因此,可以说前向过程是构建(高斯)概率路径的一种特定方式。流匹配 $[25]$ 引入了术语概率路径,以简化构造并同时使其更加通用:首先,扩散模型的“前向过程”从未被实际模拟(仅在训练期间抽取 $\bar{p}_{t}(\cdot|z)$ 中的样本)。其次,前向过程仅在 $t \to \infty$ 内收敛(即我们永远不会在有限时间内到达 $p_{init}$)。因此,我们在本文档中选择使用概率路径。
时间反转与求解福克-普朗克方程。扩散模型的原始描述并没有通过 Fokker-Planck 方程(或连续性方程)构建训练目标 $u_{t}^{target}$ 或 $\nabla \log p_{t}$ ,而是通过前向过程 [2] 的时间反转。时间反转 $(X_{t})_{0 \leq t \leq T}$ 是在时间反转的轨迹上具有相同分布的 SDE,即
$$ \mathbb {P} \left[ \bar {X} _ {t _ {1}} \in A _ {1}, \dots , \bar {X} _ {t _ {n}} \in A _ {n} \right] = \mathbb {P} \left[ X _ {T - t _ {1}} \in A _ {1}, \dots , X _ {T - t _ {n}} \in A _ {n} \right] \tag {147} $$
$$ \text { for all } 0 \leq t _ {1}, \dots , t _ {n} \leq T, \text { and } A _ {1}, \dots , A _ {n} \subset S \tag {148} $$
如Anderson [2]所示,通过SDE可以获得满足上述条件的时间反转:
$$ \mathrm{d} X _ {t} = \left[ - u _ {t} (X _ {t}) + \sigma_ {t} ^ {2} \nabla \log p _ {t} (X _ {t}) \right] \mathrm{d} t + \sigma_ {t} \mathrm{d} W _ {t}, \quad u _ {t} (x) = u _ {T - t} ^ {\mathrm{forw}} (x), \sigma_ {t} = \bar {\sigma} _ {T - t} $$
作为 $u_{t}(X_{t}) = a_{t}X_{t}$ ,上面对应于我们在命题 1 中导出的训练目标的特定实例(这并不是立即微不足道的,因为使用了不同的时间约定。参见例如 [26] 的推导)。然而,出于生成式建模的目的,我们通常只使用马尔可夫过程的最后一个点 $X_{1}$ (例如,作为生成的图像)并丢弃较早的时间点。因此,马尔可夫过程是“真正的”时间反转还是遵循概率路径对于许多应用来说并不重要。因此,使用时间反转是没有必要的,并且通常会导致次优结果,例如概率流 ODE 通常更好 [23, 28]。所有不同于时间反转的扩散模型采样方法都再次依赖于福克-普朗克方程的使用。我们希望这能够说明为什么现在许多人直接通过
Fokker-Planck 方程 - 由 [25, 27, 1] 首创并在本课程中完成。
流匹配 [25] 和随机插值 [1]。我们提出的框架与流匹配和随机插值(SI)的框架关系最密切。正如我们所知,流匹配仅限于流。事实上,流匹配的关键创新之一是表明不需要通过前向过程和 SDE 进行构建,而是可以以可扩展的方式单独训练流模型。由于此限制,您应该记住,从流匹配模型中采样将是确定性的(只有初始 $X_0 \sim p_{\mathrm{init}}$ 是随机的)。随机插值包括纯流和通过我们此处使用的“Langevin 动力学”进行的 SDE 扩展(参见定理 17)。随机插值函数得名于插值函数 $I(t,x,z)$ ,该函数旨在在两个分布之间进行插值。在我们这里使用的术语中,这对应于构造条件和边缘概率路径的不同但(主要)等效的方法。流匹配和随机插值相对于扩散模型的优点在于它们的简单性和通用性:它们的训练框架非常简单,但同时它们允许您从任意分布 $p_{\mathrm{init}}$ 到任意分布 $p_{\mathrm{data}}$ - 而去噪扩散模型仅适用于高斯初始分布和高斯概率路径。这为生成式建模开辟了新的可能性,我们将在本课程后面简要介绍。
摘要 45(替代扩散配方)
文献中流行的扩散模型的替代公式通常涉及以下元素的某种组合:
- 离散时间:经常使用通过离散时间马尔可夫链的 SDE 近似。
- 倒置时间约定:通常使用倒置时间约定,其中 t = 0 对应于 $p_{data}$ (与此处相反,其中 t = 0 对应于 $p_{init}$ ).
- 前向过程:前向过程(或噪声过程)是构建(高斯)概率路径的方法。
- 通过时间反转的训练目标:还可以通过 SDE 的时间反转来构建训练目标。这是此处介绍的构造的特定实例(具有倒置时间约定)。